




PgSQL基础知识 | 第1期 | 聚合计算
本期开始陆续学习PgSQL基础知识,本节全面介绍PgSQL中的聚合操作,尤其是PgSQL的聚合支持各种高级功能,比如filter、order by、distinct等功能。
1、语法
aggregate_name (expression [ , ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name (ALL expression [ , ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name (DISTINCT expression [ , ... ] [ order_by_clause ] ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name ( * ) [ FILTER ( WHERE filter_clause ) ]
aggregate_name ( [ expression [ , ... ] ] ) WITHIN GROUP ( order_by_clause ) [ FILTER ( WHERE filter_clause ) ]1)aggregate_name为聚合函数名
2)expression为任意一个不包含聚合表达式或窗口函数调用的值表达式
3)第一个语法,每行都计算一次聚合;第二个语法和第一个行为相同,因为ALL是默认值;第三个语法去重后的每个值计算一次聚合;第四个语法每行都进行一次聚合,并且包括NULL值;最后一种语法针对ordered-set聚合函数
4)通常情况下输入到聚合函数参与计算的值未指定顺序,大部分场景下没什么区别,比如min,结果是一样的:如果order by的列和聚合列一样,则作为一个入参,否则就是多个入参,这在聚合计算流程中使用的分支是不一样的
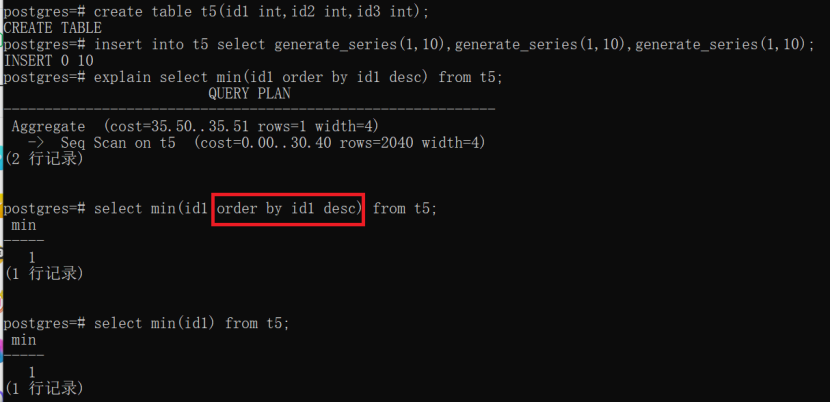
但是一些聚合函数比如array_agg或者string_agg产生的结果就依赖于输入行的顺序,这就需要order_by_clause来指定需要的顺序:
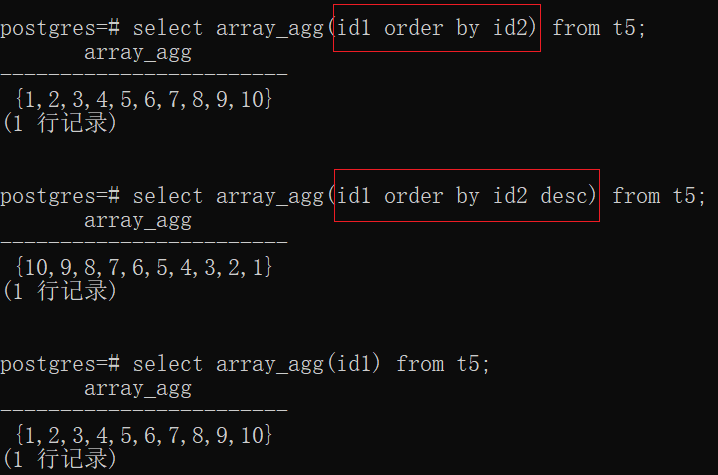
Distinct若加order by,则order by列只能是distinct列,distinct本身在进行计算的时候就会重新对distinct列进行排序,可以这么说,加上order by也是多余的:

对于普通聚合和统计聚合,order by是可选的,还有一类聚合函数ordered-set聚合,需要指定order by。
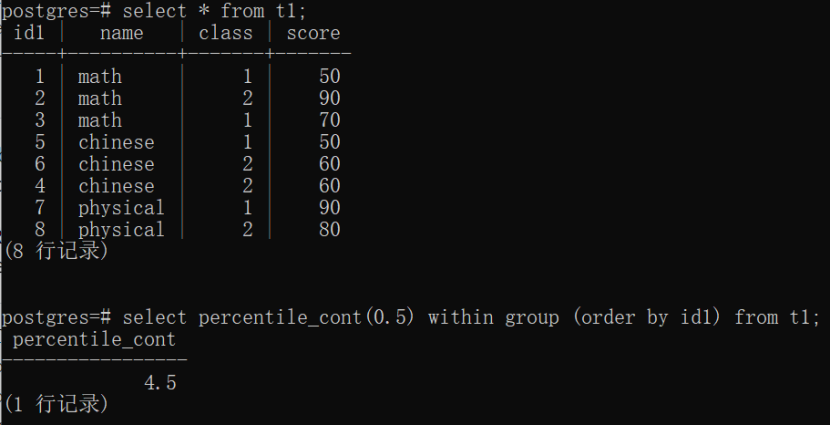
5)ordered-set聚合典型函数是rank和percentile计算,order_by_clause需要写到WITHIN GROUP (...)里面。输入的每行都会计算order_by_clause中的表达式,并进行并排序,最后作为聚合函数的入参参与聚合计算。non-WITHIN GROUP 的order_by_clause不会作为参数参与聚合计算。WITHIN GROUP前面的参数表达式被称为direct 参数,每个聚合函数调用一次计算一次direct参数,而非每一行。
percentile_cont函数通过使用连续分布模型返回对应于给定排序规范的指定百分位数的值,比如percentile_con(0.5)就是返回中位数:这里的0.5就是direct参数
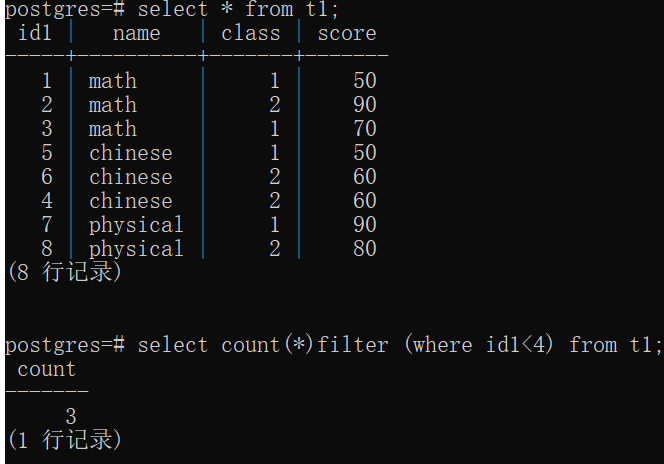
6)如果指定了filter,只有满足filter条件的才会给到聚合函数进行计算,不满足条件的丢弃掉:
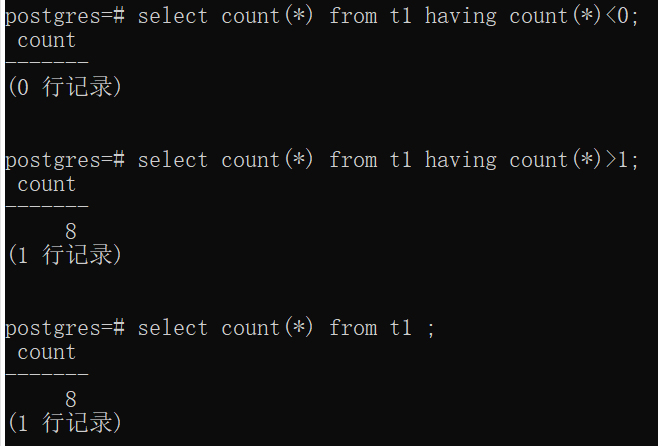
7)聚合表达式还可以出现在having子句中:仅当满足having条件时,才将聚合值输出
2、聚合函数
聚合函数分为通用聚合函数、统计的聚合函数、ordered-set聚合函数、Hypothetical-set聚合函数四大类,外加一个Grouping操作。
通用聚合函数包括常用的min、max、min、sum、avg等聚合函数,这里介绍几个特殊的聚合函数:
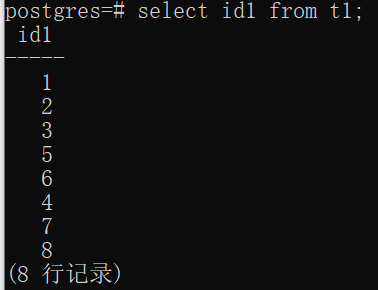
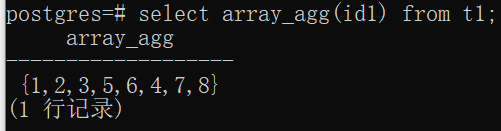
1)array_agg:将输入列以数组形式输出,若加上order by则可以指定顺序

2)string_agg:将输入列以数组形式输出,并以指定的分隔符进行分隔

需要注意,除了count,若表为空,其他聚合函数会返回一个NULL值,尤其是sum,它不会返回0;aggray_agg也会返回NULL,而不是一个空数组
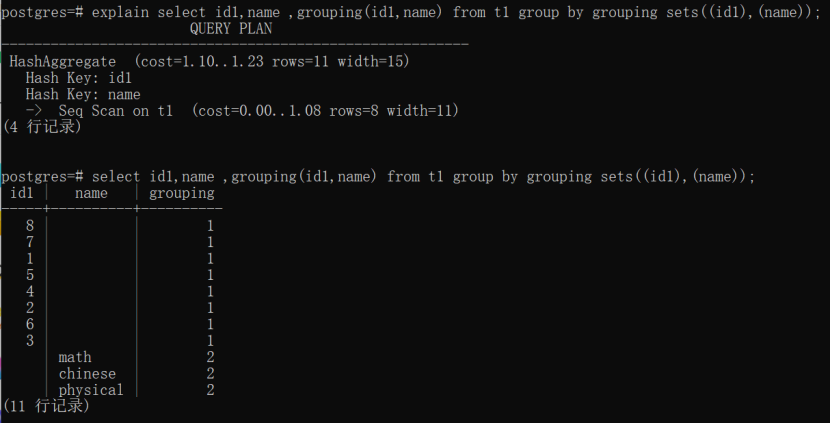
Grouping操作:经常和grouping sets一起使用,用于唯一标记是哪个分组Key的行。GRUPING操作的参数并没有参与计算,但是必须和GROUP BY子句精确匹配。Grouping入参每个参数用一位表示,0表示对应的表达式(字段)在grouping sets产生的行的分组中:比如第1行,id1为8在分组中,name这一行不在分组中,则0 1得出grouping值为1;最后一行,id1不在分组中,name在分组中,则1 0 得出grouping值为2
Ordered-set聚合函数:和order by的次序密切相关,排序输入的行会忽略NULL值。比如mode()取分组中出现频率最多的值,如果最高频率的值有多个,则随机取一个:

3、参考
https://www.postgresql.org/docs/12/sql-expressions.html#SYNTAX-AGGREGATES
https://www.postgresql.org/docs/12/functions-aggregate.html
