




 ,那么就开始今天的学习吧。
,那么就开始今天的学习吧。
中文名词

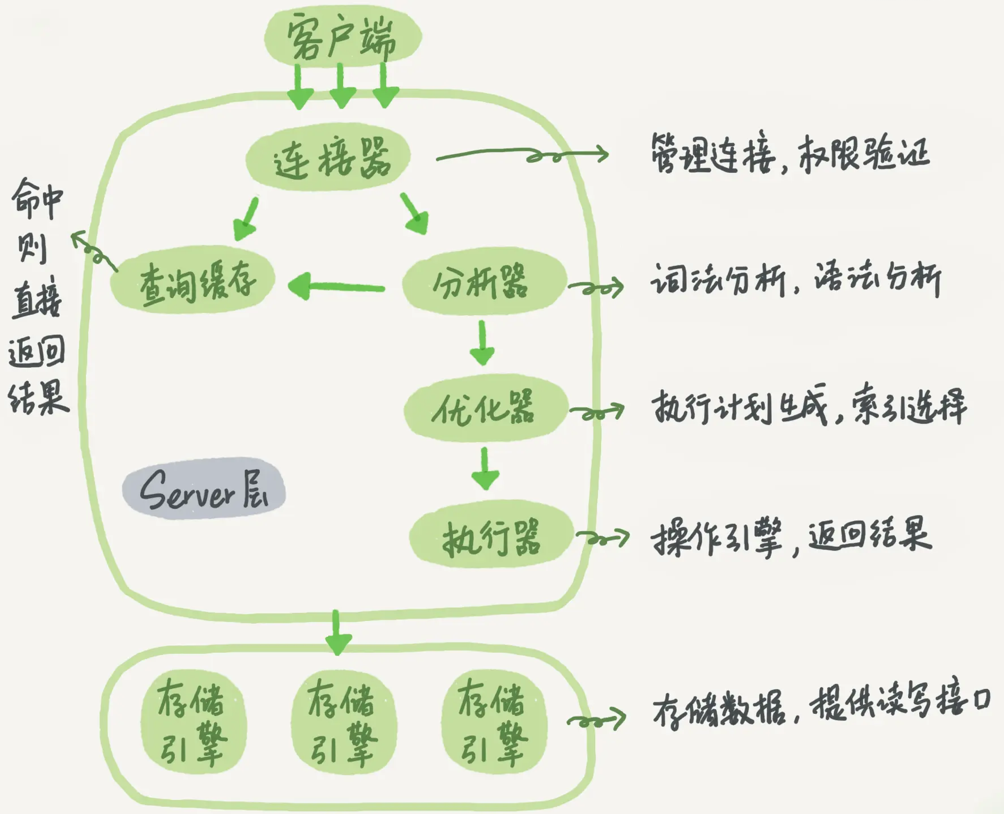
SQL优化内容主要和Server层的优化器息息相关,根据图中的SQL执行流程,经过了连接器、分析器后,MySQL就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(JOIN)的时候,决定各个表的连接顺序。
就像我们之前学习的MySQL之数据页结构,访问数据可以通过Slot快速定位,也可以通过记录与记录间的链表扫描定位。这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案。
优化器在制定执行方案的同时,也会对SQL语句进行一些基于规则的优化。
查询重写:MySQL依据一些规则,竭尽全力的把执行效率极低的语句形式转换成某种可以比较高效执行的形式,这个过程被称作查询重写。
派生表/衍生表:放在FROM子句中的子查询本质上相当于一个表,但又和我们平常使用的表有点儿不一样,把这种由子查询结果集组成的表称之为派生表。
e.g.:
SELECT team_id+1,player_name FROM (SELECT team_id,player_name FROM player WHERE player_id >= 10001 AND player_id <= 10010) AS t;复制
物化延迟:在查询中真正使用到派生表时才会去尝试物化派生表,而不是还没开始执行查询呢就把派生表物化掉。 驱动表:连接查询中,第一个需要查询的表称之为驱动表。 被驱动表:连接查询中,根据驱动表产生的结果集中的每一条记录,分别需要到除驱动表之外的表中查找匹配的记录,那么除驱动表之外的表称之为被驱动表。 连接条件:放到ON子句中的过滤条件也称之为连接条件。
英文名词
移除不必要的括号:
((a = 5 AND b = c) OR ((a > c) AND (c < 5)))复制
会转换成:
(a = 5 and b = c) OR (a > c AND c < 5)复制
constant_propagation:常量传递
a = 5a = 5 AND b > a复制
会转换成:
a = 5 AND b > 5复制
equality_propagation:等值传递
a = b and b = c and c = 5复制
简化为:
a = 5 and b = 5 and c = 5复制
trivial_condition_removal:移除没用的条件
(a < 1 and b = b) OR (a = 6 OR 5 != 5)复制
b = b恒为TRUE,5 != 5恒为FALSE,简化后:
(a < 1 and TRUE) OR (a = 6 OR FALSE)复制
继续简化为:
a < 1 OR a = 6复制
表达式计算:
a = 5 + 1 → a = 6复制
有一点需要注意,如果某个列并不是以单独的形式作为表达式的操作数时,比如出现在函数中、有正负号的情况:
ABS(a) > 5 或 -a < -8复制
优化器是不会尝试对这些表达式进行化简的。所以为了避免使用不到索引的情况,如果可以的话,最好让索引列以单独的形式出现在表达式中。
comparison_operator:比较运算符。 constant tables:常量表,两种查询(①查询的表中一条记录没有,或者只有一条记录[只用于Memory、MyISAM存储引擎]。②使用主键等值匹配或者唯一二级索引列等值匹配作为搜索条件来查询某个表。)花费的时间特别少,少到可以忽略,所以也把通过这两种方式查询的表称之为常量表。 reject-NULL:空值拒绝,把这种在外连接查询中,指定的WHERE子句中包含被驱动表中的列不为NULL值的条件称之为空值拒绝。 Materialize:物化,将子查询结果集中的记录保存到临时表的过程称之为物化。 Materialized_Table:物化表,存储子查询结果集的临时表称之为物化表。(正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的有B+树索引),通过索引执行IN语句判断某个操作数在不在子查询结果集中变得非常快,从而提升了子查询语句的性能。并且物化表中的记录是不重复的。) Derived_Table:派生表/衍生表,把子查询放在外层查询的FROM子句后,那么这个子查询的结果相当于一个派生表。 fanout:扇出,把对驱动表进行查询后得到的记录条数称之为驱动表的扇出。 condition filtering:涉及表连接查询,含有多个匹配条件,①如果使用全表扫描的方式进行单表查询,那么计算驱动表扇出时需要猜满足搜索条件的记录有多少条。②如果使用索引执行单表扫描,那么计算驱动表扇出时候需要猜满足除使用到对应索引的搜索条件外的其他搜索条件的记录有多少条。这个猜的过程称之为condition filtering。 Index Condition Pushdown:索引条件下推,使用一个二级索引、多个匹配条件的情况,根据第一个条件定位到二级索引中对应的二级索引记录,先不着急回表,而是再检测一下该记录是否满足第二个条件,然后将满足条件的记录一起回表。这个改进称之为索引条件下推。 filesort:文件排序,在内存中或者磁盘上进行排序的方式统称为文件排序。 ROR:Rowid Ordered Retrieval,按照有序主键值回表取记录。 Index Extention:索引扩展,索引的最后都会跟上主键值,5.6.9之后,优化器可以自动识别索引末尾的主键值。 Scala Subquery:标量子查询,只返回一个单一值的子查询称之为标量子查询。
连接查询相关名词
Semi-Join:半连接,对于外层查询表的某条记录来说,我们只关心在子查询表中是否存在与之匹配的记录是否存在,而不关心具体有多少条记录与之匹配,最终的结果集中只保留外层查询表的记录。
Table pullout:子查询中的表上拉,当子查询的查询列表处只有主键或者唯一索引列时,可以直接把子查询中的表上拉到外层查询的FROM子句中。 DuplicateWeedout execution strategy:重复值消除,使用临时表消除semi-join结果集中的重复值的方式称之为DuplicateWeedout。 LooseScan execution strategy:松散索引扫描,相同的二级索引记录,也只需要取第一条记录的值到外层查询表中找匹配的记录,这种虽然是扫描索引,但只取值相同的记录的第一条去做匹配操作的方式称之为松散索引扫描。 Semi-join Materialization execution strategy:半连接物化执行策略,我们之前介绍的先把外层查询的IN子句中的不相关子查询进行物化,然后再进行外层查询的表和物化表的连接本质上也算是一种semi-join,只不过由于物化表中没有重复的记录,所以可以直接将子查询转为连接查询。 FirstMatch execution strategy:首次匹配,FirstMatch是一种最原始的半连接执行方式,跟我们年少时认为的相关子查询的执行方式是一样一样的,就是说先取一条外层查询的中的记录,然后到子查询的表中寻找符合匹配条件的记录,如果能找到一条,则将该外层查询的记录放入最终的结果集并且停止查找更多匹配的记录,如果找不到则把该外层查询的记录丢弃掉;然后再开始取下一条外层查询中的记录,重复上边这个过程。 非半连接查询优化,正常连接查询的相关名词:
Nested-Loop Join:Simple Nested-Loop Join(笛卡尔积),嵌套循环连接,驱动表只访问一次,但被驱动表却可能被多次访问,访问次数取决于对驱动表执行单表查询后的结果集中的记录条数的连接执行方式称之为嵌套循环连接。 Block Nested-Loop Join:简称BNL,基于块的嵌套循环连接,这种加入了join buffer的嵌套循环连接算法称之为基于块的嵌套连接(Block Nested-Loop Join)算法。 Index Nested-Loop Join:简称NLJ,可以使用被驱动表索引的连接算法。
子查询相关名词
按返回结果集区分:
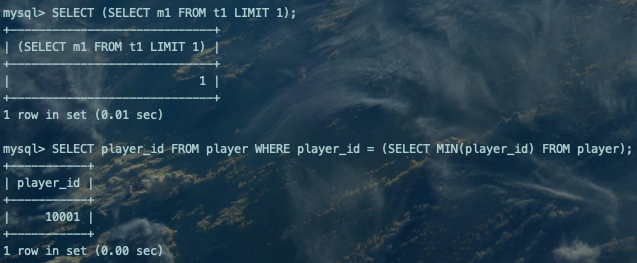
标量子查询:只返回一个单一值的子查询称之为标量子查询。【单列单行】
e.g.:
SELECT (SELECT m1 FROM t1 LIMIT 1);SELECT player_id FROM player WHERE player_id = (SELECT MIN(player_id) FROM player);复制
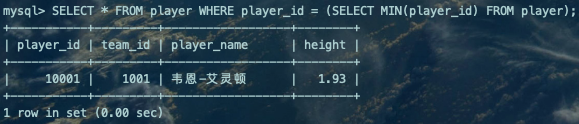
行子查询:顾名思义,就是返回一条记录的子查询,不过这条记录需要包含多个列(只包含一个列就成了标量子查询了)。【多列单行】
SELECT * FROM player WHERE player_id = (SELECT MIN(player_id) FROM player);复制
列子查询:列子查询自然就是查询出一个列的数据,不过这个列的数据需要包含多条记录(只包含一条记录就成了标量子查询了)。【单列多行】
e.g.:
SELECT player_id FROM player WHERE player_id IN (SELECT player_id FROM player);复制

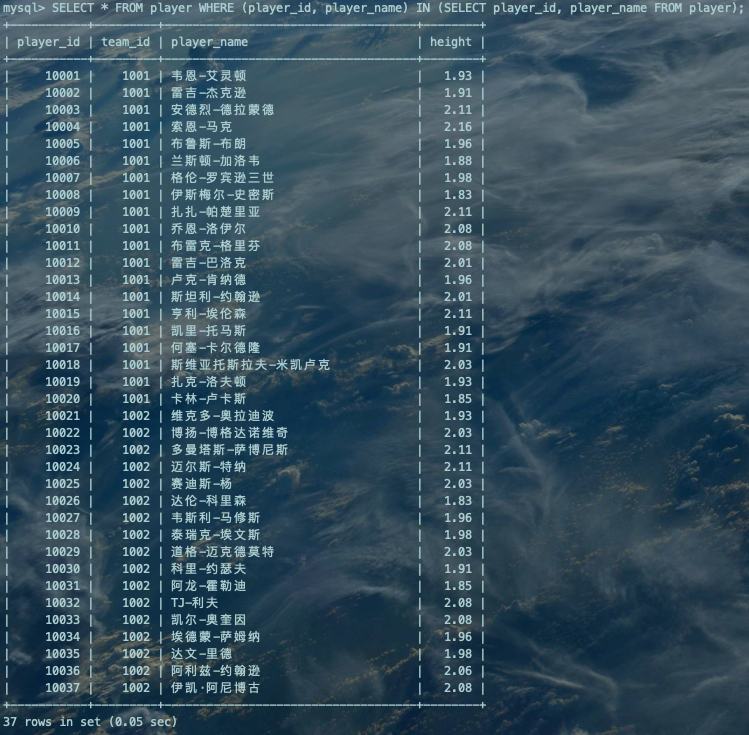
表子查询:顾名思义,就是子查询的结果既包含很多条记录,又包含很多个列。【多列多行】
e.g.:
SELECT * FROM player WHERE (player_id, player_name) IN (SELECT player_id, player_name FROM player);复制
按与外层查询关系来区分:
不相关子查询:如果子查询可以单独运行出结果,而不依赖于外层查询的值,我们就可以把这个子查询称之为不相关子查询。【子查询和外层查询不相关】
相关子查询:如果子查询的执行需要依赖于外层查询的值,我们就可以把这个子查询称之为相关子查询。
e.g.:
SELECT * FROM player a WHERE a.player_id IN (SELECT b.player_id FROM player b WHERE a.team_id = b.team_id);复制
子查询有一个搜索条件是a.team_id = b.team_id,a.team_id是表a的列,也就是外层查询的列,也就是说子查询的执行需要依赖于外层查询的值,所以这个子查询就是一个相关子查询。)【子查询和外层查询相关,子查询的查询条件包含外层查询涉及表的字段】
小结
参考资料
小孩子4919《MySQL是怎样运行的:从根儿上理解MySQL》

end



