





RAGAS: 检索增强生成的自动评估
1.论文概述
Retrieval-Augmented Generation (RAG) 是一种将检索机制与生成模型相结合的方法,首先通过检索与问题相关的文档或知识,然后基于检索结果生成答案或文本。最近的研究表明,RAG可以显著提高各种基准的生成质量。然而,RAG在检索阶段和生成阶段的质量评估也至关重要,这有利于帮助解决RAG的限制问题。
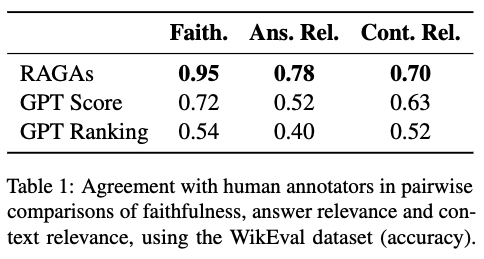
为了解决这个问题,本文设计了一个用于自动评估RAG的框架 RAGAS。该框架可以评估忠实度(即答案是否能够基于检索到的上下文推出)、答案相关性(即答案是否解决了问题)和上下文相关性(即检索到的上下文是否足够集中)。RAGAS 框架提供了与 llamaindex 和 Langchain 的集成,这两个框架是构建 RAG 解决方案最通用的框架,因此开发人员能够轻松地将 RAGAS 集成到他们的标准工作流中。
2.核心方法
接下来介绍RAGAS提供的几个主要评价指标:Faithfulness、Answer relevance、Context Relevance。这三个指标主要是基于大模型来进行评测。
2.1 Faithfulness 忠诚度评测
Faithfulness衡量了生成的答案与给定上下文的事实一致性。这个指标对于避免大模型幻觉以及确保检索到的上下文可以作为生成答案的依据非常重要。事实上,RAG系统对于生成文本和给定来源的事实性一致性非常重要,例如在法律领域。
评测方法:如果答案中的所有声明都可以从给定的上下文中推断出来,则生成的答案被视为可信的。要计算这一点,首先使用LLM从生成的答案提取一组声明,提取方法如下:

对于每个声明,使用LLM来决定是否可以给定的上下文中推出,判断如下:

最终确定分数:
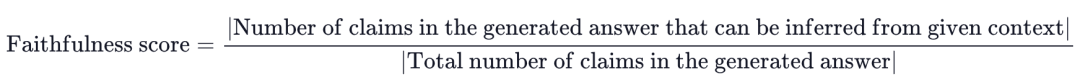
2.2 Answer relevance 回答相关性评测
Answer relevance 侧重于评估生成的答案是否能够解决输入的问题。不完整或包含冗余信息的答案得分较低,得分较高则表示相关性更高。
评测方法:对于生成的答案,首先使用 LLM 根据生成的答案 生成n 个潜在问题,生成方法如下:
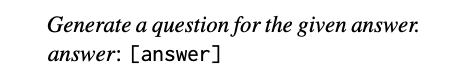
接下来使用向量模型text-embedding-ada-002计算每个问题的嵌入值。然后计算每个问题和原始输入问题嵌入值的余弦相似性。最后得到分数:
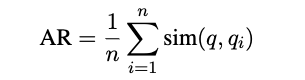
2.3 Context relevance 上下文相关性评测
Context relevance 侧重于评估检索的质量,主要量化检索的内容是否更精确。如果检索的上下文包含与回答问题相关的内容,即认为检索是有相关性的。
评测方法:为了评估相关性,首先使用LLM从检索的上下文中提取对问题答案至关重要的句子集合,提取方法如下:

然后基于提取的数量,以及检索内容的总句子数量,计算得分:
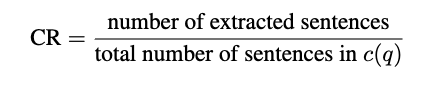
3.精彩段落
4.总结
~
Email: supeng842499467@gmail.com
