




Spark 中的 Shuffle 是什么?
Spark 不会在节点之间随机移动数据。Shuffle 是一项耗时的操作,因此只有在没有其他选择的情况下才会发生。
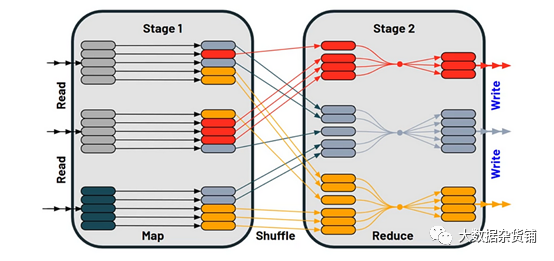
性能影响
最重要的部分→ 如何避免 Spark Shuffle?
使用适当的分区:确保您的数据从一开始就进行了适当的分区。如果您的数据已经根据您正在执行的操作进行分区,Spark 可以完全避免 Shuffle 。使用 repartition() 或 coalesce() 来控制数据的分区。
# Sample datadata = [(1, "A"), (2, "B"), (3, "C"), (4, "D"), (5, "E")]# Create a DataFramedf = spark.createDataFrame(data, ["id", "name"])# Bad - Shuffling involved due to default partitioning (200 partitions)result_bad = df.groupBy("id").count()# Good - Avoids shuffling by explicitly repartitioning (2 partitions)df_repartitioned = df.repartition(2, "id")result_good = df_repartitioned.groupBy("id").count()
尽早过滤:在转换中尽早对数据应用过滤器或条件。这样,您可以减少后续阶段需要打乱的数据量。
# Sample datasales_data = [(101, "Product A", 100), (102, "Product B", 150), (103, "Product C", 200)]categories_data = [(101, "Category X"), (102, "Category Y"), (103, "Category Z")]# Create DataFramessales_df = spark.createDataFrame(sales_data, ["product_id", "product_name", "price"])categories_df = spark.createDataFrame(categories_data, ["product_id", "category"])# Bad - Shuffling involved due to regular joinresult_bad = sales_df.join(categories_df, on="product_id")# Good - Avoids shuffling using broadcast variable# Filter the small DataFrame early and broadcast it for efficient joinfiltered_categories_df = categories_df.filter("category = 'Category X'")result_good = sales_df.join(broadcast(filtered_categories_df), on="product_id")
使用广播变量:如果您有较小的查找数据想要与较大的数据集连接,请考虑使用广播变量。将小数据集广播到所有节点比混洗较大数据集更有效。
# Sample dataproducts_data = [(101, "Product A", 100), (102, "Product B", 150), (103, "Product C", 200)]categories_data = [(101, "Category X"), (102, "Category Y"), (103, "Category Z")]# Create DataFramesproducts_df = spark.createDataFrame(products_data, ["product_id", "product_name", "price"])categories_df = spark.createDataFrame(categories_data, ["category_id", "category_name"])# Bad - Shuffling involved due to regular joinresult_bad = products_df.join(categories_df, products_df.product_id == categories_df.category_id)# Good - Avoids shuffling using broadcast variable# Create a broadcast variable from the categories DataFramebroadcast_categories = broadcast(categories_df)# Join the DataFrames using the broadcast variableresult_good = products_df.join(broadcast_categories, products_df.product_id == broadcast_categories.category_id)
避免使用groupByKey():首选reduceByKey()或aggregateByKey(),而不是groupByKey(),因为前者在打乱数据之前在本地执行部分聚合,从而获得更好的性能。
# Sample datadata = [(1, "click"), (2, "like"), (1, "share"), (3, "click"), (2, "share")]# Create an RDDrdd = sc.parallelize(data)# Bad - Shuffling involved due to groupByKeyresult_bad = rdd.groupByKey().mapValues(len)# Good - Avoids shuffling by using reduceByKeyresult_good = rdd.map(lambda x: (x[0], 1)).reduceByKey(lambda a, b: a + b)
使用数据局部性:只要有可能,尝试处理已存储在进行计算的同一节点上的数据。这减少了网络通信和Shuffle。
# Sample datadata = [(1, 10), (2, 20), (1, 5), (3, 15), (2, 25)]# Create a DataFramedf = spark.createDataFrame(data, ["key", "value"])# Bad - Shuffling involved due to default data localityresult_bad = df.groupBy("key").max("value")# Good - Avoids shuffling by repartitioning and using data localitydf_repartitioned = df.repartition("key") # Repartition to align data by keyresult_good = df_repartitioned.groupBy("key").max("value")
使用内存和磁盘缓存:缓存将在多个阶段重用的中间数据可以帮助避免重新计算并减少Shuffle的需要。
# Sample datadata = [(1, 10), (2, 20), (1, 5), (3, 15), (2, 25)]# Create a DataFramedf = spark.createDataFrame(data, ["key", "value"])# Bad - Shuffling involved due to recomputation of the filter conditionresult_bad = df.filter("value > 10").groupBy("key").sum("value")# Good - Avoids shuffling by caching the filtered datadf_filtered = df.filter("value > 10").cache()result_good = df_filtered.groupBy("key").sum("value")
优化数据序列化:选择 Avro 或 Kryo 等高效的序列化格式,以减少 Shuffle过程中的数据大小。
# Create a Spark session with KryoSerializerspark = SparkSession.builder \.appName("AvoidShuffleExample") \.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") \.getOrCreate()
调整Spark配置:调整Spark的配置参数,如Spark.shuffle.departitions、Spark.reducer.maxSizeInFlight和Spark.shuzzle.file.buffer。
监控和分析:使用Spark的监控工具,如Spark UI和Spark History Server来分析作业的性能,并确定可以优化shuffle的区域。
原文作者:Sushil Kumar
文章转载自大数据杂货铺,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
