本文将介绍 TencentOS 内核团队与数据库内核团队合作使用的一系列技术,这些技术的使用在原有架构上提升了 30%的性能,降低内存占用 15%,也在不需更换底层架构的情况下完成了优化。
从物理机转向云原生的挑战
对于物理机形态,由于使用了云原生构建的服务(采用云盘),所以在存储点查性能以及 IO 性能上存在天然的瓶颈;
相对物理机更小的 node 规格,对各个数据库节点的内存使用和分配策略不能照搬物理机策略,此时产生了挑战;
云盘 IO 的挑战
1、数据在磁盘上会写入两次,占用磁盘带宽*2,造成性能负担。
2、这两次写入的磁盘地址大概率并不连续,造成性能抖动。
二、原子写方案介绍
详见:
https://lwn.net/Articles/933015/
XFS atomic write support:
相关功能:
https://gitee.com/anolis/storage-cloud-kernel
相关功能:
https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=3db1de0e582c358dd013f3703cd55b5fe4076436
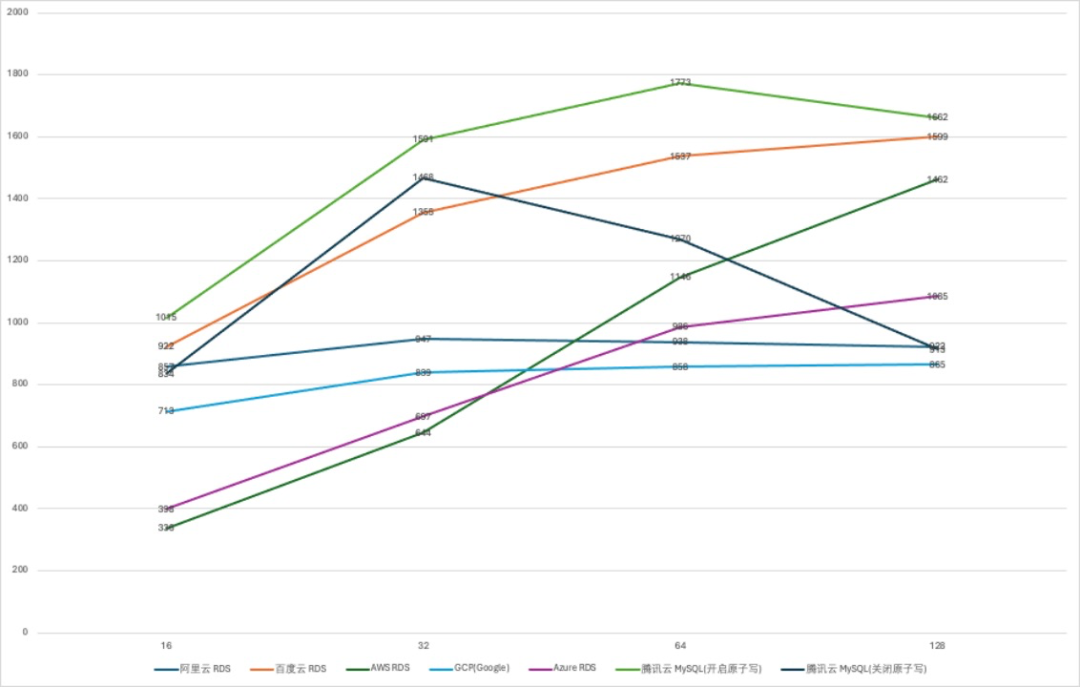

规格选择为中等规格 4vCPU 16GB 内存/100GB 存储。主要考虑是,一方面是改规格为核心业务使用的起步规格,另外,4vCPU 规格的实例数为现网实例总数的42.64%,更具代表性。 对比测试方法使用 sysbench 的读写混合模型(oltp_read_write)进行测试,单表大小为 100 万,共十个表,单次测试时长为 300 秒,分别测试了如下并发度的性能表现:16、32、64、128。 写入对比测试使用 sysbench 的只写模型(oltp_write_only)进行测试,单表大小为 100 万,共十个表,单次测试时长为 300 秒,分别测试了如下的并发度的性能表现:32、64、128、256。
三、小规格的资源冗余挑战
场景\模型 | |||||
2.4960% | -1.3831% | 0.8714% | |||
内存场景 | -2.0108% | -0.9624% | -0.4278% | -1.5733% | -1.2540% |
与未开启「悟净」内存压缩能力在4c16g 规格下性能对比,性能波动在 3% 以内
四、性能增强特性与技术原理
代码段大页 | sysbench多并发场景QPS提升 8% |
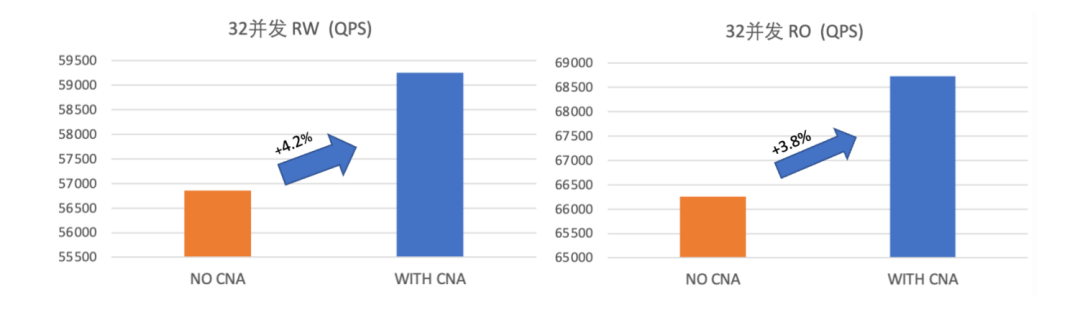
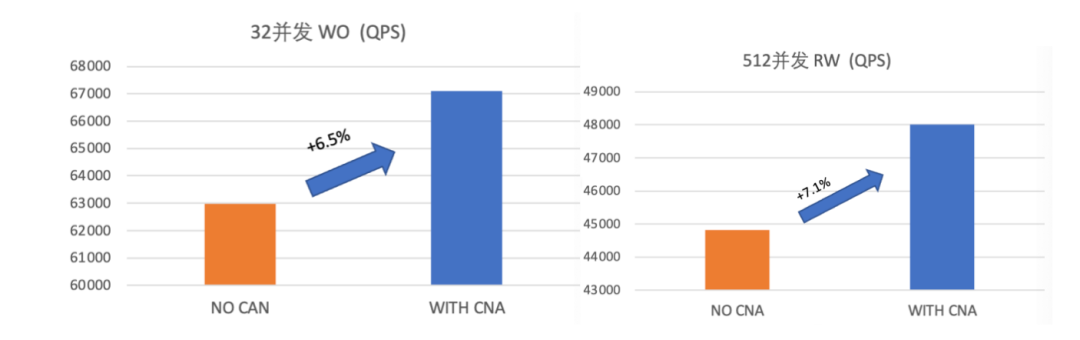
numa-aware spinlock | sysbench 低并发场景 QPS 提升 5%,高并发场景提升 7% |
投机性缺页异常-SPF | 数据库预热时间(QPS 从 0 到峰值)优化 30%-50% 耗时 |
ORC unwinder优化 | sysbench 多并发场景 QPS 提升 5% |
1、代码段大页优化
在方案设计中,我们考虑了透明大页和标准大页两种方案,下面介绍其各自优劣。
1、透明大页 THP(Transparent Huge Pages):是动态可生成的,不用预留,即用即申即可,但是透明大页不是必定就能合成成功的,首先需要唤醒 khugepage 去执行,后面申请连续的 4k page,达到 2M,才能满足要求,此外对于大内存耗用的业务场景,存在申请连续 2M 内存失败的风险。
2、标准大页(HUGETLB):采用标准大页,需要预留,一当预留成功后,不用考虑申请失败的问题,但是缺点也明显,标准大页由于需要先预留后才能使用,并且预留部分无法被其他业务使用,存在通用性差的问题,此外预留意味着束缚,预留多了,导致浪费,预留少了,大页使用不足。
通过以上分析,并结合数据库业务情况,我们最终决策采用透明大页的方案,此外还针对这部分做了部分优化,整体设计框图如下图所示:
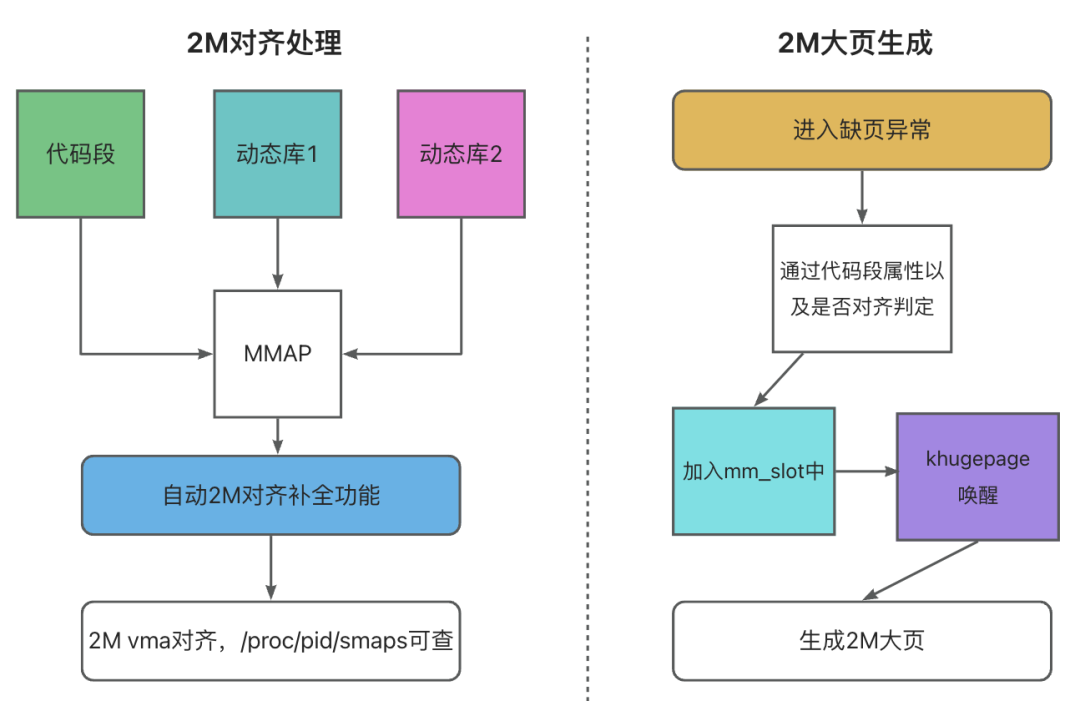
在代码开发过程中,我们会在 VMA 创建过程中,对非首地址对齐的区间进行优化,此外还会针对部分略微少于 2M 的区间,进行自动补全,这样保证了代码段部分尽可能合并成大页,还增加细粒度开关,控制生成代码段大页的合成范围。
代码段大页优化结果

32&512并发只读优化结果
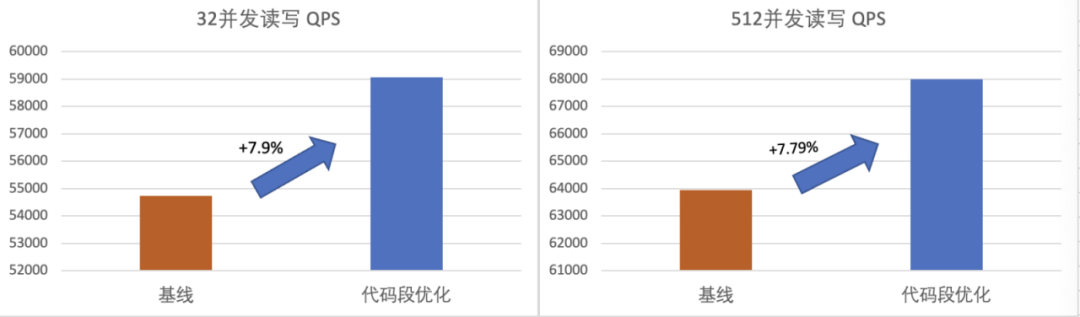
32&512 并发读写优化结果
2、NUMA-aware qspinlocks
内核中现有「qspinlock」实现是基于 MCS lock 实现,也称之为锁队列机制,它会将系统中所有在等待这个锁的 CPU 排成队(queue),并且用链表来管理,该方案优势非常明显,即不用过多担心 cache miss 导致的性能波动问题,每一个 CPU 都只会维护与自己相关的锁队列结构体,并且只有当前锁释放后,才能更新本地的标志值,让其他 CPU 去获取该锁。
采用 MCS 锁的优势主要在通过 per-cpu 方式维护的锁队列,消除了cache-line跳来跳去导致的程序性能波动问题,此外,还存在一定的公平性,通过队列机制,确保每一个 CPU 都能成功获取锁。但是在非一致性内存访问(NUMA,non-uniform memory-access)系统平台上还存在进一步优化空间,该平台通常包含多个NUMA节点(统称为node),每个节点下管理着多个 CPU,访问那些连接到本 CPU节点的内存,比起连接到其他节点的内存速度更快。
当然,无论内存连接在哪个节点上,对 cache 的访问都是(相对)最快的,但是在基于 NUMA 节点之间移动 cache line 的动作开销很大,远差于同一节点上的 CPU 之间发生 cache line 来回跳动的情况。
例如下图所示,msc spinlock 维护 CPU 队列是基于 NUMA 交叉方式保存的,这就导致每一次选择下一个 CPU 时,都发生 cache line 跨 NUMA 跳动的情况,导致性能波动,此外 spinlock 中通常用于保护数据结构,所以当 CPU 之前争抢锁的目的是为了访问同一个数据结构时,就会发生连锁效应,导致数据结构也发生 cache line 跨 NUMA 跳动的情况,这样对系统性能会造成更大的伤害。
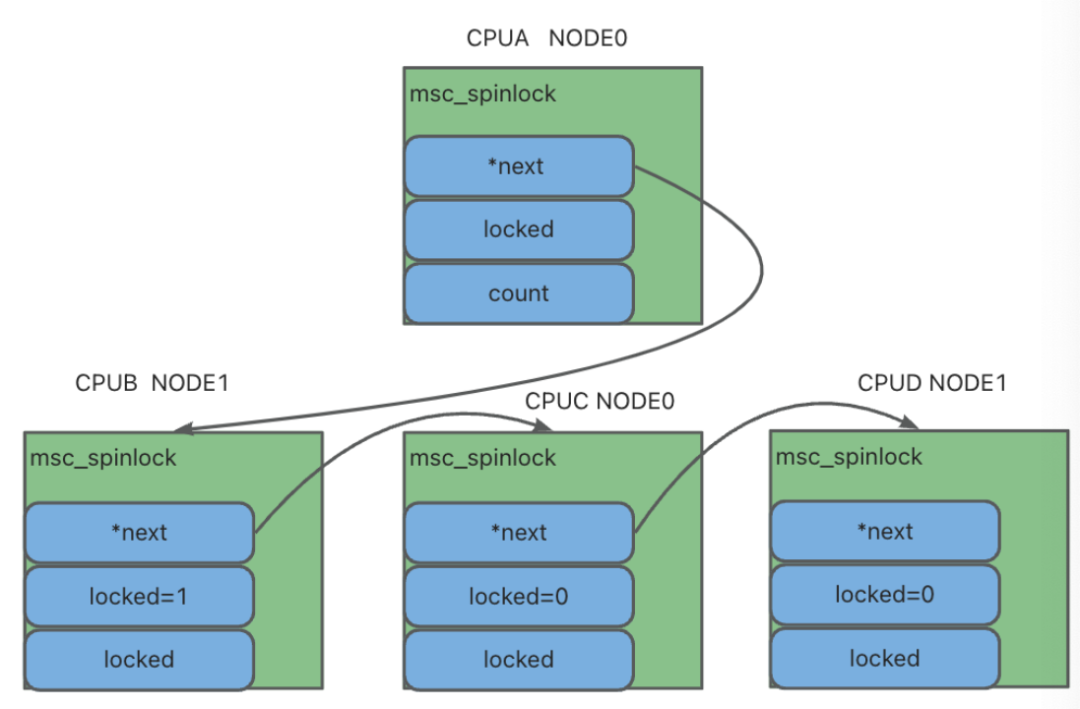
MSC spinlock处理流程
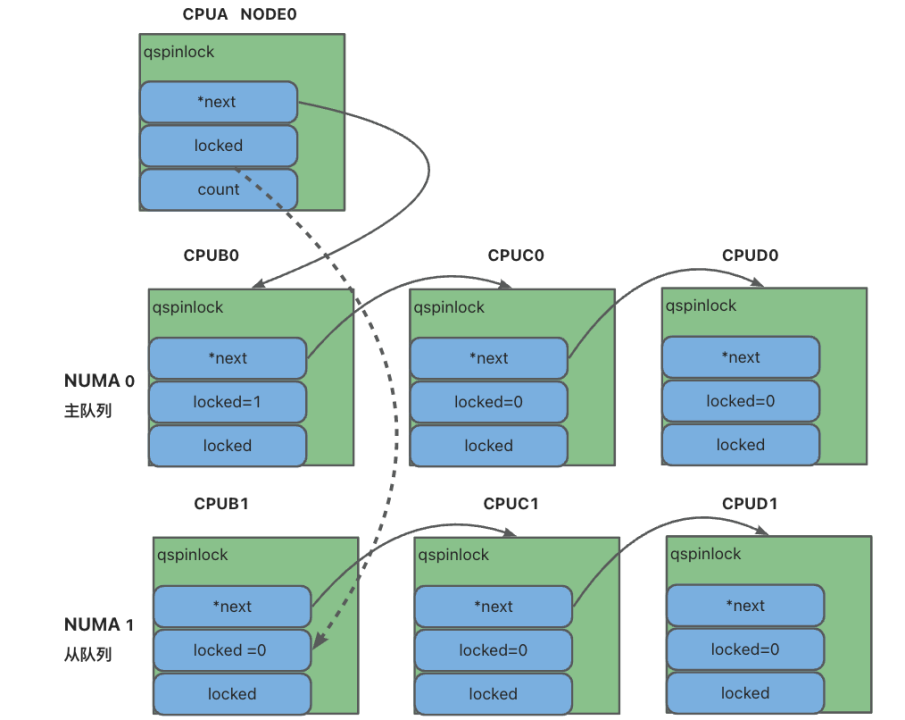
NUMA-aware qspinlocks 处理逻辑
NUMA-aware 性能优化结果
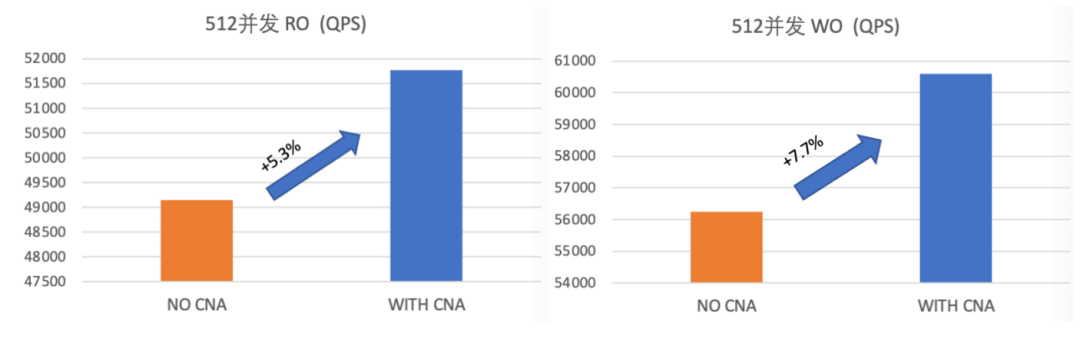
3、投机性缺页异常-SPF
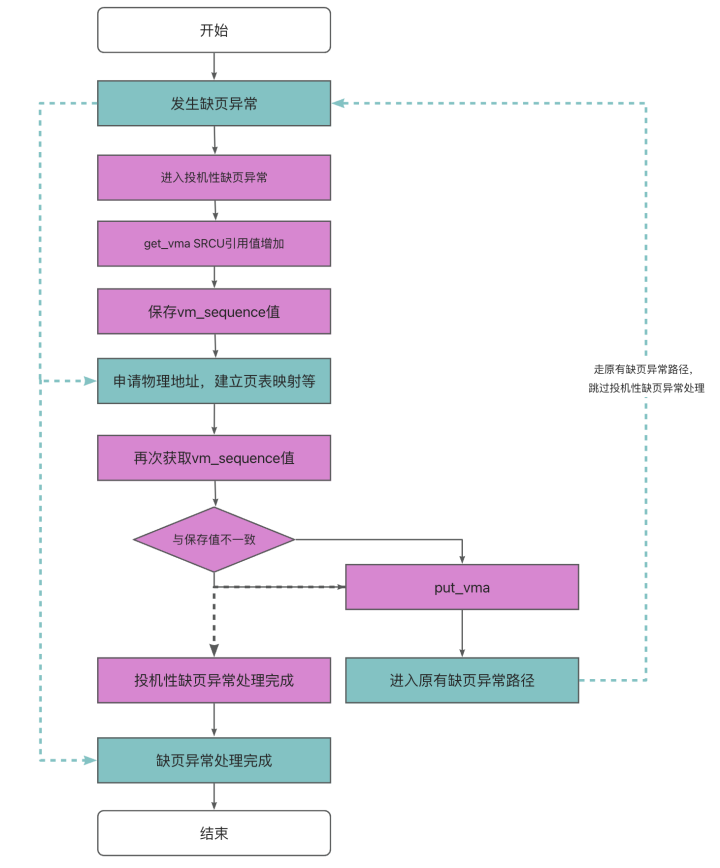
投机性缺页异常处理流程
4、ORC Unwinder
长期以来, Stacktrace 是依赖 DWARF Unwinder 实现的。DWARF Unwinder 利用调试信息(Debuginfo)来解析函数调用栈,在这个过程中,Frame Pointer 起到了至关重要的作用。Frame Pointer 是一个预留寄存器,用于存储当前函数的栈帧基址。
在 x86_64 体系结构中,通常使用 RBP 寄存器来实现。当一个函数被调用时,RBP 寄存器首先被更新为当前栈帧的基址,旧的 RBP 被存于栈顶,而函数返回时,执行出栈并将 RBP 寄存器恢复为之前的值,从而 DWARF Unwinder 借助 RBP 信息即可正确地、链式地回溯函数的栈帧,并根据调试信息计算出当前函数的参数、局部变量和返回地址等信息,从而生成 Stacktrace 信息。
然而,这种做法会导致寄存器资源的浪费,特别是在寄存器资源紧张的架构(如 x86_64)中,固定的入栈出栈也增加了函数的运行开销。而 ORC Unwinder 就是为了解决这个问题的。
在 x86_64体系结构中,ORC Unwinder 重新设计了编译时生成的相关调试信息的格式,仅使用 RIP-relative 地址即可获取调用栈回溯过程中所需的信息。这意味着在运行时,只需要依赖 RIP 寄存器信息,就可以访问调用栈中的所有信息,并通过事先计算且经过验证的信息找出上一级栈帧,从而避免使用额外的寄存器,也避免了频繁入栈出栈。ORC Unwinder 可以显著提高运行时的性能,特别是在寄存器资源紧张的架构(如 x86_64)中,这一优势更为明显。
五、总结与展望
关于 TencentOS