




CloudberryDB | 第1期 | 向量化引擎解读
GreenPlum闭源带来了挑战,CloudberryDB接棒GreenPlum继续前行。CloudberryDB向量化引擎有开源计划,8月3号社区首期线下沙龙对向量化引擎从4个方面进行了介绍:

首先是OLAP性能优化点有哪些:编译执行、向量化执行和并行。
1)其中编译执行:将复杂运算在执行前编译成一个函数,优点有:分支预测代价低,执行速度快(因为在执行时编译可以获取当前执行的数据,根据当前执行的数据比如它的数据类型,进入指定分支,这样仅编译当前指定分支去执行);实现比较复杂,商业或者开源数据库中常见的实现方式借助LLVM,只适合表达式计算;缺点是有额外的运行时编译代价
2)并行执行,利用多线程或者多进程加速:实现相对简单,性能提升明显;当然引入后就需要考虑进程/线程之间同步问题;利用资源换时间,资源消耗倍率大于加速比。PgSQL中实现了并行执行,借助Gather算子汇聚各个进程的输出,CloudberryDB也实现了并行执行,只不过它需要使用PG优化器,ORCA优化器不支持并行执行计划生成。实现的并行算子有查询执行算子、HashJoin和存储引擎的并行化扫描
3)向量化执行:优点有:运算的函数调用次数减少,数据局部性比较好、cache命中率更高,编译器的代码优化,利用SIMD指令加速。当然由于单次执行处理的数据多,内存使用会更高:

CloudberryDB的向量化实现的内容包括:实现算子包括扫描、聚合、排序和motion

当前实现的向量化引擎基于火山模型,另从PostgreSQL技术大会的分享稿看,CloudberryDB也在开发push-based pipeline执行引擎。
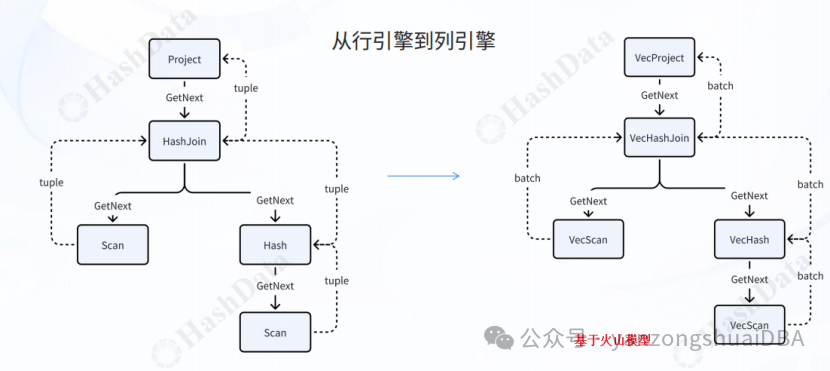
这里主要关注下Motion的向量化优化:

这里的固定时间指的是什么?它的方案目标是增加发送batch的大小,有2个方案:1)由于当前slice有过滤、聚合等操作,从顺序扫描得到的batch有1000行,经过过滤和聚合等操作后,行数会大大减少,若batch的行数累计到足够行才发送,会造成父slice运算不及时,相当于中断了流水线,性能估计不是很好;2)把同一个机器上的batch合并后发送,多了一次序列化,运算量增多,当然网络流量会增加:这里同一个机器上batch指什么?同一个机器上的segment选举出一个leader,然后segment的数据都汇聚到它,最后再合并成一个batch进行发送?同样会有中断流水线的情况。3)同一个机器的segment间使用线程并行,内部发送合并不需要序列化:内部发送可以使用共享内存,也就不再需要序列化和反序列化了,不过这里就需要识别出哪些是同一个segment上的实例,并且发送对象哪些才是同一个segment

向量化和并行执行结合:讲解了3个算子:Aggregate、HashJoin、Sort:
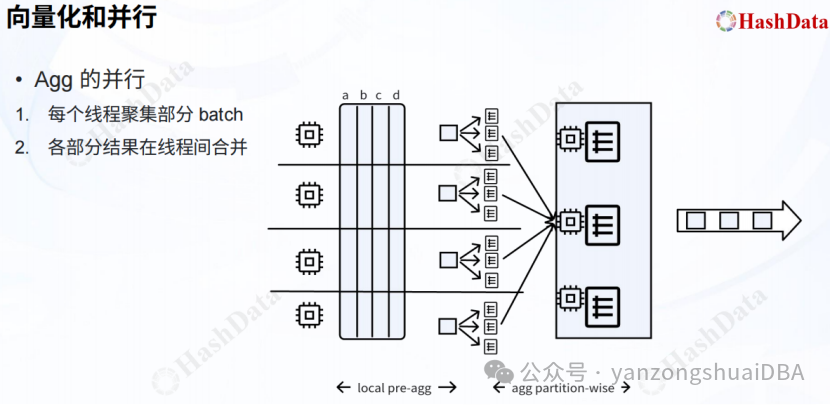
Agg执行的进程内再调整多个线程进行聚合,每个线程针对一部分数据进行聚合,然后再将各自结果在线程间进行合并。线程间合并的机制是啥?图中agg partition-wise有多个聚合组,最终再合并一次?
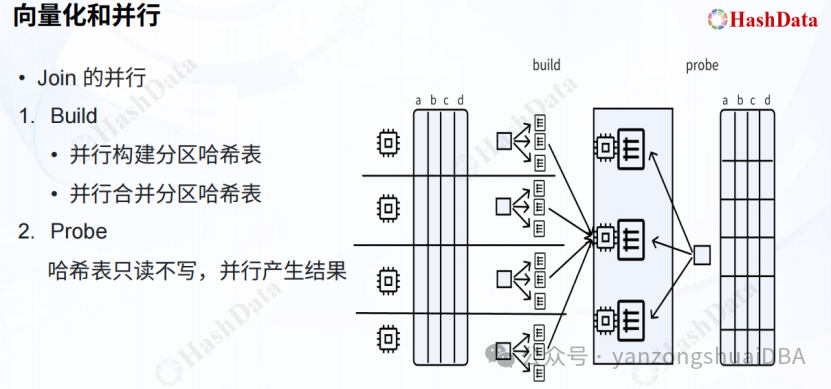
Hash表的构建通过多线程进行构建,然后将各个线程生成的hash表合并,怎么合并的?探测端针对多个hash表进行并行探测?
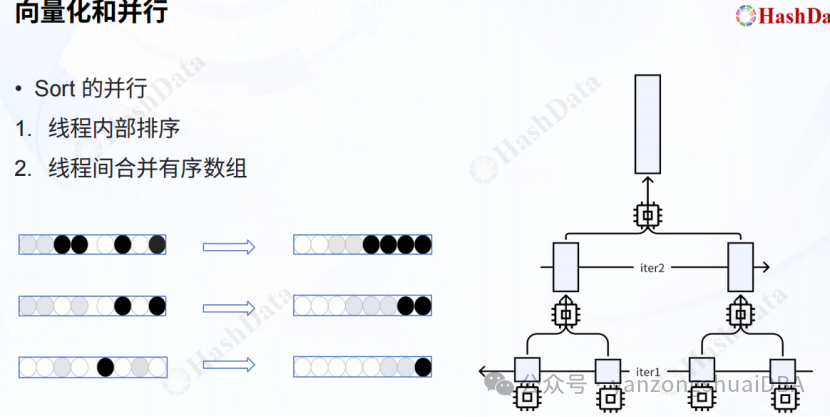
多个线程内部先进行排序,然后线程间进行合并,类似归并排序。

未来:对优化器进行适配,将向量化算子的代价评估带入评价机制;push-baseed pipeline执行器、对向量化查询信息进行收集;以及更过算子和并行的支持
