






一、性能初探
开启聚合下推
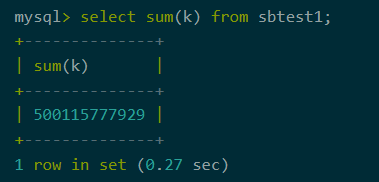
图1:开启聚合下推耗时
关闭聚合下推
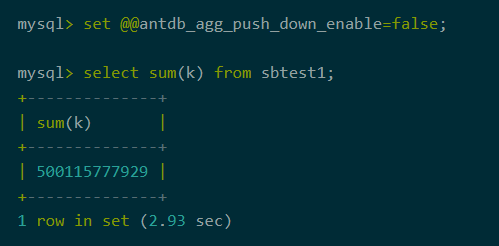
图2:关闭聚合下推耗时
单机版
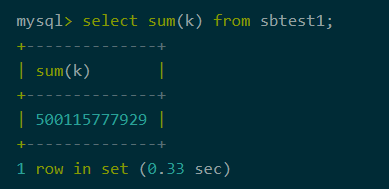
图3-单机版耗时
表1-查询耗时比对
单机版 | 关闭聚合下推 | 开启聚合下推 |
0.33 sec | 2.93 sec | 0.27 sec |
分布式部署的AntDB-M开启聚合下推是单机版的1.2倍,是不开启聚合下推的10.8倍。由此可以看出聚合下推功能对分析型SQL有着极大的性能提升。
1、用户变量
在聚合下推中,支持使用用户变量。使用用户变量,业务系统可以很方便的编写灵活的SQL语句。
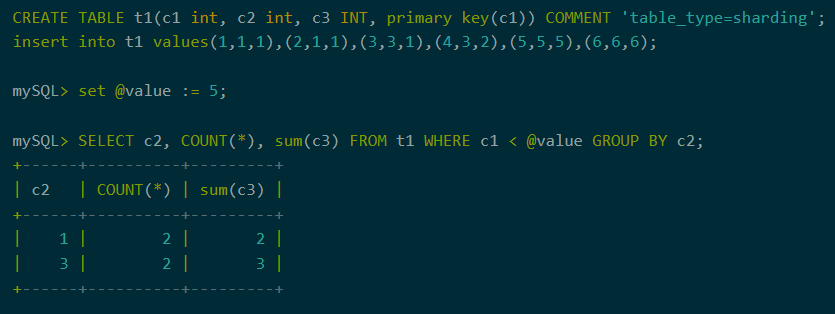
图4:用户变量
2、数字编号引用查询列
支持group by, order by从句中通过数字编号引用查询列。通过数字引用查询列,可以简化SQL的编写,使得SQL逻辑更简单清晰,也方便动态生成SQL的编写。
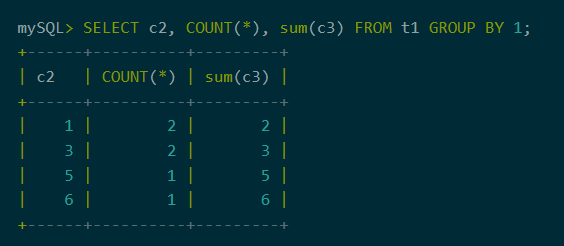
图5:数字编号引用查询列
3、having从句
having从句不但可以使用聚合函数,也可以引用基础列,使用上没有限制。

图6:having
4、Order by从句
排序是查询中常用的功能。聚合下推不仅支持order by从句,也支持对查询列的数字编号引用。还可以根据需要灵活设置排序规则。
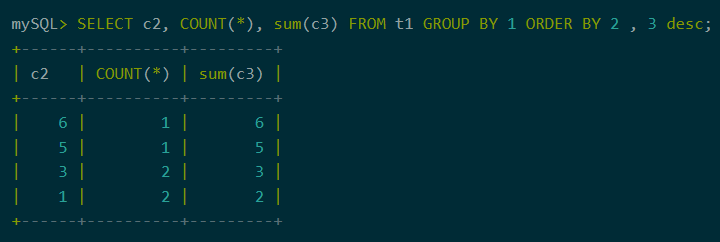
图7:order by
5、limit从句
当查询结果数据量太大时,可以通过limit限制一次返回的记录数。支持多种limit语法。
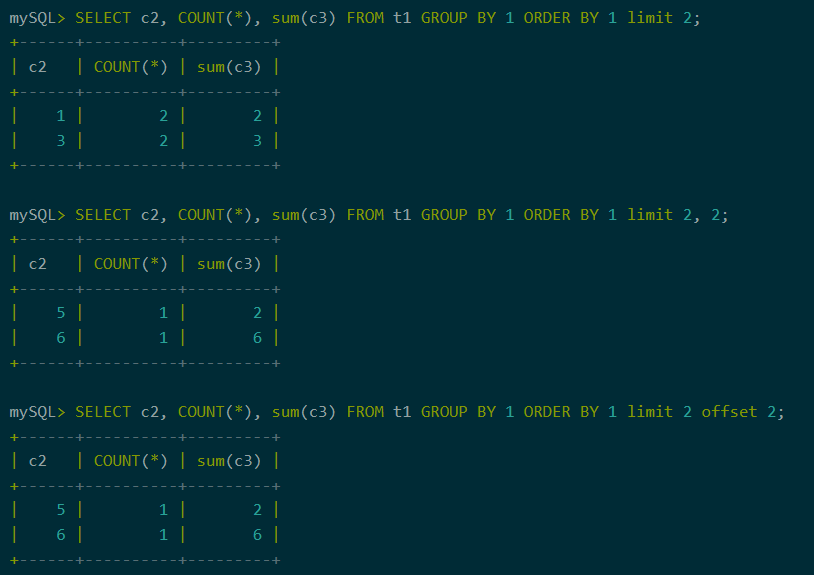
图8:limit
6、into从句
根据业务需要,查询结果可以导出到外部文件,支持into outfile, into dumpfile。也支持导出到变量。支持灵活的into从句位置。
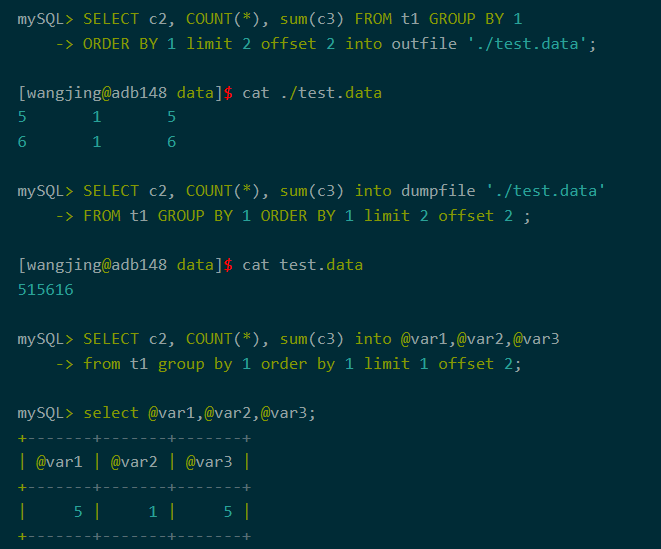
图9-into
7、存储过程,触发器
聚合下推不仅仅支持直接的SQL查询,还支持存储过程和触发器。当存储过程或触发器中存在聚合查询时,会触发聚合下推。
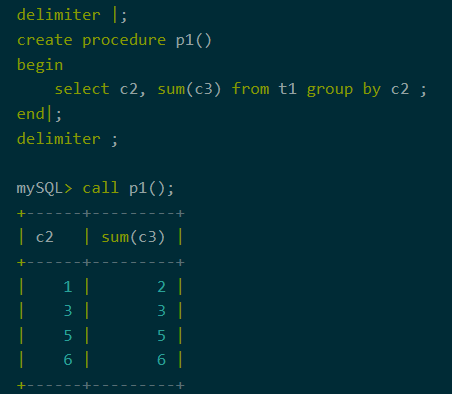
图10:存储过程
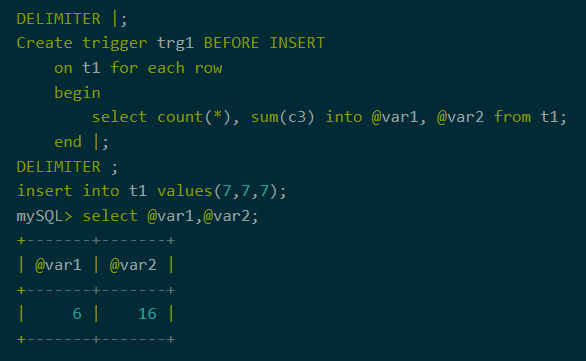
图11:触发器



文章转载自AntDB数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
