




[TOC]
一、对LSM-TREE的理解
1.我们通过一道题目来理解一下数据的存放与数据读取效率的关系
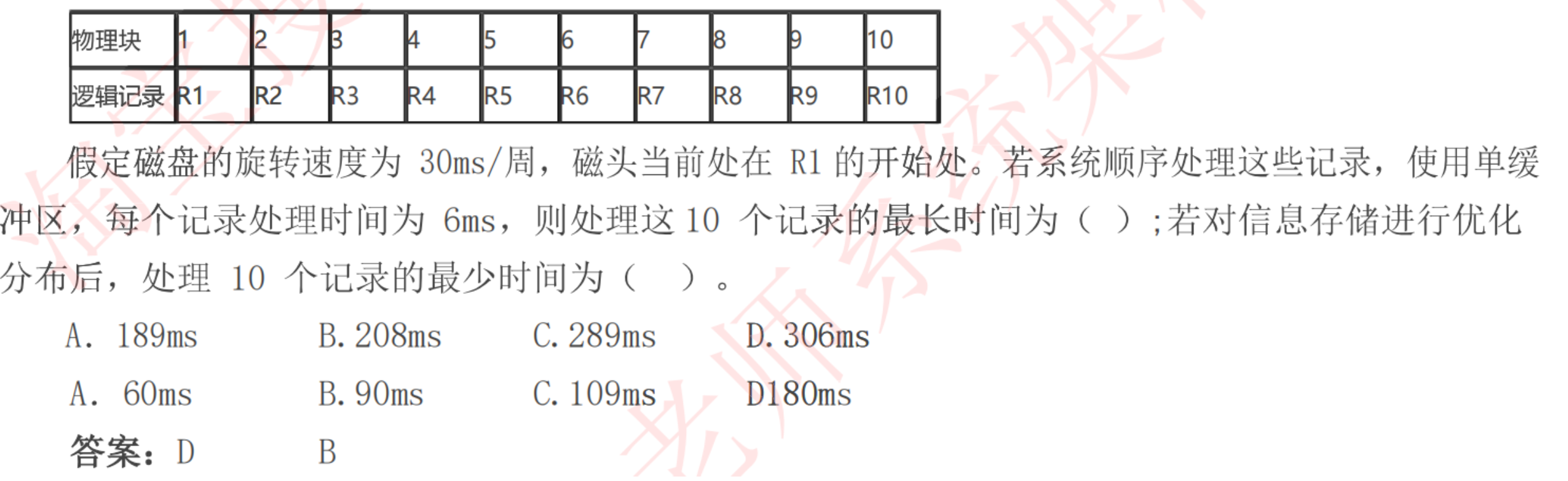
图中物理块和逻辑记录为为一一对应,由于磁盘旋转速度为30ms/周,每个块读取需要3ms(30ms/10块),而每个记录处理时间为6ms。由此我们可以知道,处理一条逻辑记录的时间是9ms,既读取一个物理块的耗时为9ms;
故当我们读取第一个物理块的时候,耗时3ms,此时磁头已经转到第二个物理块位置(即R2记录);
当处理第一个物理块的时候,耗时6ms,此时磁头已经转到第四个物理块位置(即R4记录);
当处我们读区第二个物理块的时候,则需要磁盘头重新转到第二个物理块初,期间耗时3*8=24ms;
总共耗时24+9=33ms
同理,读区第二个物理块的时候,耗时3ms,此时磁盘头转到第三个物理块位置(即R3记录);当处理第二个物理块的时候耗时6ms,此时磁盘头已经转到第五个物理块位置(即R5记录);
依次类推,如果我们完整的读取出R1-R10的记录,则需要9*33ms+9ms=306ms。
那么我们如何对信息存储进行优化分布呢?优化分布后读取处理10条记录的最少时间是多少呢?其实从上面的处理思路来看
R1记录存放在BLOCK1;
R2记录存放在BLOCK4;
R3记录存放在BLOCK7;
R4记录存放在BLOCK10;
R5记录存放在BLOCK3;
R6记录存放在BLOCK6;
R7记录存放在BLOCK9;
R8记录存放在BLOCK2;
R9记录存放在BLOCK5;
R10记录存放在BLOCK8
如图:

这样,读取处理完10条记录只需90s即可。
通过上面的题目,我们可以了解到在计算机系统中,数据均是以磁头寻道的方式来顺序完成数据的读取操作;如果我们想要更快速的读取数据,往往需要将数据以离散的方式写到不同的磁盘块中,从而减少磁头在读取数据时候的寻道路径,增加读取数据的效率。
但是,这种方式却对数据写操作并不友好,因为此时写数据动作是离散的。
基于上述理论思想,在数据库中通常有二叉树、哈希、B TREE、B+ TREE等索引方式加快数据的读取,而这些方式均要求数据必须按照特定的方式进行存放,这就可能会导致在写数据的时候产生大量的随机写,降低写入效率。
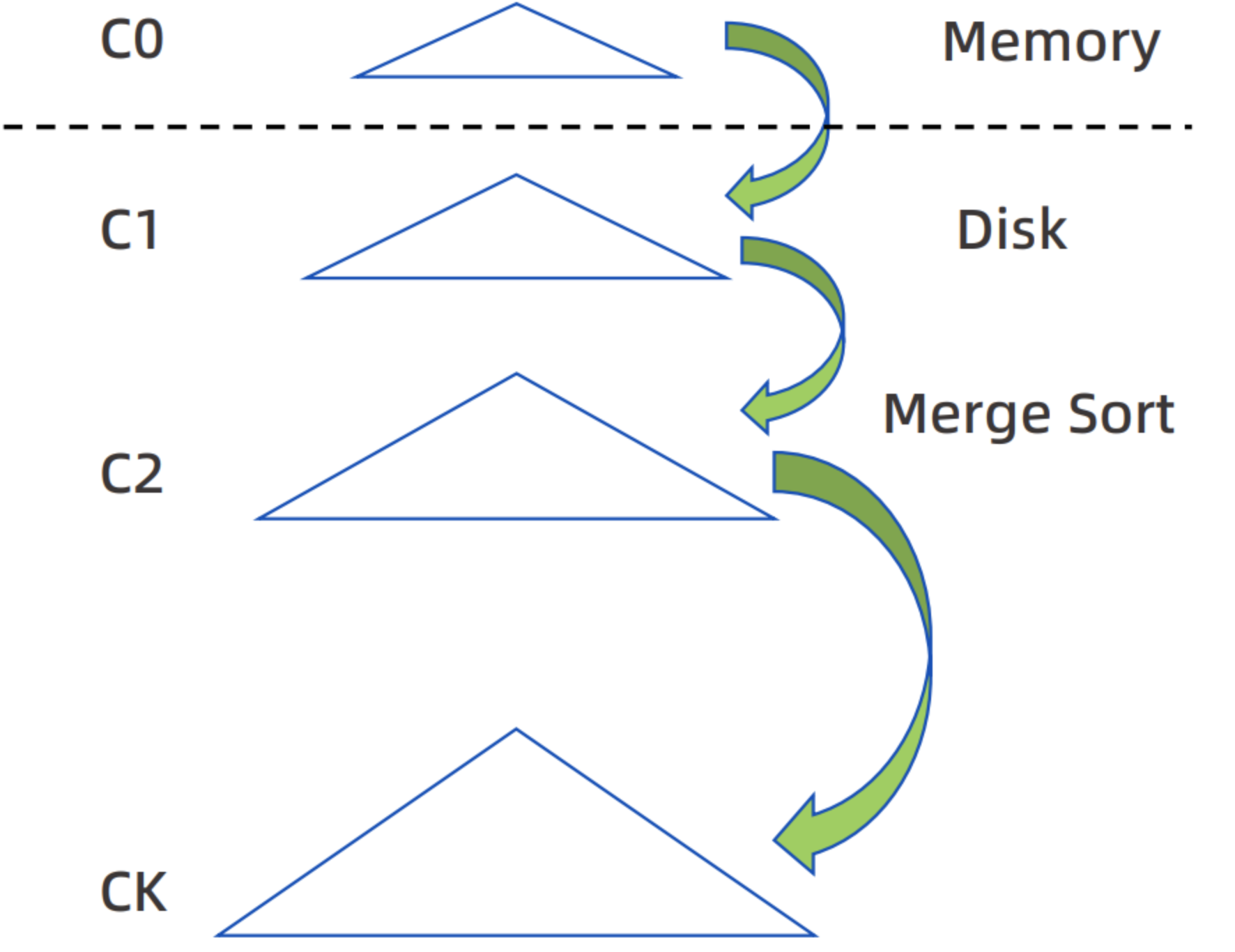
LSM-TREE(日志结构合并树),则是分层、面向磁盘有序的的数据结构,它核心的特点就是利用磁盘的顺序写来提高些磁盘写时候的性能。
但是同样,顺序写的方式一定会降低了数据读取的效率。因此,为了解决在LSM-TREE中数据读取的效率,我们则需要借助大量的内存进行数据缓存,当数据在缓存中积累一定的数量后,再使用合并的方式将内存中的数据与磁盘中的数据进行合并,此时内存的数据会批量追加到磁盘中。
2.简单对LSM-TREE结构的写过程步骤进行描述
1.当修改数据的时候,会先将修改记录写入到预写日志中(WAL日志),该动作主要是用于故障时可以通过lsn进行数据恢复;
2.将修改的记录以的形式写到内存C0中;
3.当C0达到一定的大小后,则会将内存C0和磁盘C1中的数据以进行排序合并,且顺序写到磁盘中,替换掉旧的C1文件;
4.当C1文件达到一定的大小后,则会将磁盘C1和磁盘C2中的数据进行排序合并,且顺序写到磁盘中,替换掉旧的C2文件;
5.同理一定程度后,C2会与C3合并,直到Ck-1与Ck合并。
当进行数据读取的时候,则首先会从C0中查找数据,如果C0中没有,则需要到C1中查找数据,一次类推,直到在Ci曾找到数据
因此,通常在LSM-TREE中,会存在两个主要组成结构:一个是MemTable,另一个是SSTable。
二、Oceanbase的LSM-TREE实现
1.Oceanbase的MemTable
Memtable是属于MemStore内存构成的一部分,用于存储事物修改数据后的值(dml的改变值)。
oceanbase通过lsm-tree的结构,对数据库的写增加了效率,但是这种方式回对数据的读取造成效率降低的影响,因此,oceanbase对数据读取也做了一些优化。
在oceanbase的memtable中,则采取了双索引结构,即B+ TREE索引和Hash索引,其中B+ TREE能在读取数据中对整个的范围扫描有很大的效率提升;而hash索引则可以对单值(等值)条件的数据读取有很大的效率提升。
在数据库执行事务操作的时候,MemTable会自动维护B+ tree和Hash的一致性。
在读取旧的数据,只需要顺着内存中的反向指针向前回溯即可,类似于在内存中进行undo操作。
2.OceanBase的合并操作
oceanbase中的lsm-tree只有C0和C1两层,即MemTable和SSTable。
这个合并过程,涉及到的范围是整个oceanbase集群。也就是说,当达到某一个条件的时候,整个oceanbase所有租户中的MemTable会做大版本冻结(major freeze),剩余的内存则继续存放dml的增量数据。
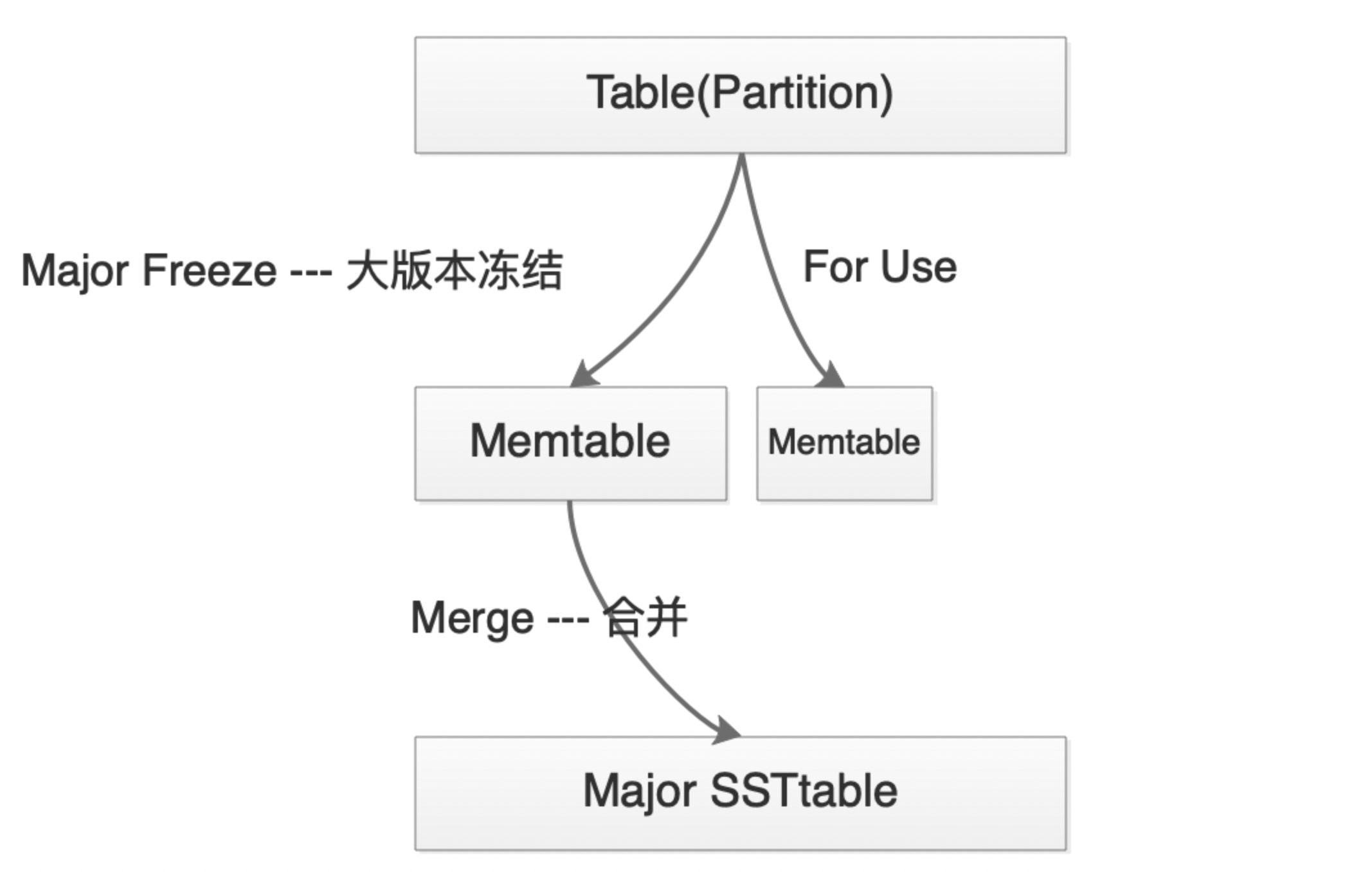
oceanbase的整个合并分为三种方式:
1.全量合并:合并时间长,消耗大量的i/o和cpu资源,需要把所有MemTable中的数据取出,批量写到sstable磁盘中;
2.增量合并:只读取被修改的宏块数据,和动态数据归并,并写入磁盘,对于为修改过的宏块,则直接重用;
3.渐进合并:每次合并一部分,若干次轮次合并后,数据整体被重写;
大版本的合并,由于是全局操作,需要从内存中将数据批量顺序写入到磁盘中,因此会占用大量的i/o、cpu等资源,故可能会比较长的时间对整个集群的消耗、性能有较大的影响。
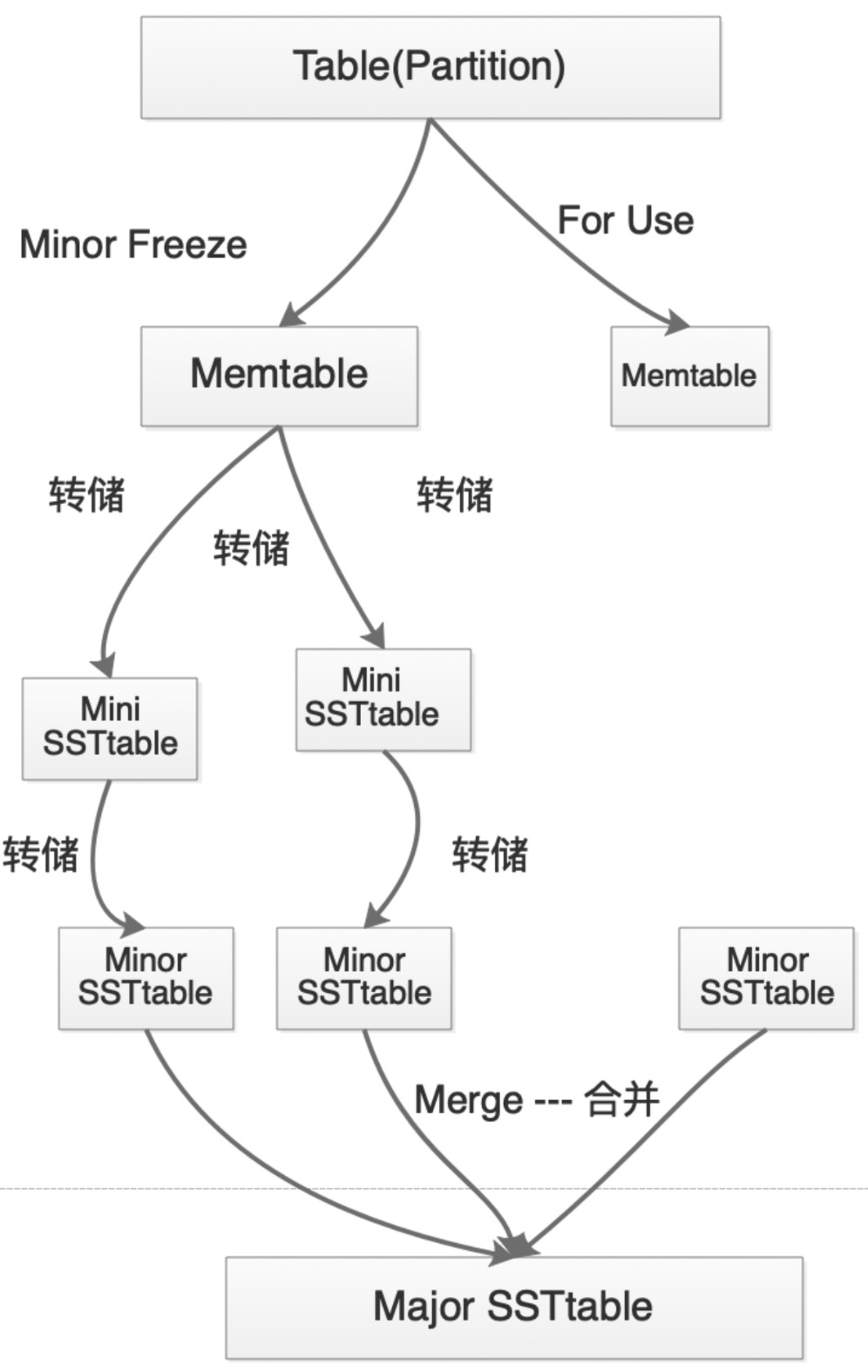
3.OceanBase的转储操作
由于oceanbase的2层合并结构是全局合并,对整个集群的i/o及cpu有较大的影响。因此,当oceanbase中某一租户触发合并操作后,可能其他租户也会收到比较大的影响,故oceanbase在C1层,引入了转储的机制。
基本的转储机制中,oceanbase会先将Memtable(C0层)中的数据做小版本的冻结,即minor freeze,然后将其写入到磁盘(C1层)的转储文件里,但不与sstable进行合并;当转储完成后,Memtable的内存会被清空并重新使用;每一次转储后的转储文件会与前一次的转储文件进行合并,而最终的转储文件将在达到某一条件后,与sstable进行合并。
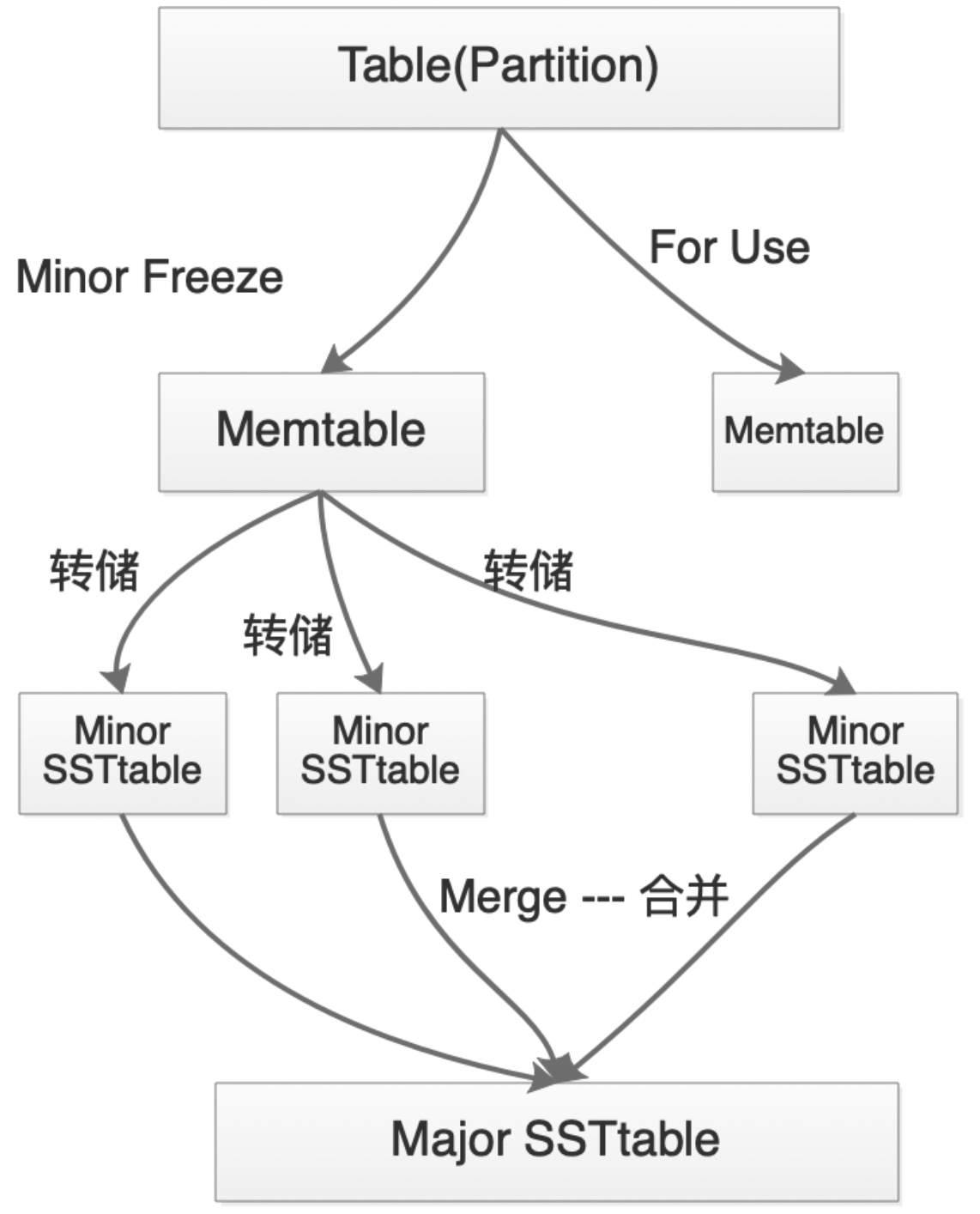
转储是oceanbase数据库为了优化转储效率,oceanbase引入了多层转储机制,即在C1层多引入了L0层,即oceanbase整体的转储合并架构由3层(memtable(C0层)+minor ssttable(L1层)+ssttable(L2层)),增加到了4层(memtable(C0层)+mini ssttable(L0层)+minor ssttable(L1层)+ssttable(L2层))。
四、转储及合并操作的相关参数、查询、影响
1.转储合并的相关参数
参数minor_compact_trigger,显示了租户中的mini ssttable的总数,即触发小合并的迷你合并次数,默认值是2,其范围是0-16;
参数major_compact_trigger,等同于minor_freeze_times,显示了memtable转储的次数上限,当达到该参数设定的值后,数据库会触发major合并操作,即多少次小合并,触发一次全局合并,默认值是100,其范围是0-65535;
参数freeze_trigger_percentage,表示每个租户的MemStore的使用率所达到的冻结阈值。当租户的memstore的使用率达到该阈值后,就会针对该租户触发转储操作,默认值是80,该值的范围是0-100;
参数minor_freeze_times,表示minor ssttable冻结的最大次数,当minor ssttable冻结该参数规定次数后,则会触发major合并,即多少次小合并(转储),触发一次全局合并,与major_compact_trigger相同,默认值是100,其范围是0-65535;当该值为0的时候,则表示关闭小合并(转储),此时只要任何一个租户的memsotre使用情况达到该租户的freeze_trigger_percentage值的时候,就会触发全局合并。
参数minor_merge_concurrency,表示当前工作线程中minor转储的并发度,默认值是0,其范围是1-16;
参数major_freeze_duty_time,表示主合并的定时时间,即在指定时间点,整个集群将进行major主合并,此时会消耗较大的I/O、CPU。默认值是2:00,范围是00:00-24:00,修改该参数可以通过以下方式进行:
查询:show parameters like '%major_freeze_duty_time%'
修改:alter system set major_freeze_duty_time = '04:00';
查询上述参数:
select *
from oceanbase.__all_virtual_sys_parameter_stat
where name in('minor_compact_trigger','major_compact_trigger','freeze_trigger_percentage','minor_freeze_times');
注:v3版本中,查看集群参数的表为__all_virtual_sys_parameter_stat,我们可以通过以下方式找到该表的元数据:
select table_catalog,
table_schema,
table_name,
table_type,
engine,
version,
create_options,
table_comment
from tables
where table_name = '__all_virtual_sys_parameter_stat'
and table_owner = 'oceanbase';
2.为什么引入转储机制?
主要解决三个问题:
- 大版本合并对集群的i/o及cpu资源消耗过大,导致集群性能影响较大,可能影响在线业务;
- 单租户的MemStore使用率比较高的时候会触发大版本合并,可能会对其他租户造成影响;
- 合并是将MemStore的数据合并到SSTtable中,消耗的时间比较长,可能导致无法及时释放MemStore,导致数据库无法写入。
但转储也会带来一些问题:
- 在LSM-tree中,转储的层级会增加,查询数据层级增多,查询链路会比较长,查询性能会变差;
- 冗余数据会增加,会占用更多的磁盘空间;
3.常用的控制转储和合并的配置:
1.减小freeze_trigger_percentage的值,提高转储的次数,使Memstore尽快释放,降低memstore写满的风险;
2.增大minor_freeze_times的值,减少major合并的次数,避免在业务高峰期进行major合并,即采用业务低峰期进行major合并或手动合并。
4.转储操作的相关操作和查询:
1)手动转储:
alter system minor freeze tenant=('tent_name1','tent_name2') partition_id='partidx%partcount@tableid' server=('ip1:port','ip2:port')
注:
tenant指定租户名字;
partition_id指定分区;
server指定转储的节点IP和端口;
如果什么都不指定,则对所有租户进行转储。
例:
alter system minor freeze;
alter system minor freeze tenant=('wx_tenant');
alter system minor freeze tenant=('wx_tenant') server=('172.16.131.217:2882')
2)查看转储记录:
转储记录可以从两个视图里面查看:
1.__all_server_event_history
注:这个视图中存储的是,当memstore达到freeze_trigger_percentage值的时候,触发的租户级别自动转储的记录内容。
2.__all_rootservice_event_history
注:这个视图中,存储的是我们进行手动转储时的记录内容。
例:
--自动转储记录
select *
from oceanbase.__all_server_event_history
where event like '%merge%'
or event like '%minor%';
--手动转储记录
select *
from oceanbase.__all_rootservice_event_history
where event like '%minor%';
5.合并(major)的触发方式:
1)参数触发:
一是租户的转储次数已经达到了minor_freez_times的阈值,二是租户的memstore的使用率达到freeze_trigger_percentage时,会触发合并操作。即默认情况下:
minor_freez_times=100 && freeze_trigger_percentage=80,
其中,我们可以通过gv$memstore或着__all_virtual_tenant_memstore_info查看两个当前值;
两个基表中,分别能够查询到以下内容:
1)租户id;
2)observer服务器ip;
3)observer端口;
4)租户中活动的已使用的memstore大小;
5)租户中总共使用的memstore大小;
6)租户中转储合并的memstore大小值为多少;
7)租户中memstore的总大小;
8)转储的次数;
其中,
查询freeze_trigger_percentage参数:
select (active/mem_limit) * 100 from gv$memstore;
查询minor_freez_times参数:
select freeze_cnt from gv$memstore;
综合查询(可以判断此时是否转储或是否合并):
select ten.tenant_name,
mem.ip,
mem.port,
mem.active,
mem.mem_limit,
mem.freeze_cnt,
100 *(active/mem_limit) memstore_active_percentage
from gv$memstore mem, __all_tenant ten
where ten.tenant_id=mem.tenant_id;

2)手动触发:
触发命令:
alter system major freeze;
可以通过__all_zone来查看major合并状态:
select * from __all_zone where name='merge_status';
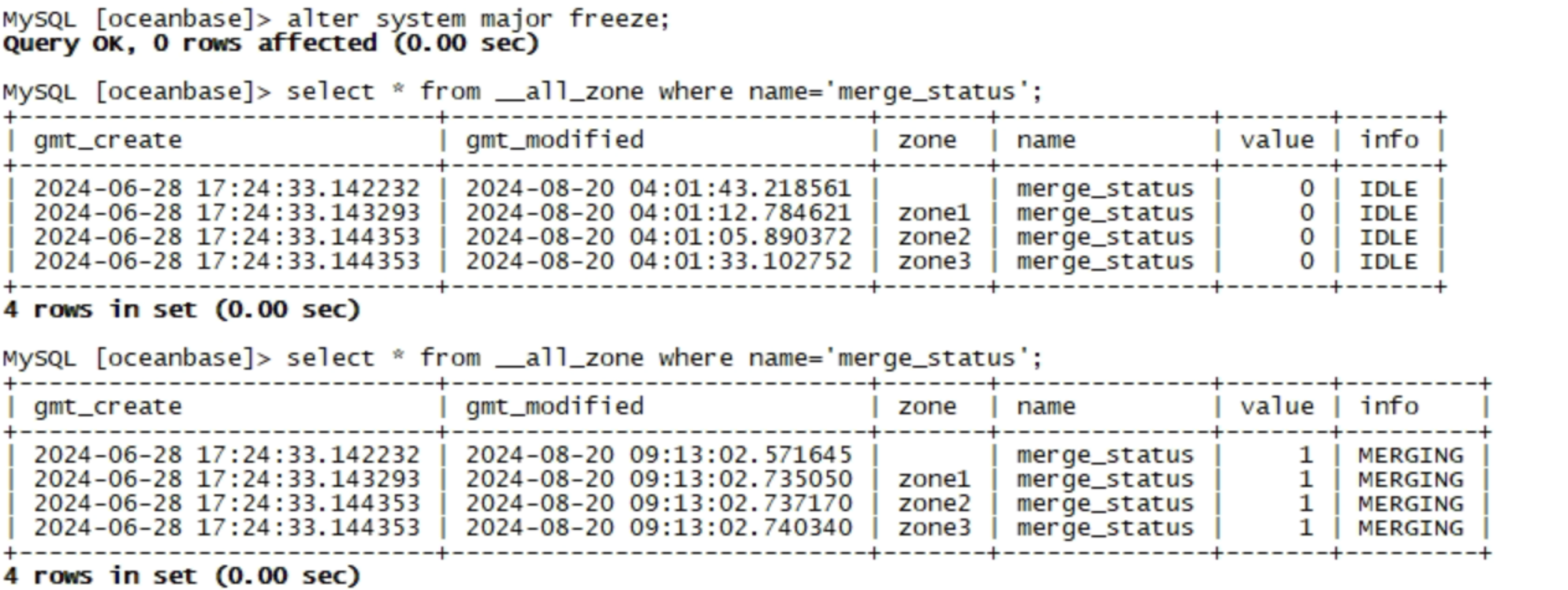
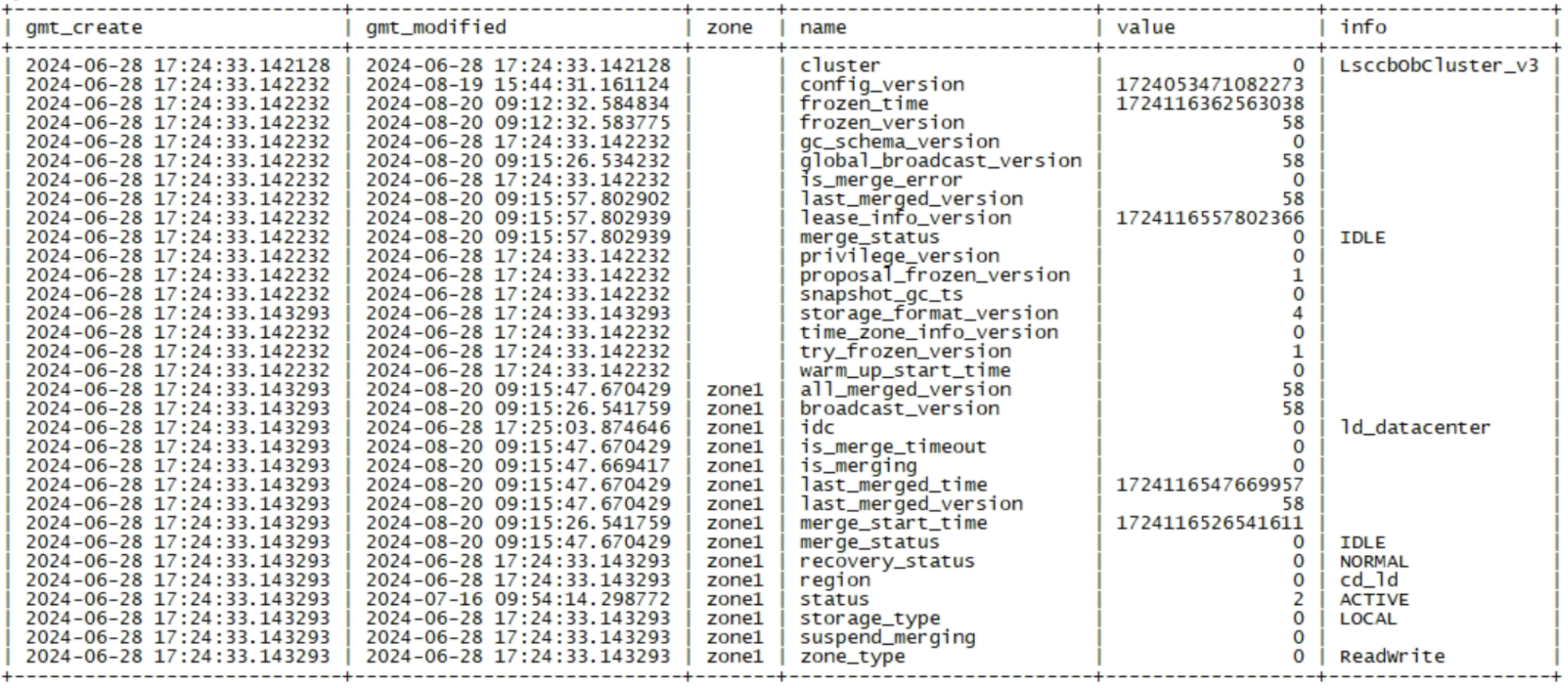
__all_zone表中,包含了整个集群和各个zone的各类动态、静态信息,包括:集群信息,冻结时间,冻结版本,合并是否异常,最近一次的合并时间,合并状态,广播版本,最后一次合并版本、合并是否超时(超时时间可以通过zone_merge_timeout参数设置,默认是3小时)等。
select * from __all_zone where zone='' or zone='zone1';
3)定时触发:
定时触发合并可以通过参数major_freeze_duty_time设置,默认是2点,范围是00:00-24:00,修改该参数可以通过以下方式进行:
alter system set major_freeze_duty_time='04:00';
6.轮转合并:
1)轮转合并的引入:
根据上面的描述,由于合并是全局操作,当进行合并的时候,不论我们通过达到阈值方式、手动方式、定时方式进行合并都会给ob集群中节点的cpu、内存造成压力,影响在线业务。假设我们的系统白天在跑OLTP的交易。晚上又要进行跑批供数操作(银行系统中的核心系统基本这样使用),那么很有可能不论我在何时进行合并,都会对业务有一定的影响。
而oceanbase在正常情况下会具有三副本,每三个副本中都会有相应的leader提供服务,而不同的副本分布在不同的zone中。因此,oceanbase引入了轮转合并的机制,即可以针对zone的级别进行合并。当我们在某个zone上进行合并的时候,那么该zone上的leader数据副本可以被切换到另一个zone上的数据副本为leader并提供服务;此时,该zone上没有流量,则可以放心进行合并。合并完成后,再将流量切回,合并其他节点,直到所有合并结束。
2)控制轮转合并的参数:
enable_merge_by_turn
show parameters like '%enable_merge_by_turn%';

3)轮转合并的意义和影响:
1)轮转合并可以避免合并对在线业务的影响;
2)轮转合并可能导致合并时间增长;
3)轮转合并回对大事物有印象。
7.每日合并的操作的方式及相关设置
对于每日合并的操作,我们可以通过以下三个参数进行控制,最终可以形成多种合并策略:
1)enable_manual_merge表示是否开启手动合并;
2)enable_merge_by_turn表示是否开启自动轮转合并;
3)zone_merge_order表示指定自动轮转合并的顺序;
4)zone_merge_concurrency表示自动轮转合并的并发度。
合并策略则可以分为手动合并和自动合并两种,其中自动合并又可以分为自动轮转合并和自动非轮转合并,自动轮转合并又分为自动轮转合并和指定顺序的轮转合并。
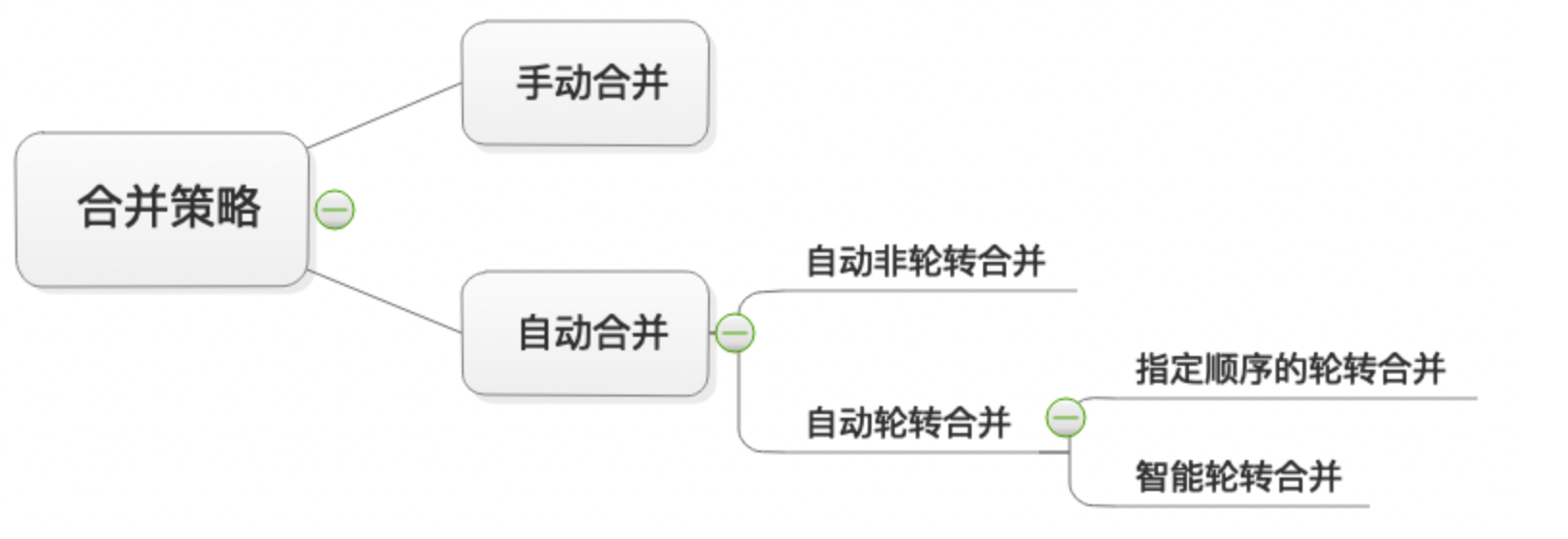
如何使用指定顺序的轮转合并:
1.关闭手动合并:
alter system set enable_manual_merge=false;
2.启用自动轮转合并:
alter system set enable_merge_by_turn=true;
3.指定轮转合并的顺序:
alter system set zone_merge_order='zone1,zone2,zone3';
注:当我们指定轮转合并的顺序时,我们只需要把zone_merge_order设置为空即可。
五、存储相关的其他参数
zone_merge_timeout:
表示合并超时时间,默认是3小时。如果某个zone超过改时间,则状态变为timeout;
data_disk_usage_limit_percentage:
定义数据文件最大可以写入的百分比,默认是90%,当数据盘使用率超过阈值之后,合并任务则会为error状态,合并任务失败。此时需要扩大数据盘大小,并增大数据盘使用率阈值;
datafile_disk_percentage:
定义数据盘空间使用阈值(data_dir所在磁盘空间的百分比),默认时90%;
datafile_size:
表示数据文件大小,与data_disk_usage_limit_percentage参数配合使用的时候,数据文件大小则已该参数值为准;
merge_thread_count:
表示用于合并的线程数,默认是0;
max_kept_major_version_number:
用于设置ssttable保留合并数据的个数,默认是2,修改的值越大,可保留的版本越多,但占用的空间越大,可以通过__all_vitural_partition_sstable_image_info表来查询保留的major版本:
select zone,
svr_ip,
svr_port,
major_version
from __all_virtual_partition_sstable_image_info;
当我们想要查历史版本的数据时候,实现类似于MVCC的历史版本数据查询的时候,则可以通过增加frozen_version(major_version)的hint进行查询,例:
select /*+frozen_version(57)*/ * from t1;
