




大家好,这里是 Lucifer三思而后行,专注于提升数据库运维效率。
目录
- 前言
- 为什么使用绑定变量?
- 查看 SQL 绑定变量的几种方式
- 首先获取 SQL_ID
- v$sql_bind_capture 方式
- V$SQL 配合 dbms_sqltune.extract_bind 方式
- dbms_xplan.display_cursor 方式
- sqltrpt.sql 方式
- 拓展
- 往期精彩文章推荐
前言
依稀记得很久之前给一个客户分析数据库性能问题时,发现数据库中大量 SQL 未使用绑定变量,所以建议开发优化 SQL,使用绑定变量的传参方式去改写,但是开发给出的回复至今仍然让我记忆犹新,原话如下:“我做了那么多年开发,传参数都是这样写,我接触了那么多系统,不管是 ERP,FLOW,各厂不同的 MES 系统,从来没有在开发代码中写的语句使用过绑定变量。”
本想愤而辩之,但又想到《三季人》的故事,遂罢。
为了让更多朋友了解为什么 SQL 要使用绑定变量,所以写了一篇文章,谨代表个人观点,愿此微薄之力,可助君一二。
为什么使用绑定变量?
这里借用百度词条对 绑定变量(bind variable) 的定义。
绑定变量(bind variable)是指在 SQL 语句的条件中使用变量而不是常量。绑定变量是相对文本变量来讲的,所谓文本变量是指在 SQL 直接书写查询条件,这样的 SQL 在不同条件下需要反复解析,绑定变量是指使用变量来代替直接书写条件,查询绑定变量的值在运行时传递,然后绑定执行。
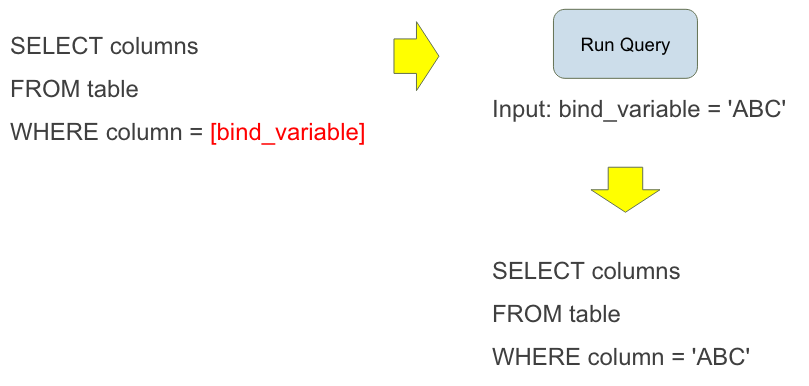
比如共享池(shared_pool)里有两条 SQL 语句:
select * from tab1 where col1=1;
select * from tab1 where col1=2;
复制对 Oracle 数据库来说,这是两条完全不同的 SQL,对这两条语句都需要进行硬解析(hard parse)。因为 Oracle 会根据 SQL 语句的文本去计算每个字符在内存里的哈希(HASH)值,因此虽然上述两条 SQL 只有一个字符不一样,Oracle 根据哈希算法在内存中得到的哈希地址就不一样,所以 Oracle 就会认为这是两条完全不同的语句。
然而,如果将上述 SQL 改写成 select * from tab1 where col1=:var1;,然后通过对变量 var1 的赋值去查询,那么 Oracle 对这条语句第一次会进行硬解析,以后就只进行软解析(soft parse)。
假设某条语句被重复执行了几十万次,那么使用绑定变量带来的好处是巨大的。一个应用程序如果绑定变量使用不充分,那么几乎一定会伴随着严重的性能问题。
要想完全了解上面所说的关于绑定变量的定义,必须要先明白其中涉及到的几个词汇:硬解析,软解析以及共享池。
共享池
先说说共享池(Shared pool)的作用:缓存 SQL 语句及 SQL 语句的执行计划。
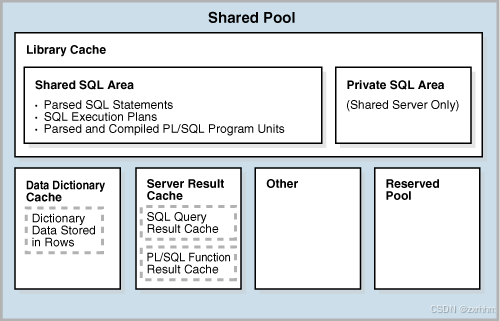
共享池由以上几块区域组成,包括 Library Cache、Data Dictionary Cache 和 Server Result Cache:
- Library Cache 主要用于储存可执行的 SQL 和 PL/SQL 代码。
- Data Dictionary Cache 主要用于缓存数据字典的相关数据,该缓存区域对所有服务进程共享。
- Server Result Cache 主要用于保存 SQL 和 PL/SQL 执行产生的结果集。
共享池是存在于 SGA 中:
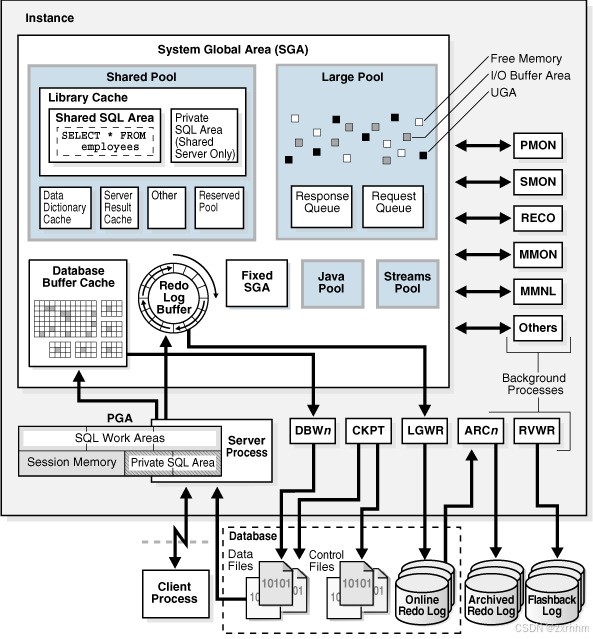
SGA 的大于决定了共享池的大小,如果一直执行 SQL 硬解析,当达到共享池的阈值时,就会把原本正常软解析的语句给挤出去,这是导致数据库卡顿的原因之一。
硬解析与软解析
要想说清楚硬解析和软解析的区别,就得先说一下 SQL 执行的大致流程:
- 语法检查:检查 SQL 语句的语法是否正确。
- 语义检查:检查 SQL 语句中引用的表、列、数据类型等是否存在于数据库中,以及用户是否有足够的权限访问它们。
- 共享池查询:检查共享池(Shared Pool)中的库缓存(Library Cache),看是否已经存在相同或相似的 SQL 语句的执行计划。如果存在,它可能会重用已有的执行计划,这个过程称为 SQL 语句的软解析。如果不存在,则需要进行硬解析。
很显然,软、硬解析就发生在第 3 步,所以关于硬解析和软解析最简单直白的区别就是:
- 硬解析:需要生成执行计划
- 软解析:不需要生成执行计划
接下来主要说说硬解析,硬解析大致包括下面几个过程:
- 对 SQL 语句进行语法检查,看是否有语法错误。比如
select/from/where等的拼写错误,如果存在语法错误,则退出解析过程; - 通过数据字典,检查 SQL 语句中涉及的对象和列是否存在。如果不存在,则退出解析过程。
- 检查 SQL 语句的用户是否对涉及到的对象是否有权限。如果没有则退出解析;
- 通过优化器创建一个最优的执行计划。这个过程会根据数据字典中的对象的统计信息,来计算多个执行计划的 cost,从而得到一个最优的执行计划。这一步涉及到大量的数据运算,从而会消耗大量的 CPU 资源;(library cache 最主要的目的就是通过软解析来减少这个步骤);
- 将该游标所产生的执行计划、SQL 文本等装载进 library cache 中的 heap 中。
而软解析就是因为相同文本的 SQL 语句存在于 library cache 中,相对硬解析来说,会减少很多不必要的步骤,从而节省大量的资源耗费。
因为绑定变量可以将 SQL 语句中的常量变为变量,直接避免了 SQL 的多次硬解析,所以,想让数据库的硬解析减少的最有效办法之一就是:绑定变量。
以下内容摘自 Thomas Kyte 的《Oracle编程艺术 深入理解数据库体系结构》 1.3 开发数据库应用的正确方法:
硬解析会减少系统能支持的用户数,但程度如何可能不容易度量。这取决于多耗费了多少资源,但更重要的因素是库缓存所用的闩定(latching)机制。硬解析一个查询时,数据库会更长时间地占用一种低级串行化设备,这成为闩(latch)。这些闩能保护 Oracle 共享内存中的数据结构不会同时被两个进程修改(否则,Oracle 的数据结构会最终遭到破坏),而且如果有人正在修改某个数据结构,等待队列也越长。当大家都在试图抢占这种珍贵的闩资源时,你的服务器可能看上去非常空闲,但是数据库中的所有应用都运行得非常慢。造成这种现象的原因可能是有人占据着某种串行化设备,而其他等待串行化设备的人开始排队,因此你无法全速运行。数据库中只要有一个应用表现不佳,就会严重地影响所有其他应用的性能。如果只有一个小应用没有使用绑定变量,那么即使其他应用原本设计得很好,能适当地将已解析的 SQL 放在共享池中以备重用,但因为这个小应用的存在,过一段时间就会从共享池中把已存储的 SQL 的执行计划排挤出去。这就使得这些设计得当的应用也必须再次硬解析 SQL,真是一粒老鼠屎就能毁了一锅汤。
此时,再去回顾一下绑定变量的解释,是不是会更加清晰? 没有的话建议再看几遍。
查看 SQL 绑定变量的几种方式
首先获取 SQL_ID
-- 查看 SQL_ID
select sid,serial#,username,event,p1,p2,p3,sql_id,sql_child_number from v$session;
-- 查看 SQL 真实执行计划
SELECT * FROM TABLE(dbms_xplan.display_awr(sql_id => 'aahrkm2sxgw4x'));
SELECT * FROM TABLE(dbms_xplan.display_cursor('aahrkm2sxgw4x',0,'ALL'));
复制v$sql_bind_capture 方式
使用 V$SQL_BIND_CAPTURE获取绑定变量的值,有一些限制:
- 如果
STATISTICS_LEVEL设置成BASIC,那绑定变量的捕捉就会关闭(Bind capture is disabled when the STATISTICS_LEVEL initialization parameter is set to BASIC.) - 默认是
900秒捕捉一次绑定变量值,由_cursor_bind_capture_interval参数控制。 V$SQL_BIND_CAPTURE视图中记录的绑定变量只对WHERE条件后面的绑定进行捕获,这点需要使用的时候注意。- 对于
DML操作,V$SQL_BIND_CAPTURE无法获取绑定变量的值。
-- 查看 STATISTICS_LEVEL show parameter STATISTICS_LEVEL NAME TYPE VALUE ------------------------------------ --------------------------------- ------------------------------ statistics_level string TYPICAL -- 查看绑定变量值 col name for a45 col value for a10 col describ for a60 set lines 200 select x.ksppinm name, y.ksppstvl value, x.ksppdesc describ from sys.x$ksppi x, sys.x$ksppcv y where x.inst_id = userenv ('instance') and y.inst_id = userenv ('instance') and x.indx = y.indx and x.ksppinm in ('_cursor_bind_capture_interval'); NAME VALUE DESCRIB ---------------------------------------- ---------- ------------------------------------------------------------ _cursor_bind_capture_interval 900 interval (in seconds) between two bind capture for a cursor -- 通过 SQL_ID 和执行时间查看绑定变量值 SELECT sql_id, NAME, position, datatype_string, value_string, last_captured FROM v$sql_bind_capture WHERE sql_id IN ('aahrkm2sxgw4x') AND last_captured BETWEEN to_date('2022-05-11 14:00', 'yyyy-mm-dd hh24:mi') AND to_date('2022-05-11 15:00', 'yyyy-mm-dd hh24:mi');复制
第一种方法无法查看最新的 SQL 的绑定变量,因为还没有被捕捉,需要等上限捕捉间隔 900s 之后才可以查询。
V$SQL 配合 dbms_sqltune.extract_bind 方式
V$SQL 视图中的 BIND_DATA 字段用来存储绑定变量的值,但是从这个视图查询绑定变量的值,有很大的局限性:
- 记录频率受
_cursor_bind_capture_interval隐含参数控制,默认值为 900,表示每 900 秒记录一次绑定值,也就是说在 900 内,绑定变量值的改变不会反应在这个视图中。除非你调整隐含参数_cursor_bind_capture_interval。 - 它记录的仅仅最后一次捕获的绑定变量值。
BIND_DATA数据类型为RAW,需要进行转换。
-- 通过 v$sql 获取最新的 SQL bind_data
SELECT sql_id,
sql_text,
literal_hash_value,
hash_value,
bind_data,
last_active_time
FROM gv$sql
WHERE sql_id = 'aahrkm2sxgw4x'
ORDER BY 6 DESC;
-- 转化 raw 类型
-- 一次性获取全部变量值
select DBMS_SQLTUNE.EXTRACT_BINDS(&bind_data) from dual;
-- 查询指定的变量值,数字几代表第几列
select DBMS_SQLTUNE.EXTRACT_BIND(&bind_data,1).VALUE_STRING from dual;
select DBMS_SQLTUNE.EXTRACT_BIND(&bind_data,2).VALUE_STRING from dual;--18703062
select DBMS_SQLTUNE.EXTRACT_BIND(&bind_data,3).VALUE_STRING from dual;
复制该方式比 v$sql_bind_capture 方式获取到的记录更新。
dbms_xplan.display_cursor 方式
select * from table(dbms_xplan.display_cursor('aahrkm2sxgw4x', 0,format=>'+PEEKED_BINDS'));
复制该方式从 v$sql_plan 中进行查找。
sqltrpt.sql 方式
sqlplus / as sysdba @?/rdbms/admin/sqltrpt.sql
--输入 sql_id
复制拓展
使用 SQL 查找 Oracle 数据库中未使用绑定变量的 SQL:
-- 获取最近 30 天未使用绑定变量的 SQL
set lin2222 pages10000 tab off num50
col parsing_schema_name for a15
col module for a20
col fms_co for 999,999
col sql_id for a20
col sql_text for a100
SELECT
parsing_schema_name,
module,
fms_co,
fms,
sql_id,
sql_text
FROM (
SELECT
TO_CHAR(FORCE_MATCHING_SIGNATURE) AS fms,
sql_text,
parsing_schema_name,
module,
SQL_ID,
-- fms 的次数 >1 的表示可能没有使用绑定变量
COUNT(1) OVER (PARTITION BY FORCE_MATCHING_SIGNATURE ORDER BY NULL) AS fms_co,
ROW_NUMBER() OVER (PARTITION BY FORCE_MATCHING_SIGNATURE ORDER BY NULL) AS rn,
-- 标志已经使用绑定变量的SQL,sqlid_co > 1
COUNT(1) OVER (PARTITION BY sql_id ORDER BY NULL) AS sqlid_co
FROM gv$sql
WHERE last_active_time >= SYSDATE - 30
AND TO_CHAR(force_matching_signature) != '0'
AND parsing_schema_name NOT IN ('SYS', 'DBSNMP')
ORDER BY fms_co DESC
)
WHERE rn = 1
AND fms_co >= 10 -- 只筛选 >=10 执行次数的
AND sqlid_co = 1;
PARSING_SCHEMA_ MODULE FMS_CO FMS SQL_ID SQL_TEXT
--------------- -------------------- -------- ---------------------------------------- -------------------- ----------------------------------------------------------------------------------------------------
EODA SQL*Plus 16 13574122878501965338 5nzknd0yyuxqb select e.ename,e.sal from scott.emp e where e.empno =7499
-- 查看所有未使用绑定变量的 SQL
SELECT
v.sql_text,
v.sql_id,
v.force_matching_signature,
v.parsing_schema_name
FROM
v$sql v
WHERE
v.force_matching_signature = 13574122878501965338;
SQL_TEXT SQL_ID FORCE_MATCHING_SIGNATURE PARSING_SCHEMA_
---------------------------------------------------------------------------------------------------- -------------------- -------------------------------------------------- ---------------
select e.ename,e.sal from scott.emp e where e.empno =7654 3c75twsp1w115 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7788 53zhwrfr0n301 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7369 8859z6yyus7pz 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7876 6wrq0s5gtnja2 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7900 99361p33nst62 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7698 0gh4ws1y455xq 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7902 f8fxg8sn917rx 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7844 dwjy0mmhcts52 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e WHERE e.empno =7654 8sp7fu0rvf1un 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno = 7654 9u0mq6fqda8qy 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7521 79db79zfvqg3q 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7566 5rqw488f6fm7v 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7934 a1hwdr9pjkq7t 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7499 5nzknd0yyuxqb 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7839 gcu4vghpp702g 13574122878501965338 EODA
select e.ename,e.sal from scott.emp e where e.empno =7782 4k8wq27uw7yrp 13574122878501965338 EODA
复制往期精彩文章推荐
Oracle 数据库启动过程之 nomount 详解
Oracle RAC 修改系统时区避坑指南(深挖篇)
Ubuntu 22.04 一键安装 Oracle 11G RAC
使用 dbops 快速部署 MySQL 数据库
Oracle RAC 启动顺序,你真的了解吗?
达梦数据库一键安装脚本(免费)一篇文章让你彻底掌握 Python 🔥
一篇文章让你彻底掌握 Python
一篇文章让你彻底掌握 Shell 🔥
Oracle 监控 EMCC 13.5 安装部署超详细教程 🔥
Oracle 一键巡检自动生成 Word 报告 🔥
Oracle一键安装脚本的 21 个疑问与解答 🔥
Oracle一键巡检脚本的 21 个疑问与解答 🔥
全网首发:Oracle 23ai 一键安装脚本 🔥
Oracle 19C 最新 RU 补丁 19.24 ,一键安装! 🔥
Oracle Linux 6 一键安装 Oracle 11GR2 RAC
Oracle Linux 7.9 一键安装 Oracle 19C
Oracle Linux 8.9 一键安装 Oracle 19C RAC
Oracle Linux 9.4(aarch64) 一键安装 Oracle 19C 🔥
openEuler 20.03 LTS SP4 一键安装 Oracle 19C 🔥
openEuler 22.03 LTS SP4 一键安装 Oracle 19C RAC
RHEL 7.9 一键安装 Oracle 19C 19.23 RAC
Redhat 8.4 一键安装 Oracle 11GR2
RedHat 9.4(aarch64) 一键安装 Oracle 19C
龙蜥 Anolis 7.9 一键安装 Oracle 19C 19.23
龙蜥 Anolis OS 8.8 一键安装 Oracle 19C
SUSE 15 SP5 一键安装 Oracle 19C
统信 UOS V20 1070(a) 一键安装 Oracle 11GR2
Ubuntu 22.04 一键安装 Oracle 19C
Ubuntu 14.04 一键安装 Oracle 19C
银河麒麟 Kylin V10 SP3 一键安装 Oracle 19C 🔥
银河麒麟 Kylin V10 SP3 一键安装 Oracle 11GR2 RAC
Oracle DataGuard GAP 修复手册 🔥
优化 Oracle:最佳实践与开发规范
DBA 必备:Linux 软件源配置全攻略 🔥
Linux 一键配置时钟同步全攻略 🔥
Starwind 配置 ISCSI 共享存储
SUSE 15 SP3 安装 Oracle 19C RAC 数据库
达梦 8 数据库安装手册 🔥
Oracle 12CR2 RAC 安装避坑宝典
Linux7 安装 Oracle 19C RAC 详细图文教程 🔥
Oracle ADG 搭建 RAC to Single 详细教程
Oracle DataGuard GAP 修复手册 🔥
Oracle 分区表之在线重定义
AutoUpgrade 快速升级 Oracle 数据库
Oracle 数据库巡检命令手册 🔥
Oracle 数据坏块的 N 种修复方式 🔥
数据库 SQL 开发入门教程
超全 Linux 基础命令总结 🔥
VMware 虚拟机安装 Linux 系统
Linux 安装 MySQL 详细教程
教你玩转 SQLPLUS,工作效率提升 200%
感谢您的阅读,这里是 Lucifer三思而后行,欢迎 点赞+关注,我会持续分享数据库知识、运维技巧。
评论


 0 点赞
0 点赞 0 点赞
0 点赞 0 点赞
0 点赞


