




索引优化细节
当使用索引列进行查询的时候尽量不要使用表达式,把计算放到业务层而不是数据库层
我们分别执行下面两条SQL语句,可以查看到执行的结果是相同的,通过执行计划可以看出const的效率高于index,效率是完全不同
select actor_id from actor where actor_id=4;select actor_id from actor where actor_id+1=5;复制
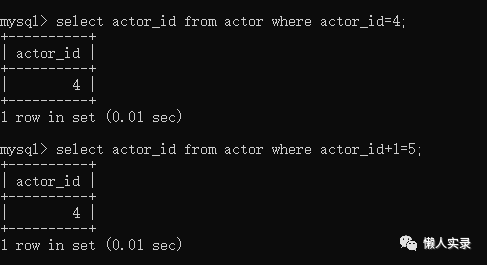

尽量使用主键查询,而不是其他索引,因此主键查询不会触发回表查询
使用索引扫描来排序
order by是比较浪费内存的,如果不需要一些额外的文件和内存就能排序的话这样就会提高性能,当我们创建索引的时候索引本身就是有序的,我们可以直接拿索引进行排序。
通过show index from actor 查看表的索引

explain select * from actor order by actor_id;(索引)explain select * from actor order by first_name;(无索引)复制
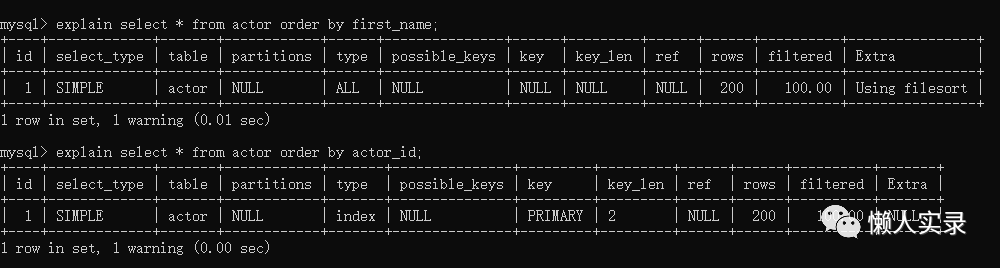
查看Extra为Using filesort 是文件排序,type为index,Extra为null是索引排序,扫描索引本身是很快的,因为只需要从一条索引记录移动到紧接着的下一条记录。但如果索引不能覆盖查询所需的全部列,那么就不得不每扫描一条索引记录就得回表查询一次对应的行,这基本都是随机IO,因此按索引顺序读取数据的速度通常要比顺序的全表扫描慢。
范围列可以用到索引
范围列可以用到索引,但是范围列后面的列无法用到索引,索引最多用于一个范围列;
只要使用了范围查询,后面的索引就不能被使用
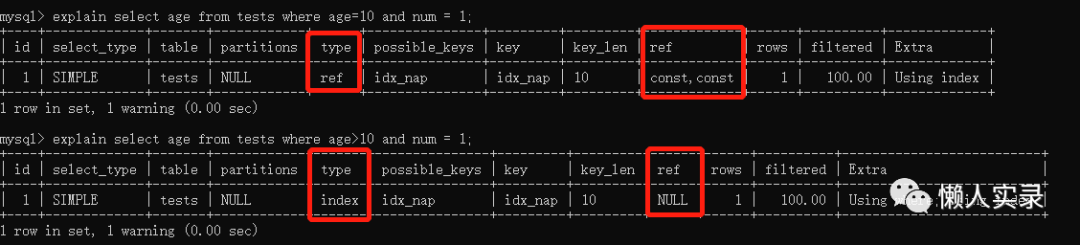
强制类型转换全表扫描
create table user(id int,name varchar(10),phone varchar(11));alter table user add index idx_1(phone)explain select * from user where phone=13800001234;explain select * from user where phone='13800001234';复制
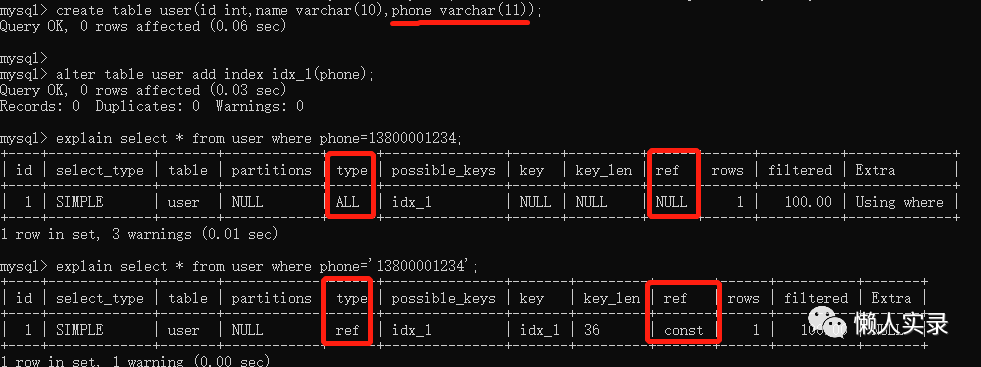
查询字段phone类型为varchar直接用数字去查询mysql会强制转换成字符串,执行计划type为ALL,possible_keys显示说明可能会用idx_1这个索引,实际key为null 没有使用索引查询,我们在使用查询的时候尽量使用同等类型进行查询,不要让mysql帮忙转换类型
更新十分频繁,数据区分度不高的字段上不宜建立索引
1、更新会变更B+树,更新频繁的字段建议索引会大大降低数据库性能
2、类似于性别这类区分不大的属性,建立索引是没有意义的,不能有效的过滤数据,
3、一般区分度在80%以上的时候就可以建立索引,区分度可以使用 count(distinct(列名))/count(*) 来计算
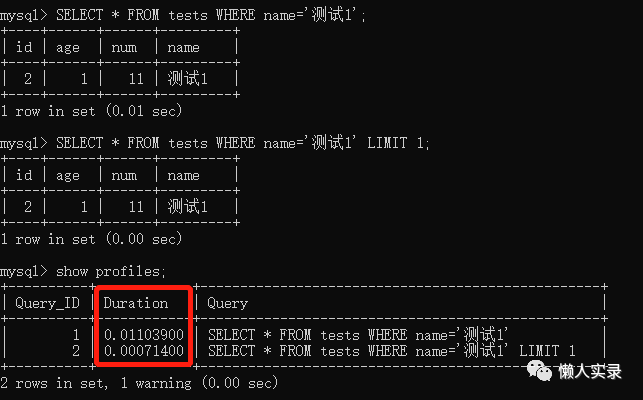
能使用limit的时候尽量使用limit
当你明确知道只有一条数据,使用limit只要找到了对应的一条记录,就不会继续向下扫描了,避免全表扫描,效率会大大提高。
单表索引建议控制在5个以内
索引并不是建立越多越好,要根据实际业务需求,索引建立的越多,意味着树越大,IO量也就越大,建议尽量控制在5个以内,合理使用索引
