




《福布斯》最近将 RAG 应用程序评为人工智能领域最热门的事物。这并不奇怪,因为检索增强生成需要最少的代码,并有助于建立用户对大语言模型的信任。构建出色的 RAG 应用程序或聊天机器人时面临的挑战是处理结构化文本和非结构化文本。
非结构化文本(可能被分块或嵌入)可以轻松地输入到 RAG 工作流程中,但其他数据源需要更多准备工作才能确保准确性和相关性。在这些情况下,您可以创建架构的每日快照,然后将其转换为大语言模型能够理解的文本。然而,这是另一种方式——知识图谱可以在单个数据库中存储结构化和非结构化文本,从而减少为大语言模型提供所需信息所需的工作。
在本博客中,我们将查看一个使用知识图谱创建聊天机器人来回答有关微服务架构、正在进行的任务等问题的示例。
什么是知识图谱?
知识图谱捕获有关领域或业务中的数据点或实体以及它们之间的关系的信息。数据被描述为知识图谱中的节点和关系。
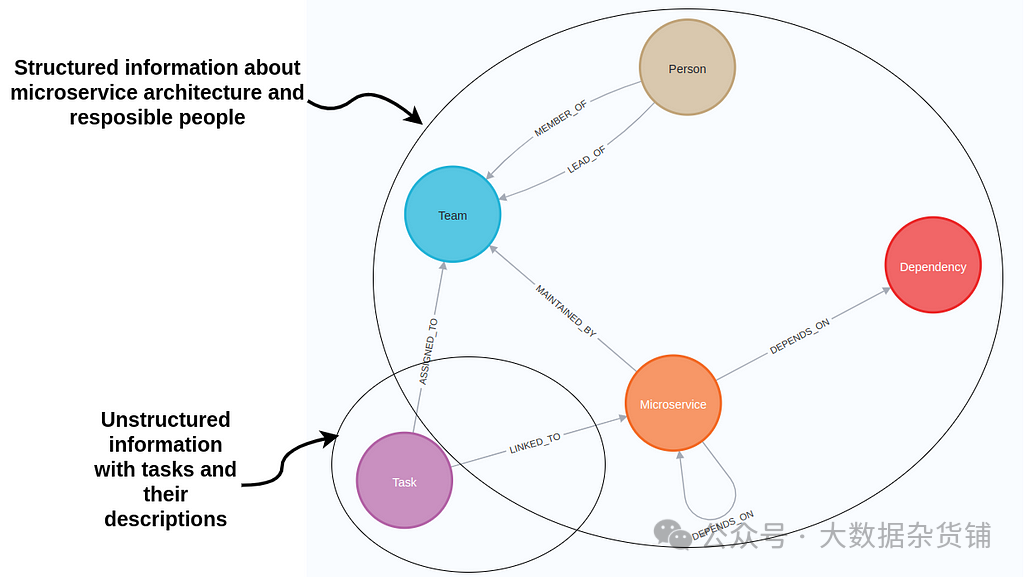
知识图谱模式表示微服务架构和他们的任务
1节点表示数据点或实体,例如人员、组织和位置。在微服务图示例中,节点描述人员、团队、微服务和任务。
1关系用于定义这些实体之间的连接,例如微服务或任务所有者之间的依赖关系。
节点和关系都可以将属性值存储为键值对。
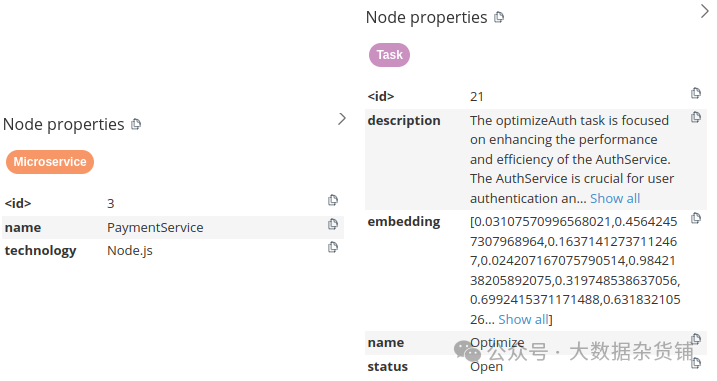
微服务和任务节点的节点属性
微服务节点有两个节点属性:名称和技术。任务节点更复杂:它们具有名称、状态、描述和嵌入属性。
通过将文本嵌入值存储为节点属性,您可以对任务描述执行向量相似性搜索,就像任务存储在向量数据库中一样。
接下来,我们将演练一个场景,展示如何使用 LangChain 实现基于知识图谱的 RAG 应用程序来支持您的 DevOps 团队。该代码可在 GitHub 上获取。
Neo4j 环境设置
首先,您需要设置一个 Neo4j 5.11 实例或更高版本,以便按照示例进行操作。最简单的方法是在 Neo4j Aura 上启动 Neo4j 数据库的免费云实例。您也可以通过下载 Neo4j Desktop 应用程序并创建本地数据库实例来设置 Neo4j 数据库的本地实例,同时需要安装 apoc 插件。本示例使用的本地 neo4j 环境。
Shell |
数据集
知识图谱非常擅长连接来自多个数据源的信息。开发 DevOps RAG 应用程序时,您可以从云服务、任务管理工具等获取信息。
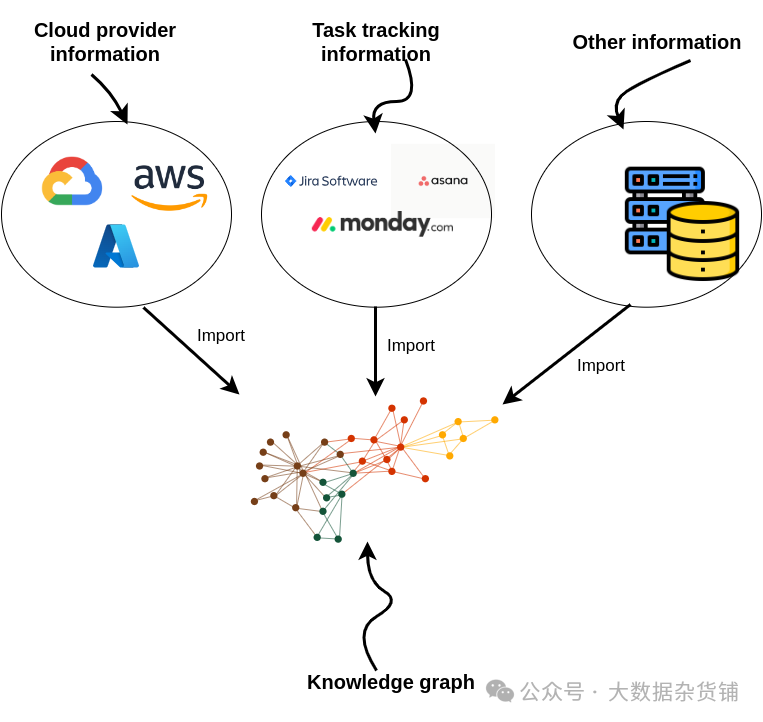
将多个数据源组合成知识图谱
由于此类微服务和任务信息不公开,因此我们创建了一个综合数据集。我们使用 ChatGPT 来帮助我们。这是一个只有 100 个节点的小型数据集,但对于本教程来说已经足够了。以下代码将示例图导入到 Neo4j 中。
Shell |
您应该在 Neo4j 浏览器中看到类似的图形可视化。
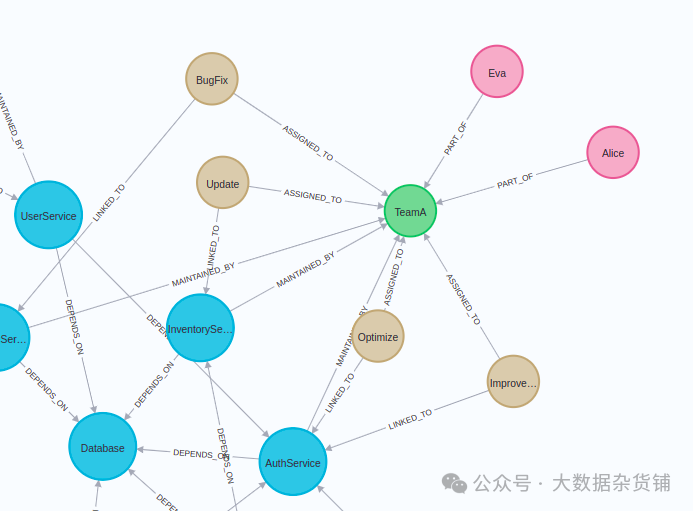
DevOps 图的子集
蓝色节点描述微服务。这些微服务可能相互依赖。这意味着一个微服务的运行或提供结果的能力可能依赖于另一个微服务的操作。
棕色节点代表直接链接到这些微服务的任务。我们的图表示例一起展示了微服务的设置方式、它们的链接任务以及与每个服务相关的团队。
Neo4j 向量索引
我们将首先实现向量索引搜索,通过名称和描述查找相关任务。如果您不熟悉向量相似性搜索,可以快速回顾一下。关键思想是根据每个任务的描述和名称计算文本嵌入值。然后,在查询时,使用余弦距离等相似性度量找到与用户输入最相似的任务。
RAG 应用程序中的矢量相似性搜索
从向量索引中检索到的信息可以用作大语言模型的上下文,以便它可以生成准确且最新的答案。
这些任务已经在我们的知识图谱中了。但是,我们必须计算嵌入值并创建向量索引。在这里,我们将使用 from_existing_graph 方法。
Shell |
在此示例中,我们为 from_existing_graph 方法使用了以下特定于图的参数。
index_name:向量索引的名称。
node_label:相关节点的节点标签。
text_node_properties:用于计算嵌入并从向量索引中检索的属性。
embedding_node_property:将嵌入值存储到哪个属性。
现在向量索引已经启动,我们可以将其用作 LangChain 中的任何其他向量索引。
Shell |
您将看到我们构造了一个映射或类似字典的字符串的响应,并在 text_node_properties 参数中定义了属性。
现在,我们可以通过将向量索引包装到 RetrievalQA 模块中来轻松创建聊天机器人响应。
Shell |
矢量索引的一个普遍限制是它们不提供聚合信息的能力,就像使用 Cypher 等结构化查询语言一样。考虑以下示例:
Shell |
这个回答似乎是有效的,部分原因是大语言模型使用自信的语言。但是,响应与从向量索引检索到的文档数量直接相关,默认情况下为 4。因此,当向量索引检索到四个未决票时,LLM 毫无疑问地认为没有其他未决票。但是,我们可以使用 Cypher 语句验证该搜索结果是否正确。
Shell |
我们的玩具图中有五个未完成的任务。向量相似性搜索非常适合筛选非结构化文本中的相关信息,但缺乏分析和聚合结构化信息的能力。使用 Neo4j,这个问题可以通过使用 Cypher(一种用于图数据库的结构化查询语言)轻松解决。
图 Cypher 搜索
Cypher 是一种结构化查询语言,旨在与图数据库交互。它提供了一种匹配模式和关系的可视化方式,并依赖于以下 ascii –art 类型的语法:
Shell |
此模式描述了一个带有标签 Person 和名称属性 Tomaz 的节点,该节点与 Slovenia 的 Country 节点具有 LIVES_IN 关系。
LangChain 的巧妙之处在于它提供了 GraphCypherQAChain,它可以为您生成 Cypher 查询,因此您无需学习 Cypher 语法即可从 Neo4j 等图形数据库中检索信息。
以下代码将刷新图模式并实例化 Cypher 链。
Shell |
生成有效的 Cypher 语句是一项复杂的任务。因此,建议使用 gpt-4 等最先进的 LLM 来生成 Cypher 语句,而使用数据库上下文生成答案可以留给 gpt-3.5-turbo。
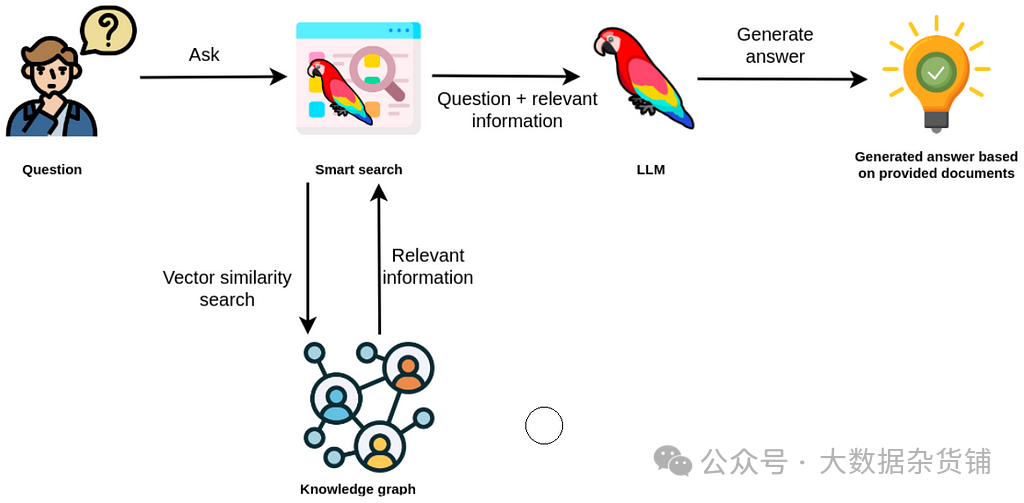
现在,您可以询问有关开放门票数量的相同问题。
Shell |
结果如下:
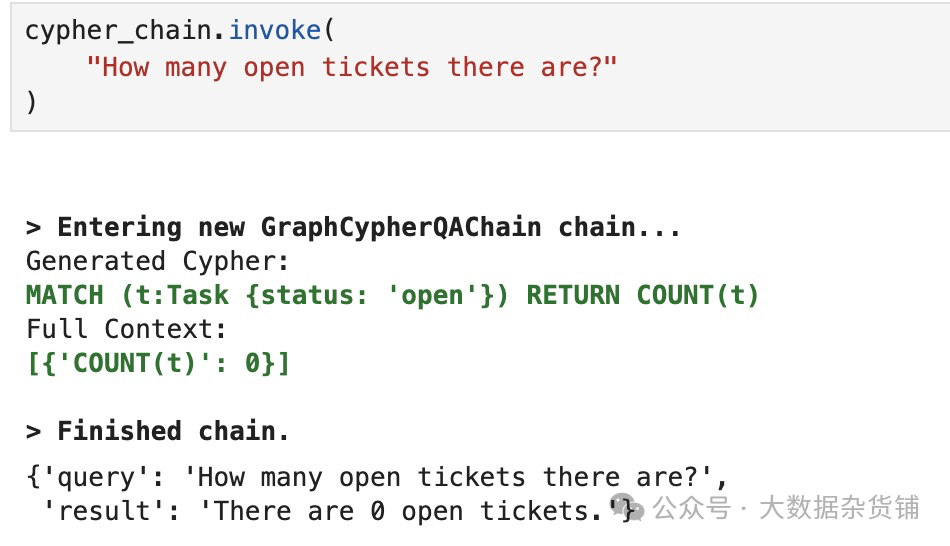
您还可以要求链使用各种分组键聚合数据,如下例所示。
Shell |
结果如下:
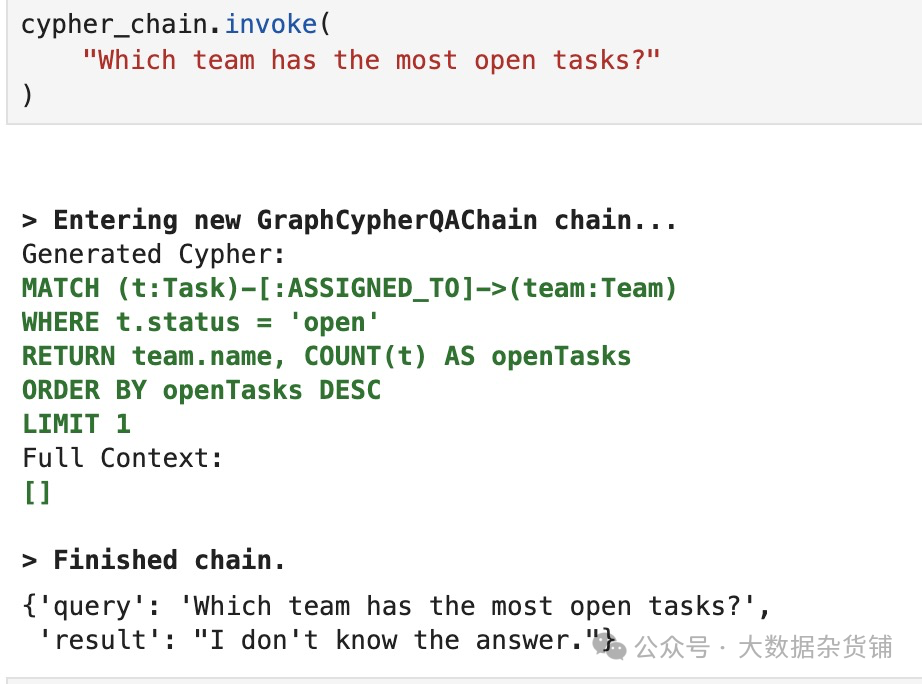
您可能会说这些聚合不是基于图的操作,这是正确的。当然,我们可以执行更多基于图的操作,例如遍历微服务的依赖图。
Shell |
结果如下:
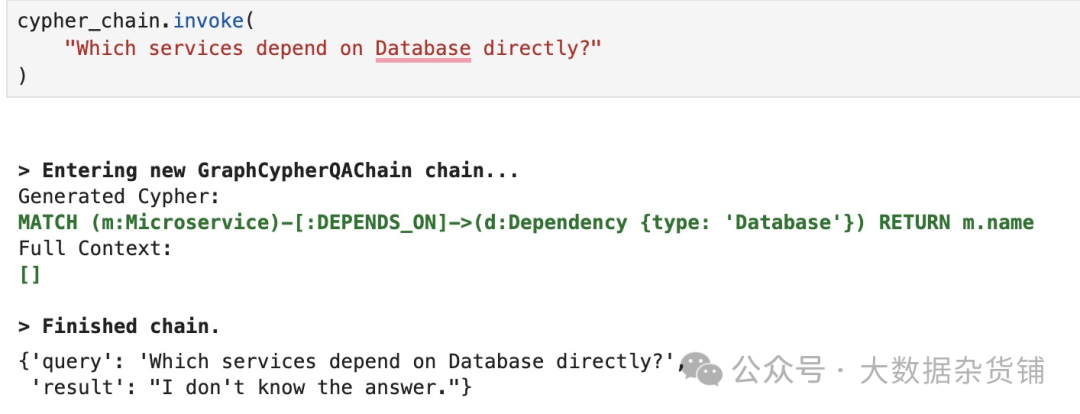
当然,您也可以通过提出以下问题来要求链产生可变长度的路径遍历:
Shell |
结果如下:
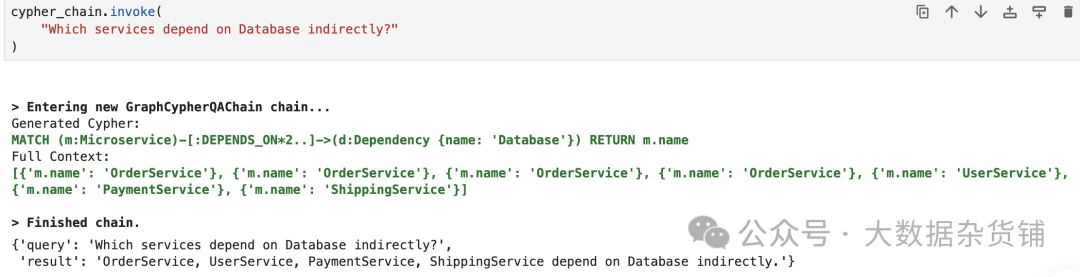
一些提到的服务与直接相关问题中的相同。原因是依赖图的结构而不是无效的 Cypher 语句。
知识图谱代理
我们为知识图谱的结构化和非结构化部分实现了单独的工具。现在我们可以添加一个代理来使用这些工具来探索知识图谱。
Shell |
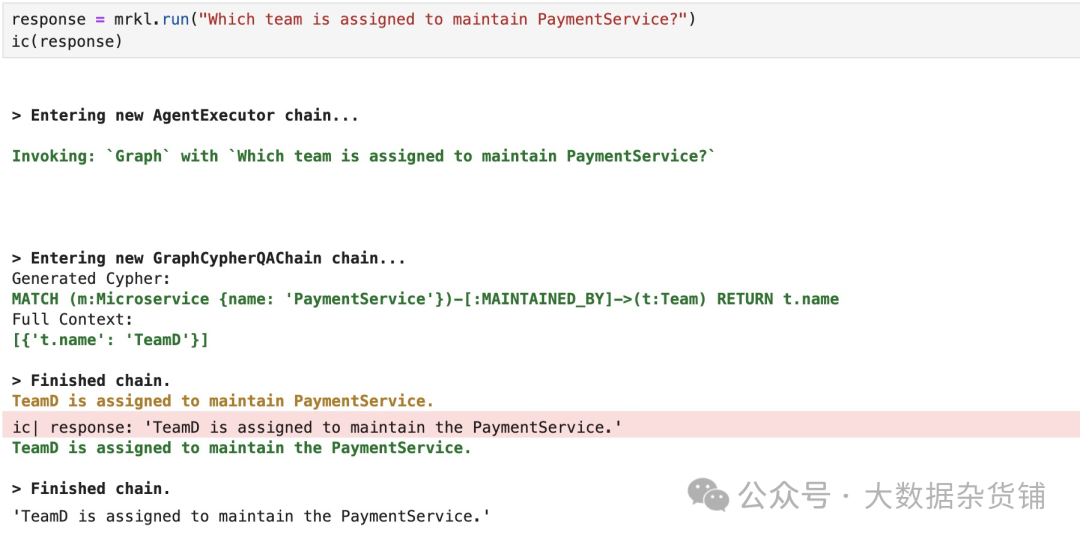
让我们试试代理的工作效果如何。
Shell |
结果如下:
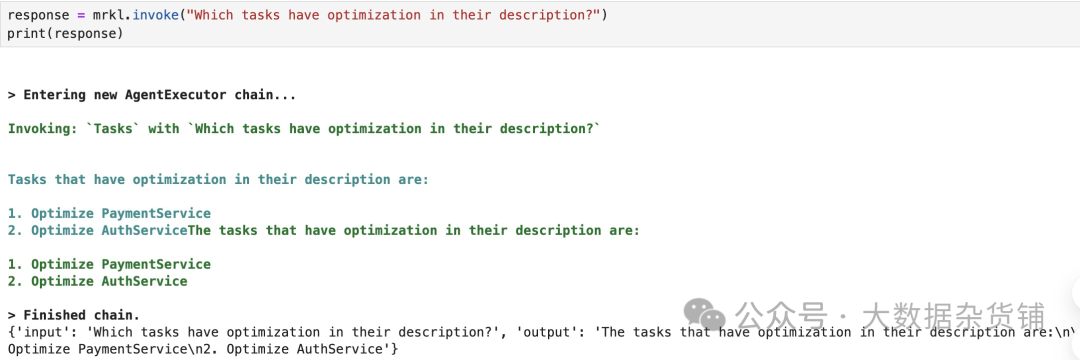
现在让我们尝试调用任务 工具。
Shell |
结果如下:
有一点是确定的。我必须提高代理的快速工程技能。工具描述肯定还有改进的空间。您还可以自定义代理提示。
知识图谱非常适合涉及结构化和非结构化数据的用例。此处显示的方法允许您避免多语言架构,在这种架构中您必须维护和同步多种类型的数据库。在此处了解有关 LangChain 中基于图的搜索的更多信息。
该代码可在 GitHub 上获取。
原文链接:https://neo4j.com/developer-blog/knowledge-graph-rag-application/
原文作者:Tomaz Bratanic
