




Vertica 提供导入和导出功能,可让您在两个 Vertica 集群之间移动数据。出于本文档中所述的原因,在集群之间导入和导出数据比通过 STDIN 流式传输数据或使用 vsql 连接更快。
1. 导入和导出:概述
导入和导出过程以镜像方式运行。导出数据的集群执行相当于 SELECT 语句的操作。导入数据的集群执行相当于 COPY 语句的操作。导入/导出操作的机制类似于 INSERT… SELECT … 查询。
本文档将导出数据的集群称为源集群,将导入数据的集群称为目标集群。数据从源集群中的表移动到目标集群中的类似表。这些集群和表可能具有不同的拓扑和其他特征,例如:
- 节点数
- 数据库版本
- 投影数
- 列数据类型
- 分段
- 用户
- 配置设置
为了说明导入和导出的工作原理,本文档中的示例使用了两个 Vertica 集群:
- 源集群:3 个节点(10.100.0.55、10.100.0.66、10.100.0.77)
- 目标集群:2 个节点(10.100.0.88、10.100.0.99)
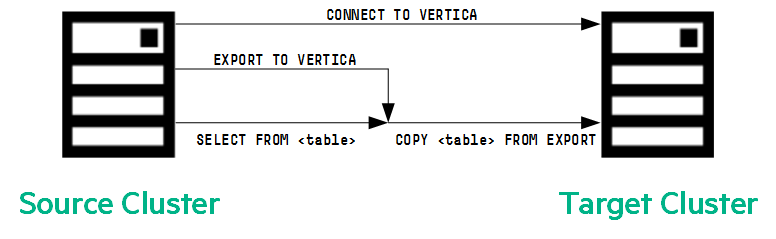
2. 数据导出Export的工作原理
在源集群上,导出操作通常按以下命令执行。
首先,源数据库连接到目标数据库。
然后,源执行 EXPORT TO VERTICA 查询,该查询指定检索要导出到目标的数据的 SELECT 语句:
source=> CONNECT TO VERTICA VerticaDBTarget USER dbadmin PASSWORD '' ON '10.100.0.88',5433;
source=> EXPORT TO VERTICA VerticaDBTarget.tgt_table (n,a,b) AS
SELECT n AS col1, a as col2 , b as col3 from src_table;
源执行上述 EXPORT 语句中的 SELECT 语句以检索要导出的数据。目标创建一个 COPY 语句以连接到源并接收 SELECT 语句的输出。
此 COPY 语句包含目标集群连接到源集群并流式传输数据所需的信息。此信息包括 IP 地址、端口号、数据类型和列名以及编码和压缩信息。
COPY 语句复制在源上执行的 SELECT 语句的输出并将该数据存储在目标上。
下图说明了 EXPORT 过程:
要查看在目标数据库上执行的确切 COPY 语句,请查询 SESSIONS 系统表。由于多个并发 TCP 流正在加载数据,因此此 COPY 语句的执行速度往往比使用 vsql 或从 STDIN 复制数据更快。
target=> SELECT user_name, node_name, current_statement FROM sessions;
user_name | node_name |
-----------+----------------------------+----------------------------------------------------
dbadmin | v_VerticaDBTarget_node0001 | COPY tgt FROM EXPORT ':SendExport explainBits:0 ...
(1 rows)
初始连接到源节点 IP:5434,然后切换到源端的临时端口。
在以下示例中:
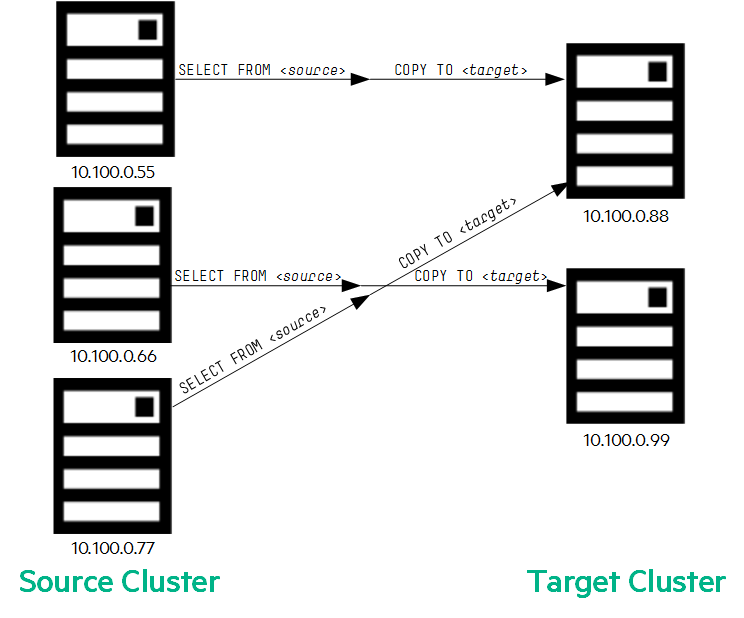
- v_VerticaDBTarget_node0001 正在从 10.100.0.55(源节点 1)和 10.100.0.77(源节点 3)接收数据
- v_VerticaDBTarget_node0002 正在从 10.100.0.66(源节点 2)接收数据
v_VerticaDBTarget_node0001 的工作量是 v_VerticaDBTarget_node0002 的两倍。当源节点和目标节点数量不相同时,导入/导出操作可能需要更长时间。
COPY tgt ( n, a, b ) FROM EXPORT ':SendExport explainBits:0 planNumber:45035996273709640 tag:1000 status: :DataPort ip_source:2 oid:45035996273704982 name:v_VerticaDBTarget_node0001 ip:10.100.0.55 address_family:0 port:5434 . ports: { :DataPort ip_source:2 oid:45035996273704982 name:v_VerticaDBTarget_node0001 ip:10.100.0.55 address_family:0 port:5434 . :DataPort ip_source:2 oid:45035996273721216 name:v_VerticaDBTarget_node0002 ip:10.100.0.66 address_family:0 port:5434 . :DataPort ip_source:2 oid:45035996273721220 name:v_VerticaDBTarget_node0003 ip:10.100.0.77 address_family:0 port:5434 . } db:VerticaDBSource table:tgt colnames: { :string _:n . :string _:a . :string _:b . } columns: { :DataType oid:9 type:6 len:3 typmod:7 . :DataType oid:9 type:6 len:4997 typmod:5001 . :DataType oid:9 type:6 len:4997 typmod:5001 . } rle: { :vbool _:0 . :vbool _:0 . :vbool _:0 . } isCompressed:0 . '
netstat 命令显示目标系统 10.100.0.88 和 10.100.0.99 上的接收队列正在主动接收数据。10.100.0.88 正在接收来自 10.100.0.55 和 10.100.0.77 的数据,10.100.0.99 正在接收来自 10.100.0.66 的数据。
[ dbadmin@ip-10-100-0-88 ~]$ netstat -tna -p $(pgrep vertica) | grep ESTABLISHED | grep ":5434"
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 476767 0 10.100.0.88:5434 10.100.0.55:46756 ESTABLISHED 6834/vertica
tcp 457636 0 10.100.0.88:5434 10.100.0.77:59568 ESTABLISHED 6834/vertica
[ dbadmin@ip-10-100-0-99 ~]$ netstat -tna -p $(pgrep vertica) | grep ESTABLISHED | grep ":5434"
tcp 480539 0 10.100.0.99:5434 10.100.0.66:59074 ESTABLISHED 6359/vertica
源集群和目标集群应具有相同数量的节点。
这样做有助于平衡负载,确保没有任何单个节点可以阻止导出操作。
具有相同数量的节点还可以提高数据传输速度。
当源集群和目标集群中的节点数量不同时,多个源可能会将数据发送到一个目标,或者一个源可能会将数据发送到多个目标。
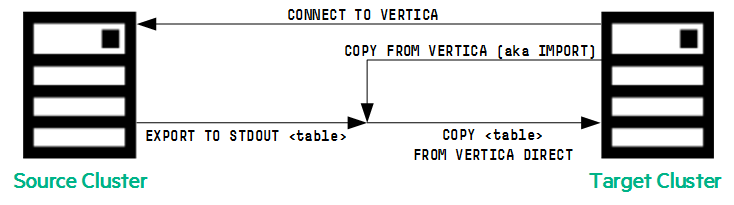
3. 数据导入Import的工作原理
在目标集群上,导入操作通常按以下命令执行。
target=> CONNECT TO VERTICA VerticaDBSource USER dbadmin PASSWORD '' ON '10.100.0.55',5433; CONNECT target=> COPY tgt(n,a,b) FROM VERTICA VerticaDBSource.src(n,a,b) DIRECT;
CONNECT 命令导致从目标集群到源集群的连接。COPY 命令指定要导入的数据。
下图说明了这种情况:
要查看在源数据库上执行的 EXPORT 语句,请查询 SESSIONS 系统表:
source=> SELECT node_name, current_statement, last_statement FROM sessions;
node_name | current_statement | last_statement
----------------------+-----------------------------------------+----------------
v_verticadb_node0001 | export to STDOUT FROM src ( n , a , b )
4. 网络数据压缩
通常,网络不是导入或导出操作的瓶颈。
但是,在某些慢速或低带宽网络上,您可以通过在源集群和目标集群上启用网络数据压缩来加快源集群和目标集群之间的数据传输速度。
如果网络设置不同,您会看到以下错误:
target=> COPY tgt(n,a,b) FROM VERTICA verticadb.src(n,a,b) DIRECT;
ERROR 5520: verticadb compresses network traffic. verticadb2
does NOT compress network traffic. Please change the configuration
to be consistent
HINT: Configuration can be changed using set_config_parameter() function
在源节点和目标节点上启用网络数据压缩。为此,请将 CompressNetworkData 配置参数设置为 1:
=> SELECT SET_CONFIG_PARAMETER('CompressNetworkData',1);
SET_CONFIG_PARAMETER
----------------------------
Parameter set successfully
(1 row)
5. 监控Import和Export的进度
您可以使用目标上的 LOAD_STREAMS 系统表监控导入/导出操作的进度。parse_complete_percent 字段为空,这意味着不需要在目标集群上解析数据。
target=> SELECT read_bytes,parse_complete_percent,unsorted_row_count,sorted_row_count
FROM load_streams WHERE is_executing;
read_bytes | parse_complete_percent | unsorted_row_count | sorted_row_count
------------+------------------------+--------------------+------------------
0 | | 39645696 | 19559826
(1 row)
与使用 COPY 语句加载 CSV 文件(需要解析文件)不同,IMPORT 操作中的 COPY 不需要在目标集群上解析数据,而是将源数据直接流式传输到目标库。
通过查看目标库上的接收行计数器来具体监控进度:
target=> SELECT node_name, counter_name, counter_value, operator_name
from execution_engine_profiles WHERE is_executing='t'
AND counter_name IN ('rows received') AND Operator_name IN ('Import');
node_name | counter_name | counter_value | operator_name
----------------------------+---------------+---------------+---------------
v_VerticaDBTarget_node0001 | rows received | 124257398 | Import
v_VerticaDBTarget_node0001 | rows received | 123197558 | Import
v_VerticaDBTarget_node0002 | rows received | 237063416 | Import
(3 rows)
要监视源库上的过程,请查看发送行计数器:
source=> SELECT node_name, counter_name, counter_value,operator_name
FROM execution_engine_profiles WHERE is_executing='t' a
AND counter_name in ('rows sent') AND Operator_name IN ('Export');
node_name | counter_name | counter_value | operator_name
----------------------------+--------------+---------------+---------------
v_VerticaDBSource_node0001 | rows sent | 78890185 | Export
v_VerticaDBSource_node0002 | rows sent | 126071726 | Export
v_VerticaDBSource_node0003 | rows sent | 78889767 | Export
(3 rows)
6. 增量导出
当您不断向源集群中的表添加数据并希望将增量数据复制到目标集群中的目标表时,您可以执行增量导出。
使用增量导出,您可以使用带有epoch谓词或其他谓词(例如日期谓词)的查询仅将最近添加的数据推送到目标。
在以下示例中,39 是上次成功导出的epoch。以下示例中的 EXPORT 语句仅导出在epoch 39 之后加载到源中的数据。导入操作不支持类似的语法。
source=> COPY cluster1_table1 FROM STDIN DIRECT;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> 100
>> 101
>> 102
>> 103
>> \.
source=> SELECT epoch, * FROM cluster1_table1;
epoch | i
-------+-----
39 | 2
39 | 3
39 | 5
40 | 101
40 | 102
39 | 1
39 | 4
40 | 100
40 | 103
(9 rows)
source=> CONNECT TO VERTICA VerticaDBTarget USER dbadmin PASSWORD '' ON '10.100.0.88',5433;
CONNECT
source=> EXPORT TO VERTICA VerticaDBTarget.cluster2_table2 AS SELECT * FROM public.cluster1_table1
WHERE epoch > 39;
Rows Exported
---------------
4
(1 row)
7. 并发导出
如果您有大量数据需要导出,您可以通过并行运行多个导出来加快导出操作:
=> EXPORT TO VERTICA VerticaDBTarget.tgt (n,a,b) AS
SELECT n as col1, a as col2 , b as col3 FROM src
WHERE epoch > 0 AND epoch <= 1;
=> EXPORT TO VERTICA VerticaDBTarget.tgt (n,a,b) AS
SELECT n as col1, a as col2 , b as col3 FROM src
WHERE epoch > 1 AND epoch <= 2;
=> EXPORT TO VERTICA VerticaDBTarget.tgt (n,a,b) AS
SELECT n as col1, a as col2 , b as col3 FROM src
WHERE epoch > 2 AND epoch <= 3;
=> EXPORT TO VERTICA VerticaDBTarget.tgt (n,a,b) AS
SELECT n as col1, a as col2 , b as col3 FROM src
WHERE epoch > 3 AND epoch <= 4;
选择epoch范围(或其他谓词,例如日期谓词),使得行数在数据大小上大致相等。
8. 配置用于导入和导出的网络连接
Vertica 使用 EXPORT TO VERTICA 语句和 COPY FROM VERTICA 语句通过专用网络将数据从一个 Vertica 群集导入和导出到另一个 Vertica 群集。默认情况下,群集使用专用网络导入和导出数据。
要使用公共网络,您必须通过更改导出地址来配置系统。每个服务器只能有一个网络配置。您可以通过以下方式将系统配置为使用公共网络:
- 识别公共网络上节点或群集的 IP 地址。
- 配置数据库或单个节点以进行导入/导出。
有关配置步骤的详细信息,请参阅配置网络以导入和导出数据。
9. 序列、标识和列默认值
导出操作类似于插入数据。但是,当您直接从源导出数据时,Vertica 不会在目标上生成序列和列默认值。
假设您在名为 test_seq 的表中有以下序列:
source=> CREATE SEQUENCE seqinc START 101 MAXVALUE 1000 CACHE 7 CYCLE;
source=> CREATE TABLE test_seq (col_seq INT DEFAULT NEXTVAL('seqinc'),data VARCHAR(100)) ;
source=> COPY test_seq (data) FROM STDIN;
Enter data to be copied followed by a newline.
End with a backslash and a period on a line by itself.
>> AAAA
>> BBB
>> CCCC
>> AAAAA
>> BBBBB
>> CCCCC
>> DDDDD
>> EEEEE
>> FFFFF
>> \.
source=> SELECT * FROM source;
col_seq | data
---------+-------
101 | AAAA
102 | BBB
103 | CCCC
104 | AAAAA
105 | BBBBB
106 | CCCCC
107 | DDDDD
108 | EEEEE
109 | FFFFF
(9 rows)
要将此数据导出到目标,请在目标上执行以下命令:
target=> CREATE SEQUENCE seqinc START 10000
MAXVALUE 100000 CACHE 9 CYCLE;
target=> CREATE TABLE tgt(col_seq INT DEFAULT
NEXTVAL('seqinc'), data VARCHAR(100)) ;
要导入源上的数据,请在源上执行以下命令:
source=> CONNECT TO VERTICA targetdb USER dbadmin
PASSWORD '' ON '10.100.0.77',5433;
source=> EXPORT TO VERTICA targetdb.tgt AS SELECT * from test_seq;
Rows Exported
---------------
9
(1 row)
因为您指定了 SELECT *,所以目标将获取源生成的序列值:
target=> SELECT * FROM tgt;
col_seq | data
---------+-------
101 | AAAA
102 | BBB
103 | CCCC
104 | AAAAA
105 | BBBBB
106 | CCCCC
107 | DDDDD
108 | EEEEE
109 | FFFFF
(9 rows)
如果希望默认值(包括序列、标识)在目标表上生效,请构建导出结构,以便仅选择列数据的值。如果省略序列列,则目标将生成序列和标识值:
source=> CONNECT TO VERTICA targetdb USER dbadmin
PASSWORD '' ON '10.100.0.77',5433;
source=> EXPORT TO VERTICA test1.tgt(data) AS
SELECT data FROM test_seq;
Rows Exported
---------------
9
(1 row)
您可以看到目标上的序列不一定遵循源的序列顺序:
target=> SELECT * FROM tgt;
col_seq | data
---------+-------
10012 | BBBBB
10013 | CCCCC
10015 | EEEEE
10000 | AAAA
10009 | BBB
10010 | CCCC
10011 | AAAAA
10014 | DDDDD
10016 | FFFFF
(9 rows)
使用这种方法,您可以将序列和标识的值从源导出到目标。或者,您可以通过从 EXPORT/IMPORT 语句中省略列来让目标生成序列和标识列。
10. 对象级备份和恢复
Vertica 7.2.x 提供了新的对象级备份/恢复功能。此功能允许您从包含这些对象的任何备份中恢复单个表或架构,而无需恢复整个备份。
当源和目标中的节点数匹配且 Vertica 服务器版本相同时,对象级备份/恢复比执行导入/导出操作要快得多。但是,当源节点数不等于目标节点数时,vbr.py 脚本不可用。
当源和目标节点数匹配时,使用对象级备份和恢复。
11. 更多信息
有关导入和导出的更多信息,请参阅 Vertica 文档中的以下主题:
导出数据
复制数据

