




多模态融合图数据库PandaDB 第0.5.0版发布!本版本优化了底层数据存储结构,引入了自定义数据类型、图算法包功能模块,完善事务机制和数据库管理UI,并附带了一个兼容Neo4j Java Driver典型用法的驱动。
全新版本功能抢鲜看!
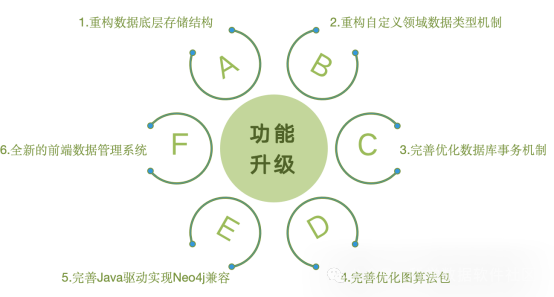
该版本分列簇存储不同标签的数据,并将属性KV进行拆分存储,可以显著提升数据查询(特别是复杂关系查询和多跳查询)和更新性能,有效提升了系统的整体性能。
2.新增自定义数据类型机制
该版本允许用户支持自定义数据类型和相应的数据处理分析功能。不同领域的数据资源,逻辑结构和操作需求具有很强的多样性。PandaDB通过自定义数据类型机制支持领域用户自行定义领域数据的底层序列化机制、上层的逻辑结构和操作符,从而在保证PandaDB通用性的同时,更好满足领域数据的多样化存储和管理需求。
3.完善数据库事务机制
该版本支持Read Committed事务隔离级别,通过确保一组数据库操作的原子性、一致性、隔离性和持久性(ACID特性),可有效解决并发修改、客户端异常退出等场景下的数据不一致和死锁问题。
4.完善优化图算法包功能
支持社区发现算法Louvain Label Propagation、中心度评价算法PageRank Betweenness Centrality、路径发现算法BFS DFS DijkstraSourceTargetShortest DijkstraSingleSourceShortest。
5.新增Neo4j Java Driver兼容驱动
该版本带有一个名为Neo4Panda-Java-Driver的驱动,可以兼容Neo4j Java Driver的主要API。大幅降低了用户使用PandaDB替代Neo4j的应用迁移开销。
新前端UI提供更加直观和友好的用户界面,改善了用户体验,使得数据可视化和管理变得更加容易。

PandaDB是中国科学院计算机网络信息中心自主研发的多模态融合图数据库,采用扩展属性图模型实现海量多元异构数据语义级融合,提供高效的统一存储、语义关联融合、统一检索和知识发现能力,适用于领域知识图谱构建、大规模复杂网络挖掘、海量异构主数据资源治理以及基Graph+RAG的知识增强检索等业务场景开发。

更多产品下载及使用信息,请访问 www.pandadb.cn
产品使用及反馈联系 18910263390 (微信同号)吴老师
评论

 0 点赞
0 点赞