




前言
昨晚在写流复制素材的时候,写到了复制冲突,常见的快照冲突想必各位并不陌生,
User query might have needed to see row versions that must be removed
但是提到流复制场景下的死锁,很多人可能并未深究过。这一期,让我们唠唠数据库中各种罕见的死锁场景。
死锁
死锁,顾名思义,如果在不借助"外力"的情况下,那么事务将永远相互等待,因为有一个无法自行解决的循环依赖。
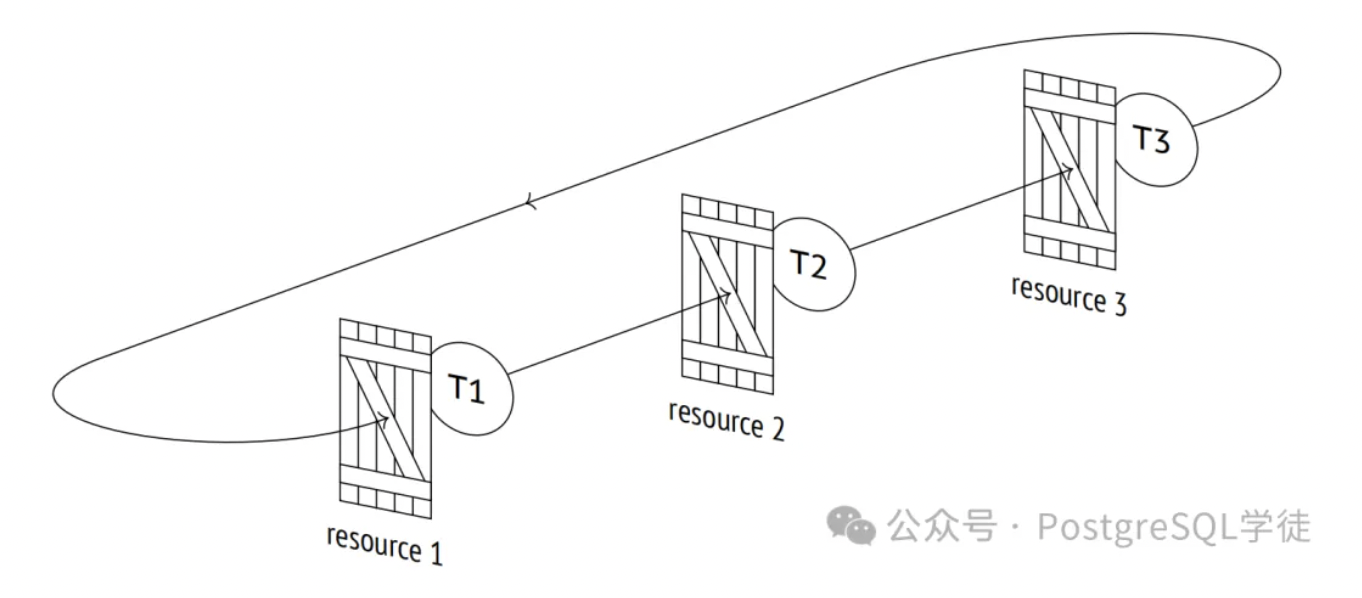
处理死锁问题主要有两种方法:死锁预防、死锁检测与死锁恢复。死锁预防是一种"事前"手段,就是通过机制来保证系统不会产生死锁问题,这种方式往往会造成一些不必要的回滚,尤其在锁冲突并不严重的场景下更容易浪费系统资源。死锁检测与死锁恢复机制,是一种"事后"手段,通过死锁检测来及时发现系统中发生的死锁,并通过死锁恢复手段来保证一部分事务可以继续处理。
对于 PostgreSQL 来说,如果进程获取锁失败,在进入休眠状态后会自动设置一个由 deadlock_timeout 参数定义的超时时间。如果在 deadlock_timeout 时间单位之后,仍然在等待,等待进程便会醒来并发起检测,如果没有在等待,那么皆大欢喜。一旦检测到死锁,其中一个事务将被强制终止,从而释放这个事务的锁并使其他事务能够继续执行。在大多数情况下,是发起检测的事务被中断,但如果循环中包括一个 autovacuum 进程,并且当前没有在冻结元组以防止回卷,那么服务器会终止 autovacuum 进程,因为它的优先级较低。
让我们看个最为常见的例子:
postgres=# create table t1(id int);
CREATE TABLE
postgres=# insert into t1 values(1);
INSERT 0 1
postgres=# insert into t1 values(2);
INSERT 0 1
postgres=# begin;
BEGIN
postgres=*# update t1 set id = 99 where id = 1; ---第①步
UPDATE 1
postgres=*# update t1 set id = 100 where id = 2; ---第③步
UPDATE 1复制
第二个会话
postgres=# begin;
BEGIN
postgres=*# update t1 set id = 100 where id = 2; ---第②步
UPDATE 1
postgres=*# update t1 set id = 99 where id = 1; ---第④步
ERROR: deadlock detected
DETAIL: Process 27023 waits for ShareLock on transaction 498461; blocked by process 26975.
Process 26975 waits for ShareLock on transaction 498462; blocked by process 27023.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,1) in relation "t1"
postgres=!# commit; ---第⑤步
ROLLBACK复制
当执行第④步时,在 1 秒之后,该进程便会发起检测,并被 cancel。这种场景下的死锁很好理解,两个事务产生了循环依赖。单机场景下的死锁很简单,那么如果是流复制呢?主库和备库联动会产生死锁吗?
流复制场景下的死锁
没错,从节点也会影响到主库。回想一下流复制的核心原理——备库按部就班,原模原样复刻主库的操作。主库回滚我就回滚,主库删除我就删除,基于此,流复制为什么也会产生死锁就不难理解了。
举个栗子,在主库上创建两个表:
postgres=# create table items(item_id int);
CREATE TABLE
postgres=# create table options(item_id int, v1 text);
CREATE TABLE复制
| 主库 | 备库 |
|---|---|
| begin; | |
| alter table options add v2 int; | begin; |
| select * from items; | |
| alter table items add a text; | |
| select * from options; |
当备库执行到 select * from options; 的时候,便会提示
postgres=*# select * from options;
ERROR: deadlock detected
LINE 1: select * from options;
^
DETAIL: Process 27350 waits for AccessShareLock on relation 33622 of database 5; blocked by process 27346.
Process 27346 waits for AccessExclusiveLock on relation 33619 of database 5; blocked by process 27350.
HINT: See server log for query details.复制
这个报错其实就很明显了,27350 在等待 27346,27346 又在等待 27350。互相等待,产生死锁。
那么为什么会这样?其实还是那句话,主库做什么备库就做什么,当主库执行了第一条语句之后,备库也会做这个事情
postgres=# \! ps -ef | egrep '27350|27346'
postgres 27346 27342 0 14:49 ? 00:00:00 postgres: startup recovering 0000000100000006000000EA waiting
postgres 27350 27342 0 14:49 ? 00:00:00 postgres: postgres postgres [local] SELECT waiting
postgres 27434 27432 0 14:57 pts/0 00:00:00 sh -c ps -ef | egrep '27350|27346'
postgres 27436 27434 0 14:57 pts/0 00:00:00 grep -E 27350|27346复制
| 主库 | 备库 |
|---|---|
| begin; | |
| alter table options add v2 int; (这一步在备库上,会给 options 加上了 8 级锁) | begin; |
| select * from items; (在备库上给 items 加上了 1 级锁) | |
| alter table items add a text; (这一步在备库上,会尝试给 items 加上 8 级锁,但是会阻塞) | |
| select * from options; (在备库上尝试给 options 加 1 级锁) |
因此,流复制场景下,死锁也是需要格外注意的一点。
SQL 语句是原子的吗
UPDATE 语句在更新到指定行的时候才会锁定相应行,而不是立即全部锁定,而且这种锁定并不是同时发生的。因此如果有一个 UPDATE 命令以一种顺序修改多行,而另一个 UPDATE 命令以不同的顺序执行相同的操作,就也有可能会发生死锁。举个栗子
postgres=# create table t1(id int,name text,salary numeric);
CREATE TABLE
postgres=# insert into t1 values(1,'xiongcc','100');
INSERT 0 1
postgres=# insert into t1 values(1,'xiaoming','200');
INSERT 0 1
postgres=# insert into t1 values(1,'xiaoli','300');
INSERT 0 1
postgres=# create index on t1(salary desc);
CREATE INDEX复制
然后创建一个 UDF,在进行操作之前,先休眠 5 秒。
postgres=# CREATE FUNCTION slow(n numeric)
RETURNS numeric
AS $$
SELECT pg_sleep(5);
SELECT n + 100.00;
$$ LANGUAGE sql;
CREATE FUNCTION复制
在第一个会话中,会先顺序扫描满足条件的元组,再进行更新
postgres=# explain update t1 set salary = slow(salary) where salary >= 100.00;
QUERY PLAN
--------------------------------------------------------------
Update on t1 (cost=0.00..485.12 rows=0 width=0)
-> Seq Scan on t1 (cost=0.00..485.12 rows=1810 width=38)
Filter: (salary >= 100.00)
(3 rows)复制
在第二个会话中,让我们禁止顺序扫描,这样的话,执行器便会选择索引扫描 (注意,索引是按降序创建的,因此索引扫描实际上从后面往前扫)
postgres=# set enable_seqscan to off;
SET
postgres=# explain update t1 set salary = slow(salary) where salary >= 100.00;
QUERY PLAN
------------------------------------------------------------------------------------
Update on t1 (cost=0.15..505.33 rows=0 width=0)
-> Index Scan using t1_salary_idx on t1 (cost=0.15..505.33 rows=1810 width=38)
Index Cond: (salary >= 100.00)
(3 rows)复制
那么问题来了:第一个会话从前往后扫,第二个会话从后往前扫,最终相互等待
locked_row | locker | modes
------------+--------+-------------------
(0,1) | 498524 | {"No Key Update"} ---第一个会话
(0,3) | 498525 | {"No Key Update"} ---第二个会话
(2 rows)
...
locked_row | locker | modes
------------+--------+-------------------
(0,1) | 498524 | {"No Key Update"} ---第一个会话
(0,2) | 498524 | {"No Key Update"} ---第一个会话
(0,3) | 498525 | {"No Key Update"} ---第二个会话
(3 rows)
postgres=# update t1 set salary = slow(salary) where salary >= 100.00;
ERROR: deadlock detected
DETAIL: Process 6070 waits for ShareLock on transaction 498525; blocked by process 6120.
Process 6120 waits for ShareLock on transaction 498524; blocked by process 6070.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,3) in relation "t1"复制
小结
当前数据库的死锁检测机制还比较"粗糙",通常都是发起死锁检测的事务被干掉,一个理想情况下,应使事务回滚带来的代价最小,比如
事务已经运行了多久,在完成其指定任务之前该事务还将计算多长时间 该事务已使用了多少资源等 为完成事务还需使用多少资源,扫描多少行等 回滚时会涉及到多少死元组 ...
如果你发现 pg_stat_database.deadlocks 指标不断上涨,并且日志也有大量的 ERROR:deadlock detected,那么往往意味着你的应用程序设计不良,死锁检测是要消耗资源的,其次,在死锁检测期间,还会停止对重锁的处理,需要格外小心。
