




在最近的一篇博客文章中,我们探讨了用户如何使用 ClickHouse 和 Superset 提供快速、灵活的方式来以最低的成本从 Google Analytics 查询原始数据,从而增强其网站分析能力。
Superset 的简单学习曲线促使我探索LLM如何为技术水平较低的用户提供更简单的方法来探索 Google Analytics 数据。在技术博客中广泛使用 RAG、ML 和 LLM 等缩写词的背景下,我抓住这个机会深入研究计算机科学领域,而我的经验无疑是有限的。这篇文章既是我的旅程记录,也是我使用 LLM 和 RAG 简化应用程序接口的实验。
有了一组相当慷慨的 AWS 账户权限,授予我访问 Amazon Bedrock 的权限,我开始尝试为我的原始 Google Analytics 数据构建一个自然语言界面。这里的目标很简单:允许用户用自然语言提出问题并生成适当的 SQL,最终用底层数据回答他们的问题。如果成功,这可以构成一个简单界面的基础,用户可以通过该界面提出问题并呈现合理的图表。
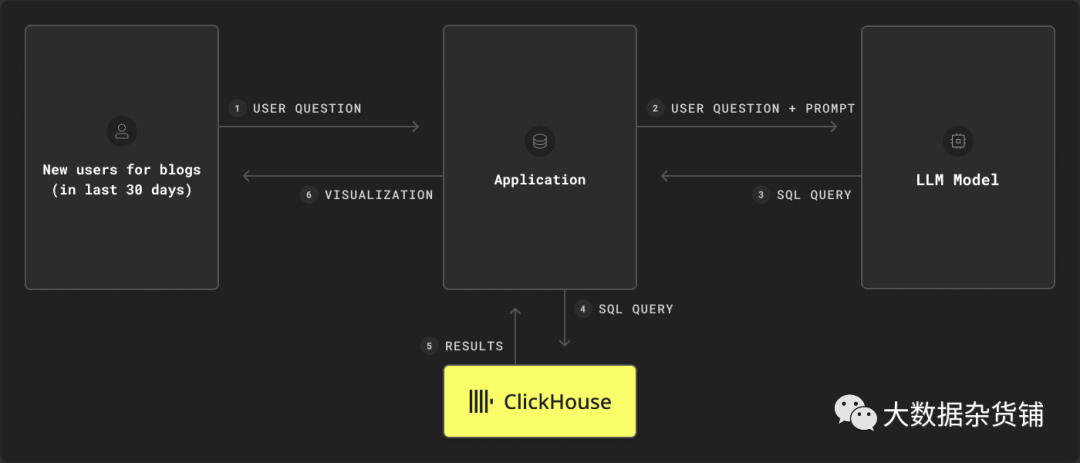
在我们之前的博客中,回想一下我们提出了以下Schema来在 ClickHouse 中保存 Google Analytics 数据:
CREATE TABLE default.ga_daily(`event_date` Date,`event_timestamp` DateTime64(3),`event_name` String,`event_params` Map(String, String),`ga_session_number` MATERIALIZED CAST(event_params['ga_session_number'], 'Int64'),`ga_session_id` MATERIALIZED CAST(event_params['ga_session_id'], 'String'),`page_location` MATERIALIZED CAST(event_params['page_location'], 'String'),`page_title` MATERIALIZED CAST(event_params['page_title'], 'String'),`page_referrer` MATERIALIZED CAST(event_params['page_referrer'], 'String'),`event_previous_timestamp` DateTime64(3),`event_bundle_sequence_id` Nullable(Int64),`event_server_timestamp_offset` Nullable(Int64),`user_id` Nullable(String),`user_pseudo_id` Nullable(String),`privacy_info` Tuple(analytics_storage Nullable(String), ads_storage Nullable(String), uses_transient_token Nullable(String)),`user_first_touch_timestamp` DateTime64(3),`device` Tuple(category Nullable(String), mobile_brand_name Nullable(String), mobile_model_name Nullable(String), mobile_marketing_name Nullable(String), mobile_os_hardware_model Nullable(String), operating_system Nullable(String), operating_system_version Nullable(String), vendor_id Nullable(String), advertising_id Nullable(String), language Nullable(String), is_limited_ad_tracking Nullable(String), time_zone_offset_seconds Nullable(Int64), browser Nullable(String), browser_version Nullable(String), web_info Tuple(browser Nullable(String), browser_version Nullable(String), hostname Nullable(String))),`geo` Tuple(city Nullable(String), country Nullable(String), continent Nullable(String), region Nullable(String), sub_continent Nullable(String), metro Nullable(String)),`app_info` Tuple(id Nullable(String), version Nullable(String), install_store Nullable(String), firebase_app_id Nullable(String), install_source Nullable(String)),`traffic_source` Tuple(name Nullable(String), medium Nullable(String), source Nullable(String)),`stream_id` Nullable(String),`platform` Nullable(String),`event_dimensions` Tuple(hostname Nullable(String)),`collected_traffic_source` Tuple(manual_campaign_id Nullable(String), manual_campaign_name Nullable(String), manual_source Nullable(String), manual_medium Nullable(String), manual_term Nullable(String), manual_content Nullable(String), gclid Nullable(String), dclid Nullable(String), srsltid Nullable(String)),`is_active_user` Nullable(Bool))ENGINE = MergeTreeORDER BY (event_timestamp, event_name, ga_session_id)
该表为每个 GA4 事件保存一行,可以使用正确的 SQL 问题从其中推断出“向我显示过去 30 天内博客文章的回访用户”等问题。
虽然我们预计 GA 数据的大多数问题的结构与上面的示例类似,但我们也希望能够根据概念回答更细致的问题。例如,假设我们想要“一段时间内访问过基于物化视图的页面的新用户总数”。这个问题的大部分都是结构化的,需要精确的列匹配和按日期 GROUP BY。然而,“物化视图”的概念有点微妙。需要一个延伸目标,如果我们能想出一种方法将概念表示为用户可以改进的更具体的东西,这似乎是可以实现的。
此时,可以合理地假设大多数读者已经使用或听说过大型语言模型 (LLM) 和生成式 AI,甚至可能使用过诸如 ChatGPT 之类的服务,这些服务将它们公开为服务。事实证明,这些服务对于广泛的应用程序非常有用,包括需要编写代码片段的技术用户。当提供Schema和问题时,SQL 生成的性能非常好。在 ClickHouse,我们实际上已经利用了这些功能,在ClickHouse Cloud SQL 控制台中公开了使用自然语言进行查询的能力。
虽然 ChatGPT 通常足以开始尝试使用,但当我们想要大规模构建某些东西或将这些功能集成到生产应用程序中时,在云提供商中探索等效服务总是有意义的。对于 AWS,Bedrock 服务通过将基础机器学习模型(包括 LLM)公开为完全托管的服务来提供这些功能。这些模型由 Anthropic 和 Cohere 等公司贡献,并通过简单的 API 提供。这是开始我的应用程序的最简单方法。
RAG(Retrieval-Augmented Generation) 这个术语目前似乎也非常普遍,一些公司认为它的需求如此普遍,以至于出现了一整类数据库来服务于此。检索增强生成(RAG)是一种旨在将预训练语言模型的强大功能与信息检索系统的优势相结合的技术。这里的目标通常很简单:通过为模型提供附加信息来提高生成文本的质量和相关性。这属于提示工程领域,我们修改问题或提示以包含更多有用的信息,以帮助LLM制定更准确的答案。
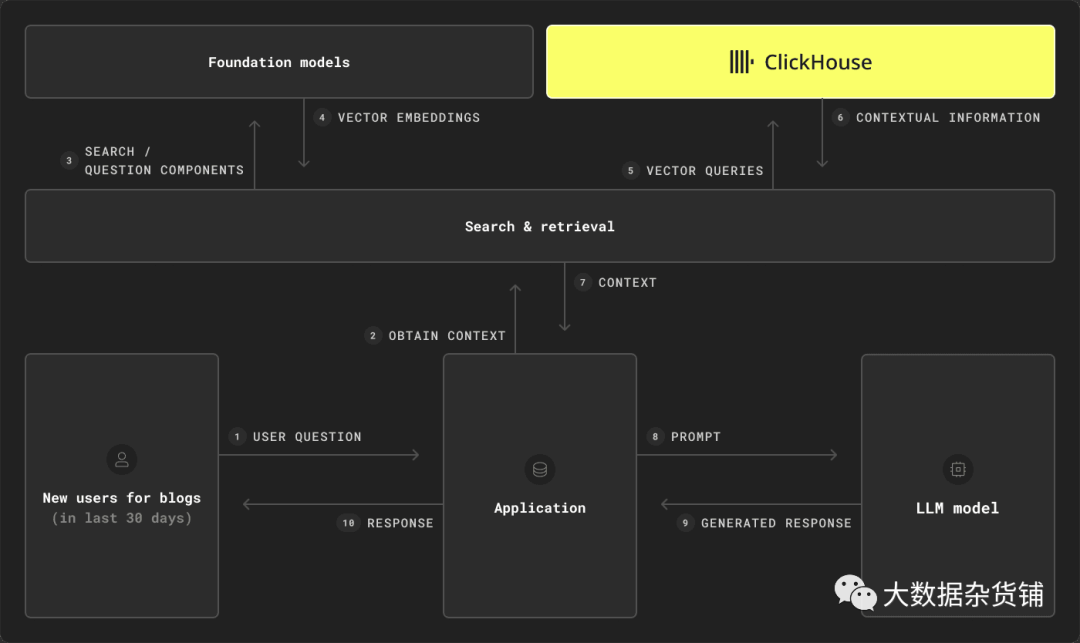
通过向LLM提供额外的信息,RAG旨在克服用户在依赖模型生成文本时经常遇到的一些问题,其中大部分是LLM的内部知识基于某个时间点的固定训练语料库的结果。如果无法访问特定领域或最新信息,模型可能会在问题超出基础知识的情况下陷入困境,导致没有答案或“幻觉”,其中响应不基于现实并且实际上不正确。
为了为我们的 Google Analytics 用例模型提供额外的支持信息,我们需要一种方法来查找与当前问题上下文相关的内容。在之前的博客文章中,我们探讨了如何通过向量嵌入来实现这一点。为此,我们可以使用另一个模型为我们将用作上下文的文档(例如内部文档)生成嵌入,并将其存储在数据库中。然后,我们可以使用相同的模型将用户的自然语言问题转换为嵌入,并检索最相关的内容(例如前 10 个文档),以在向我们的 LLM 模型/服务发出请求时用作上下文。
虽然专用矢量数据库是专门为此功能而设计的,但像 ClickHouse 这样的数据库也具有对矢量功能的本机支持。这意味着 ClickHouse既可以充当向量数据库,也可以充当分析数据库,从而无需在 RAG 管道中进行多个定制数据存储,从而简化了整体Schema。
诚然,检索和生成的两步过程是 RAG 的简单概述(尤其是掩盖了检索文档相关性的最大挑战),但足以满足我们的需求。
正如我们将在下面发现的,对于我们的用例,RAG 也是相关的,因为我们不仅需要提供表Schema,还需要提供可能的示例查询来解决问题,例如如何识别返回用户或 LLM 应如何处理不太结构化的问题例如“有关物化视图的帖子”。
我们应用程序的基础是文本到 SQL。这是一个活跃的研究领域,得益于Spider:耶鲁语义解析和文本到 SQL 挑战,可以相对容易地看出哪些方法在提供最佳准确性方面处于领先地位。
“Spider 挑战的目标是开发跨域数据库的自然语言接口。它由 10,181 个问题和 5,693 个独特的复杂 SQL 查询组成,涉及 200 个数据库以及覆盖 138 个不同领域的多个表。为了在这方面做得更好,系统不仅必须很好地推广到新的 SQL 查询,而且还必须推广到新的数据库Schema。”
这个特定的挑战比我们的 Google Analytics 问题到文本问题更普遍——我们的挑战是特定于域的,而 Spider 的目标是衡量跨域零样本性能。尽管如此,这些领先论文似乎仍值得探索以获取灵感。令人放心的是,包括DAIL-SQL在内的当前领导者依赖于使用即时工程和基于 RAG 的方法的原则。
DAIL-SQL的主要创新 是在一组可能有用的提示问题(“候选集”)中屏蔽关键字(例如列和值),并为问题生成嵌入。然后使用专业的预训练transformer模型生成(并屏蔽)的“skeleton”查询。通过将问题及其骨架 SQL 与候选问题及其 SQL 进行比较来依次识别提示的示例问题。请参阅此处了解更详细的概述。这是令人惊讶的简单和有效,并提供了一些关于实现体面结果的有用指导。
虽然我不需要上述过程的跨域功能的灵活性,但它确实提供了一些关于需要取得良好结果的提示。为类似问题提供 SQL 示例似乎对于良好的性能至关重要 - 特别是在我们的领域中,诸如“回访用户”之类的概念无法轻松地从Schema中推导出来。然而,考虑到我的问题的特定领域性质,屏蔽问题和比较 SQL 查询似乎没有必要。
最重要的是,很明显问题应该分解为多个步骤。
鉴于上述研究,我们的 RAG 流程总是要求我们能够生成文本嵌入(例如,找到类似的问题)。为此,我们使用一个简单的Python UDFembed.py,它可以在查询或插入时调用。这利用了通过 Bedrock 提供的亚马逊titan-embed-text-v1模型。embed.py的主要代码如下所示,这里有完整的支持文件:
#!/usr/bin/python3import jsonimport sysfrom bedrock import get_bedrock_clientfrom tenacity import (retry,stop_after_attempt,wait_random_exponential,)import logginglogging.basicConfig(filename='embed.log', level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')bedrock_runtime = get_bedrock_client(region="us-east-1", silent=True)accept = "application/json"contentType = "application/json"modelId = "amazon.titan-embed-text-v1"char_limit = 10000 # 1500 tokens effectively@retry(wait=wait_random_exponential(min=1, max=60), stop=stop_after_attempt(20))def embeddings_with_backoff(**kwargs):return bedrock_runtime.invoke_model(**kwargs)for size in sys.stdin:# collect batch to processfor row in range(0, int(size)):try:text = sys.stdin.readline()text = text[:char_limit]body = json.dumps({"inputText": text})response = embeddings_with_backoff(body=body, modelId=modelId, accept=accept, contentType=contentType)response_body = json.loads(response.get("body").read())embedding = response_body.get("embedding")print(json.dumps(embedding))except Exception as e:logging.error(e)print(json.dumps([]))sys.stdout.flush()
关联的 ClickHouse 配置位于/etc/clickhouse-server/:
embedexecutable_pool3trueTabSeparatedArray(Float32)Stringembed.py10000000100000001000000
关于上述几点重要的几点:
l我们使用tenacity库来确保我们通过退避重试失败的调用。如果我们达到 Bedrock 的tokens吞吐量或每分钟 API 调用的配额限制,这一点至关重要。请注意,Bedrock 允许为更高吞吐量的工作负载配置请求。
l我们使用可执行池来确保可以同时发出多个请求。这有效地启动了 N 个(配置中为 3 个)Python 进程,从而允许并行化请求。
l该参数send_chunk_header确保多个行值一次发送到 UDF。这包括指示行数的初始行。因此,我们首先从stdin中读取此内容,然后再迭代各行。这对于性能至关重要。
l我们的 UDF 接收文本并使用 Float32 数组进行响应。
要调用此 UDF,我们只需运行:
SELECT embed('some example text')FORMAT VerticalRow 1:──────embed('some example text'): [0.5078125,0.09472656,..,0.18652344]1 row in set. Elapsed: 0.444 sec.
该函数也可以在插入时调用。以下INSERT INTO SELECT代码从site_pages_raw表中读取行,并在content字段上调用embed函数。
INSERT INTO pages SELECT url, title, content, embed(content) as embedding FROM site_pages_raw SETTINGS merge_tree_min_rows_for_concurrent_read = 1, merge_tree_min_bytes_for_concurrent_read=0, min_insert_block_size_rows=10, min_insert_block_size_bytes=0
对于上面使用的设置,请注意以下几点:
l设置merge_tree_min_rows_for_concurrent_read = 1并merge_tree_min_bytes_for_concurrent_read = 0确保表temp被并行读取。当源表中的行数较少时,通常需要这些设置。这确保了我们的 UDF 不会被单线程调用。行数和字节数分别多于默认值 163840 和 251658240 的较大表不需要这些设置。然而,用户通常会为较小的表生成嵌入,因此这些是有用的。有关这些设置的更多详细信息,请观看此视频。
l这些设置min_insert_block_size_rows=10可min_insert_block_size_bytes=0确保我们调用具有较少行的 UDF。鉴于调用 Bedrock 时吞吐量通常为每秒 10-20 行,上述值可确保行以合理的速率出现在目标表中。更高的吞吐量(例如通过调用本地模型)将需要将这些设置增加到 128 到 4096(需要测试)。有关这些设置的更多详细信息,请参阅此处。如果对嵌入执行大量读取,则该设置max_block_size是相关的。
最终流程如下所示。RAG 流程的组件大部分是通过测试独立组装的,以确保每个组件都能提供准确的结果。
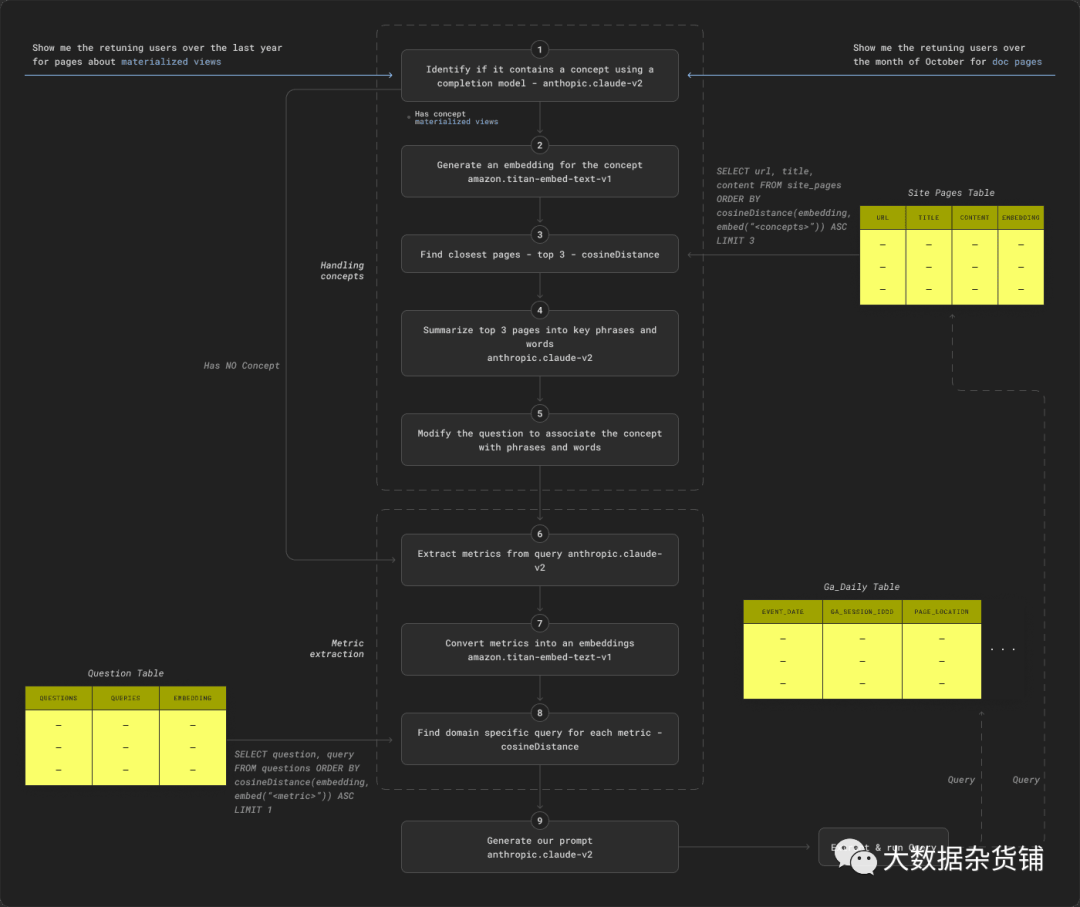
总之,我们的流程由两个主要阶段组成,以帮助提示生成:处理概念和指标提取。
概念提取尝试识别问题是否包含概念过滤器并采取步骤 (1) 到 (5):
1.我们首先使用anthropic.claude-v2模型和简单的提示来确定问题是否包含概念。如果不是,请转至指标提取和步骤 (6)。
2.使用amazon.titan-embed-text-v1模型将概念转换为嵌入。
3.使用步骤 (2) 中的嵌入在 ClickHouse 中搜索前 3 个最相关的页面。
4.提示 anthropic.claude-v2模型从步骤(3)返回的页面中提取关键词和短语
5.修改原问题,将概念与上述词语联系起来。
指标提取旨在识别问题需要计算的主要指标,以确保将相关示例添加到提示中。这需要执行步骤(6)至(9):
6.通过提示anthropic.claude-v2模型提取 GA 指标。
7.使用amazon.titan-embed-text-v1模型将指标转换为嵌入。
8.使用步骤 (7) 中的嵌入查询每个指标的最匹配问题。将这些添加到示例集中。
9.使用简单的正则表达式来确定网站的某个区域是否成为目标并添加示例。
最后,我们生成提示:
10.为anthropic.claude-v2模型生成最终的 SQL 提示以生成 SQL。针对站点页面和ga_daily表执行此操作。
如上所述,我们还希望能够灵活地处理概念性问题,例如“关于 X 的页面”。为此,我们需要上下文信息的文本内容,对于我们的用例来说,它是我们网站上的页面。虽然编写通用爬虫可能具有挑战性,但对于我们有限的站点来说,利用站点地图[ 1 ] [2]和页面结构的简单的基于Scrapy的爬虫应该足够了。对于那些希望在自己的站点上实现类似服务的人来说,该代码应该是可重用的。
要将页面与概念进行比较,我们需要一种方法:
1.从问题中提取概念。
2.表示概念以便可以识别相关页面。
对于 (1),我们尝试了多种技术,但发现Bedrock中可用的anthropic.claude-v2 model技术非常有效。通过包含示例的适当提示,事实证明,这可以准确地提取目标概念。
对于(2),我们首先识别与步骤(1)中提取的概念相关的页面。为此,我们根据文本内容以及概念本身为每个网站页面创建和存储嵌入。给定一个source_pages包含url、raw_title和raw_content列的源表,如下所示,我们可以在插入时调用embed函数将行插入到目标表site_pages中。请注意,我们还使用extractTextFromHTML函数从页面中提取内容,并将嵌入生成限制为 300 个tokens(使用该tokens函数来清理文本)。
CREATE TABLE source_pages(`url` String,`raw_title` String,`raw_content` String)ENGINE = MergeTreeORDER BY urlCREATE TABLE site_pages(`url` String,`raw_title` String,`raw_content` String,`title` String,`content` String,`embedding` Array(Float32))ENGINE = MergeTreeORDER BY urlINSERT INTO site_pagesSELECT url, raw_title, raw_content, extractTextFromHTML(raw_title) AS title, extractTextFromHTML(raw_content) AS content, embed(arrayStringConcat(arraySlice(tokens(concat(title, content)), 1, 300), ' ')) AS embeddingFROM source_pagesSETTINGS merge_tree_min_rows_for_concurrent_read = 1, merge_tree_min_bytes_for_concurrent_read = 0, min_insert_block_size_rows = 10, min_insert_block_size_bytes = 00 rows in set. Elapsed: 390.835 sec. Processed 2.95 thousand rows, 113.37 MB (7.55 rows/s., 290.08 KB/s.)Peak memory usage: 266.70 MiB.
我们可以使用以下查询来搜索该表,该查询使用之前的embed函数来为我们的概念使用 titan 模型创建嵌入。我们发现在此模型中cosineDistance可以提供最佳结果:
SELECT url, title, content FROM site_pages ORDER BY cosineDistance(embedding, embed('
使用 3 个最相关页面的聚合文本,我们依次提取主要短语和关键字(再次使用anthropic.claude-v2模型)。这些短语和关键字将作为示例问题和答案添加到提示中。这是我们特定领域的上下文,将帮助LLM更准确地执行我们的用例。例如,概念“词典”可能会导致将以下内容添加到提示中:
/* Answer the following: To filter by pages containing words: */SELECT page_location FROM ga_daily WHERE page_location IN (SELECT url FROM site_pages WHERE content ILIKE 'dictionary engine' OR content ILIKE 'dictionary functions' OR content ILIKE 'dictionary' OR content ILIKE 'dictionary configuration' OR content ILIKE 'cache' OR content ILIKE 'dictionary updates' OR content ILIKE 'dictionaries')
此外,我们重写了原始问题以表明该概念涉及单词过滤。
What are the number of new users for blogs about dictionaries over time?becomes…What are the number of new users for blogs about dictionaries over time? For the topic of dictionaries, filter by dictionary configuration,dictionaries,dictionary functions,cache,dictionary engine,dictionary,dictionary updates
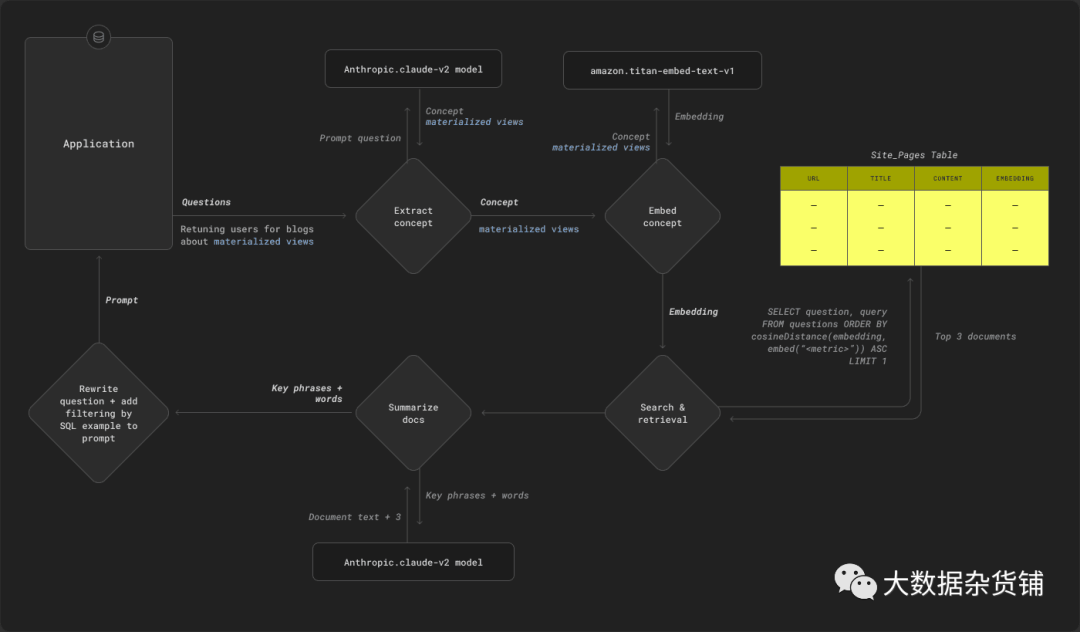
这里的原则思想是我们将这些短语呈现给用户作为最能代表目标概念的短语,可能还有匹配的页面。他们可以根据结果依次选择添加或删除短语和单词。虽然这不一定是表示概念的唯一方法,但它的优点是可以将概念等松散的想法变成具体的东西。这种方法也比其他明显的替代方法更简单:只需向主查询添加一个过滤器,该过滤器根据概念嵌入的距离函数来过滤页面。后一种方法要求我们要么定义需要建立的最低分数,要么仅使用前 K 个分数。对于最终用户来说,这两种方法似乎都不现实且无法解释。
根据研究,在提示中添加问题对于获得良好结果至关重要。考虑到对于许多 Google Analytics 指标(例如“回访用户”或“会话总数”),没有简单的方法可以从Schema中推断出它们,这一点似乎更加重要。例如,如我们之前的博客所示,我们将“回访用户”的指标估计为以下查询:
SELECT event_date, uniqExact(user_pseudo_id) AS returning_usersFROM ga_dailyWHERE (event_name = 'session_start') AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date)GROUP BY event_dateORDER BY event_date ASC
对于LLM来说,仅从Schema推断这个特定的查询将是一项挑战。因此,我们的目标是在需要时在我们的提示中提供此内容作为上下文。例如:
/*Answer the following: find returning users:*/SELECT uniqExact(user_pseudo_id) AS returning_users FROM ga_daily WHERE (event_name = 'session_start') AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date)
根据一些初步实验,我们还发现,在提示中提供所有可能的指标及其 SQL 示例作为问题会降低生成文本的预测质量。较长的提示会导致关键细节被忽略,而且速度也会变慢,消耗更多的tokens。因此,我们选择了一个简单的补充表,其中包含问题、其 SQL 响应以及问题本身的嵌入:
CREATE TABLE default.questions(`question` String,`query` String,`embedding` Array(Float32))ENGINE = MergeTreeORDER BY question
我们可以使用与之前相同的 UDF 嵌入函数来填充它。
初始实验使用以下查询来识别前 3 个最相关的示例问题:
SELECT question, query FROM questions ORDER BY cosineDistance(embedding, embed("Show me returning users over the last 30 days for blog posts")) ASC LIMIT 3
虽然简单,但结果并不令人满意,结果并不总是包括所需的 GA 指标。我们需要一种方法来提取:
l问题包含的具体 Google Analytics 指标,例如“回访用户”。
l问题是否针对网站的某个区域,例如博客或文档。这对于我们的用例来说可能很常见,并转换为 URL 上的特定过滤器。这种“领域知识”也不能从Schema中推断出来。
对于此任务,我们重用 Claude 模型,使用带有示例的提示从查询中提取关键指标。这将返回关键指标,这些指标又被嵌入并用于识别适当的问题。
例如,对于“文档页面 10 月份每天返回的用户数量是多少?”这个问题 我们提取“回访用户”指标,得出以下查询:
SELECT question, query FROM questions ORDER BY cosineDistance(embedding, embed("returning users")) ASC LIMIT 1
匹配的问题及其附带的 SQL 依次添加到我们的最终提示中。最后,如果问题按博客或文档过滤(通过简单的正则表达式匹配建立),我们将添加一个如何按此站点区域过滤的示例。
考虑到早期研究强调提示结构的重要性,我们还尝试遵循Claude模型的人择文档所制定的指导方针。这包括一个用于模型快速工程的优秀平台,其中以下内容似乎与我的任务相关:
l遵循人类/辅助所需的结构。
l利用 XML 标签在问题中提供提示结构并允许对响应进行分隔,例如在<example>标签中提供示例、在<schema>标签中提供Schema。
l提供附加信息作为Schema的规则。
l提示Schema的排序。这包括确保输出格式的请求和问题位于提示的底部。
考虑到这一点,我们的提示看起来像这样:
Human: You have to generate ClickHouse SQL using natural language query/request. Your goal -- create accurate ClickHouse SQL statements and help the user extract data from ClickHouse database. You will be provided with rules, database schemaand relevant SQL statement examples .This is the table schema for ga_daily.CREATE TABLE ga_daily(`event_date` Date,`event_timestamp` DateTime64(3),`event_name` Nullable(String),`event_params` Map(String, String),`ga_session_number` MATERIALIZED CAST(event_params['ga_session_number'], 'Int64'),`ga_session_id` MATERIALIZED CAST(event_params['ga_session_id'], 'String'),`page_location` MATERIALIZED CAST(event_params['page_location'], 'String'),`page_title` MATERIALIZED CAST(event_params['page_title'], 'String'),`page_referrer` MATERIALIZED CAST(event_params['page_referrer'], 'String'),`event_previous_timestamp` DateTime64(3),`event_bundle_sequence_id` Nullable(Int64),`event_server_timestamp_offset` Nullable(Int64),`user_id` Nullable(String),`user_pseudo_id` Nullable(String),`privacy_info` Tuple(analytics_storage Nullable(String), ads_storage Nullable(String), uses_transient_token Nullable(String)),`user_first_touch_timestamp` DateTime64(3),`device` Tuple(category Nullable(String), mobile_brand_name Nullable(String), mobile_model_name Nullable(String), mobile_marketing_name Nullable(String), mobile_os_hardware_model Nullable(String), operating_system Nullable(String), operating_system_version Nullable(String), vendor_id Nullable(String), advertising_id Nullable(String), language Nullable(String), is_limited_ad_tracking Nullable(String), time_zone_offset_seconds Nullable(Int64), browser Nullable(String), browser_version Nullable(String), web_info Tuple(browser Nullable(String), browser_version Nullable(String), hostname Nullable(String))),`geo` Tuple(city Nullable(String), country Nullable(String), continent Nullable(String), region Nullable(String), sub_continent Nullable(String), metro Nullable(String)),`app_info` Tuple(id Nullable(String), version Nullable(String), install_store Nullable(String), firebase_app_id Nullable(String), install_source Nullable(String)),`traffic_source` Tuple(name Nullable(String), medium Nullable(String), source Nullable(String)),`stream_id` Nullable(String),`platform` Nullable(String),`event_dimensions` Tuple(hostname Nullable(String)),`collected_traffic_source` Tuple(manual_campaign_id Nullable(String), manual_campaign_name Nullable(String), manual_source Nullable(String), manual_medium Nullable(String), manual_term Nullable(String), manual_content Nullable(String), gclid Nullable(String), dclid Nullable(String), srsltid Nullable(String)),`is_active_user` Nullable(Bool))ENGINE = MergeTreeORDER BY event_timestampThis is the table schema for site_pages.CREATE TABLE site_pages(`url` String,`title` String,`content` String)ENGINE = MergeTreeORDER BY urlYou can use the tables "ga_daily" and "site_pages".The table ga_daily contains website analytics data with a row for user events. The following columns are important:- event_name - A string column. Filter by 'first_visit' if identifying new users, 'session_start' for returning users and 'page_view' for page views.- event_date - A Date column on which the event occured- event_timestamp - A DateTime64(3) with the event time to milli-second accuracy- ga_session_id - A string identifying a user session.- ga_session_number - The session number for the user- user_pseudo_id - A string uniquely identifying a user- is_active_user - A boolean indicating if the user was active. True if active or engaged.- user_first_touch_timestamp - The first time a user visited the site.- page_location - the full url of the page.- page_title - The page title.- page_referer - The referer for the page. A full url.- traffic_source.name provides the source of the traffic./*Answer the following: find new users:*/SELECT count() AS new_users FROM ga_daily WHERE event_name = 'first_visit'/*Answer the following: filter by blogs:*/SELECT page_location FROM ga_daily WHERE page_location LIKE '%/blog/%'/* Answer the following: To filter by pages containing words: */SELECT page_location FROM ga_daily WHERE page_location IN (SELECT url FROM site_pages WHERE content ILIKE 'cache' OR content ILIKE 'dictionary' OR content ILIKE 'dictionaries' OR content ILIKE 'dictionary configuration' OR content ILIKE 'dictionary updates' OR content ILIKE 'dictionary functions' OR content ILIKE 'dictionary engine')Considering all above generate a ClickHouse SQL statement for the following query:What are the number of new users for blogs about dictionaries over time?. For the topic of dictionaries, filter by cache,dictionary,dictionaries,dictionary configuration,dictionary updates,dictionary functions,dictionary enginePut result statement intags:
根据 Anthropic 的建议,我们将模型温度设置为 0,以便在重复试验中提供更一致的结果。top_k 的值为 100 似乎可以提供相当一致的结果,并避免注入作为长尾一部分的随机项。
那么问题是,它的性能如何?为了评估这一点,我们创建了一个问题测试。下面,我们提出生成的问题以及这是否会产生预期的答案。
以上并不是一个广泛的测试集。生产系统需要一组更完整的问题,并使用测试框架来根据权威响应评估查询的响应(测试响应似乎更合适,因为问题生成可能会有所不同)。
问题 | 生成的响应 | 正确的 |
2023 年 10 月文档页面每天的回访用户数量是多少? | sql SELECT event_date, uniqExact(user_pseudo_id) AS returning_users FROM ga_daily WHERE event_name = 'session_start' AND is_active_user AND (ga_session_number > 1 OR user_first_touch_timestamp < event_date) AND event_date BETWEEN '2023-10-01' AND '2023-10-31' AND page_location LIKE '%/docs/%' GROUP BY event_date ORDER BY event_date | Yes |
随着时间的推移,有关词典的博客的新用户数量是多少? | sql SELECT toStartOfMonth(event_date) AS month, count() AS new_users FROM ga_daily WHERE event_name = 'first_visit' AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%dictionary%' OR content ILIKE '%dictionary functions%' OR content ILIKE '%dictionaries%' OR content ILIKE '%dictionary configuration%' OR content ILIKE '%dictionary engine%' OR content ILIKE '%cache%' OR content ILIKE '%dictionary updates%') GROUP BY month ORDER BY month | Yes |
自 2023 年 1 月以来,URL 包含“/docs/en”的页面的每月总会话数是多少? | sql SELECT toStartOfMonth(event_date) AS month, uniqExact(ga_session_id, '_', user_pseudo_id) AS total_sessions FROM ga_daily WHERE page_location LIKE '%/docs/en%' AND event_date >= '2023-01-01' GROUP BY month ORDER BY month | Yes |
一段时间内的总页面浏览量是多少? | sql SELECT toStartOfDay(event_date) AS day, count() AS total_page_views FROM ga_daily WHERE event_name = 'page_view' GROUP BY day ORDER BY day | Yes |
有多少活跃用户访问过有关编解码器和压缩技术的博客? | sql SELECT count(DISTINCT user_pseudo_id) AS active_users FROM ga_daily WHERE ((event_name = 'session_start') AND is_active_user) OR (event_name = 'first_visit') AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE ANY ('%codecs%', '%zstd%', '%lz4%', '%techniques%', '%compression%') ) | Yes |
一段时间内的总用户是多少? | sql SELECT toDate(event_timestamp) AS date, uniq(user_pseudo_id) AS total_users FROM ga_daily WHERE event_name = 'session_start' GROUP BY date ORDER BY date | Yes |
随着时间的推移,有关物化视图的页面的总用户数是多少? | sql SELECT toStartOfMonth(event_date) AS month, uniq(user_pseudo_id) AS total_users FROM ga_daily WHERE event_name = 'session_start' AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%monthly aggregated%' OR content ILIKE '%materialized views%' OR content ILIKE '%system tables%' OR content ILIKE '%materialized%' OR content ILIKE '%materialized view%' OR content ILIKE '%queries%' OR content ILIKE '%yearly aggregated%' ) GROUP BY month ORDER BY month | Yes |
随着时间的推移,流量来源是什么? | sql SELECT toStartOfHour(event_timestamp) AS hour, traffic_source.name AS source, count(*) AS visits FROM ga_daily WHERE event_name = 'session_start' GROUP BY hour, source ORDER BY hour | Yes,但问题很模糊,例如时间单位。 |
有关 Snowflake 的页面的网站会话总数是多少? | sql SELECT count(DISTINCT ga_session_id, '_', user_pseudo_id) AS total_sessions FROM ga_daily WHERE page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%snowflake%' OR content ILIKE '%cloud data warehouse%' OR content ILIKE '%real-time analytics%' OR content ILIKE '%materialized views%' OR content ILIKE '%micro-partitions%' ) | Yes |
随着时间的推移,每篇博客文章的平均浏览量是多少? | sql SELECT toStartOfMonth(event_date) AS month, page_title, count() AS views FROM ga_daily WHERE page_location LIKE '%/blog/%' AND event_name = 'page_view' GROUP BY month, page_title ORDER BY month, views DESC | Yes page_title 可能不是唯一的,但用户可以改进。 |
有多少用户访问了标题为“增压大型 ClickHouse 数据负载 - 调整大型数据负载以提高速度”的博客?是新的吗? | sql SELECT count() AS new_users FROM ga_daily WHERE event_name = 'first_visit' AND page_location IN ( SELECT url FROM site_pages WHERE content ILIKE '%clickhouse%' OR content ILIKE '%loads%' OR content ILIKE '%large%' OR content ILIKE '%speed%' OR content ILIKE '%data loads%' OR content ILIKE '%supercharging%' OR content ILIKE '%tuning%' OR content ILIKE '%data%' AND title = 'Supercharging your large ClickHouse data loads - Tuning a large data load for speed?' ) | Yes。由于概念识别不正确,对内容进行了不必要的过滤。 |
2023 年 10 月新用户与回访用户的比例是多少? | sql WITH ( SELECT count() AS new_usersFROM ga_daily WHERE (event_name = 'first_visit') AND (toYYYYMM(event_date) = 202310) ) AS new_users, ( SELECT uniqExact(user_pseudo_id) AS returning_users FROM ga_daily WHERE (event_name = 'session_start') AND is_active_user AND ((ga_session_number > 1) OR (user_first_touch_timestamp < event_date)) AND (toYYYYMM(event_date) = 202310) ) AS returning_users SELECT if(new_users = 0, 0, returning_users / new_users) AS new_to_returning_ratio | Yes |
每个回访用户每天的文档页面平均浏览次数是多少? | sql SELECT user_pseudo_id, event_date, count() AS page_views FROM ga_daily WHERE event_name = 'page_view' AND page_location LIKE '%/docs/%' AND is_active_user = 1 GROUP BY user_pseudo_id, event_date ORDER BY user_pseudo_id, event_date | No。这计算的是每天的平均用户浏览量。不会过滤回访用户。 |
从 2003 年 9 月开始,每天发布了多少篇博客文章? | sql SELECT toDate(event_timestamp) AS event_date, count(*) AS blog_posts_published FROM ga_daily WHERE page_location LIKE '%/blog/%' GROUP BY event_date HAVING event_date >= '2003-09-01' AND event_date <= '2003-09-30' | No,没有出版的概念。 |
从这个结果样本中得出的一些观察结果:
l当问题可以通过 GROUP BY 解决并且它针对单个 Google Analytics 指标时,所提供的上下文似乎效果很好。
l基于将概念定义为一组单词的概念过滤似乎与将其实现为子查询效果很好。任何界面都会要求用户改进这些单词,因为他们最多只能估计一个概念。
lClickHouse 文档显然是 LLM 模型训练的一部分,因为尽管提示中没有出现toStartOfMonth,但仍然使用了类似的函数。然而,额外的基于文档的上下文可能会很有用。
l当时间段模糊时,该模型提供了不错的效果,例如“一段时间内的流量来源是什么?” 使用间隔。这可能可以通过及时修改来解决。
l即使没有提供示例问题,也会提供正确的答案,例如用于识别流量来源。在这种情况下,将从Schema和附加上下文中推导出适当的列。
l该模型很难处理后两个查询。“每个回访用户每天的文档页面平均浏览量是多少?” 结合了两个 GA 指标,并需要一个子查询来识别返回的用户,并按此集合过滤每个用户的平均观看次数。但是,生成查询是为了计算(使用不正确的查询)用户每天的平均查看次数。该查询在概念上具有挑战性,并且可能会受益于微调。
l我们的后一个问题因上下文不足而失败。我们没有示例问题来展示如何计算博客的发布日期。
此次实施的最大收获是将 RAG 流程分解为多个步骤。在上面的流程中,我们单独使用基础模型来识别概念和指标,以确保提示中提供适当的上下文。
上面的提示还进行了一些迭代以确保其正确。事实证明,及时的结构和遵守 Anthropic 文档的指导方针至关重要——尤其是及时排序和使用 XML 标签。如果不遵守这些标准,我们发现信息将被忽略 - 特别是示例。快速工程和细化的过程是高度迭代的,实际上,需要一个具有各种示例测试问题的测试工具。如果没有这一点,这个过程可能会非常令人沮丧。
总的来说,上述性能是有希望的,但很明显,当无法为特定问题提供示例查询时,该方法会遇到困难。具体来说,我们缺乏有助于构建更复杂的连接查询或子过滤的示例问题。这些问题一般来说更具挑战性,我们的大多数示例只是展示如何计算指标。接下来的步骤可能是捕获各种示例问题。然后,除了基于显式指标的现有匹配之外,还可以包括其中最接近的概念匹配作为示例。
显然,问题的精确性以及向用户提供如何构建问题的指南非常重要。我们的 RAG 管道目前相当慢,有多个步骤,可能会使用更轻量级的模型和/或很少的tokens。模型的细化也可能有利于许多步骤的准确性。模型细化可能也值得在每个步骤中进行探索,以提高性能和准确性。
当前的精度不足以让应用程序自动呈现图表。因此,我们决定探索一种方法,除了图表以及添加到提示中的上下文之外,还向用户显示生成的 SQL。这符合我们可能需要用户改进用于表示概念的词语。虽然这可能无法解决我们最初的问题,但我们怀疑刚接触数据集的用户可能仍然会发现这种方法的价值。
原文链接:https://clickhouse.com/blog/retrieval-augmented-generation-rag-with-clickhouse-bedrock
