




1、概览
本文档解答了您可能遇到的有关删除以及删除如何影响 Vertica 数据库性能的最重要问题。这些常见问题分为以下几类:
- 删除基础知识
- 删除操作的过程
- 投影设计注意事项
- 清除已删除的记录
2、基础
2.1 Vertica 如何处理 DELETE 和 UPDATE ?
当您在 Vertica 中运行 DELETE 语句时,数据不会立即从存储容器中删除。相反,DELETE 语句会添加一个删除向量,该向量指向包含标记为删除的记录的每个 WOS 和 ROS 容器。每个删除向量包含容器中已删除记录的位置以及提交 DELETE 语句的 epoch。
数据库会将 UPDATE 语句拆分为 DELETE + INSERT。当您在表上运行 SELECT 查询时,Vertica 会过滤掉删除向量中标记的记录,从结果中忽略这些记录。
2.2 AHM (Ancient History Mark)
Ancient History Mark (AHM) 是一个标记可从物理存储中清除已删除数据的 Epoch 。默认情况下,Vertica 以 180 秒的间隔推进 AHM Epoch。当集群中的节点发生故障或数据库包含未刷新的投影时,AHM Epoch 不会推进。AHM 永远不会大于 Last Good Epoch (LGE)。
您可以使用以下命令验证 AHM Epoch、LGE Epoch 和 Current Epoch :
=>SELECT get_ahm_epoch(),get_last_good_epoch(),get_current_epoch();
get_ahm_epoch | get_last_good_epoch | get_current_epoch
-------------------+---------------------+--------------------
492840 492840 492841
(1 row)
2.3 什么是 Replay Delete ?
DELETE 语句创建一个删除向量,该向量存储在 WOS 中并标记为 DVWOS。单个 DELETE 语句会为每个包含 DELETE 语句删除的数据的存储容器创建一个 DVWOS 对象。带有 DIRECT 提示的 DELETE 语句会创建一个删除向量,该向量直接存储在文件系统中并标记为 DVROS。
当 Tuple Mover 的 Moveout 操作将数据从 WOS 内存移入 ROS 时,它会将多个 WOS 容器组合成一个大型、排序的 ROS 容器。Tuple Mover 的 Moveout 操作还会将删除向量从 WOS 移出以创建新的 DVROS 容器。
如果 Moveout 的数据中的某些数据已被删除,则这些数据在新创建的 ROS 容器中具有新位置。删除向量移出后,删除向量会捕获 ROS 容器中已删除记录的新位置。Replay Delete 指的就是重建这些已经删除的数据在移动后新的 ROS 中位置向量的过程。
Replay Delete 操作发生在 Tuple Mover Mergeout 操作期间。当 Mergeout 操作合并已删除记录的 ROS 容器时,它会清除在 AHM Epoch 之前删除的所有数据。任何无法清除的数据在新创建的 ROS 容器中都有新位置。此过程需要重建删除向量 (delete vectors),这些向量指向新 ROS 容器中未清除的已删除数据的位置。
Vertica 在节点恢复、重组、在集群中添加或删除节点时的重新平衡以及投影刷新期间都存在 Replay Delete 操作。这些操作还会清除在 AHM Epoch 之前已删除的数据。
注意:只有无法清除的已删除记录才会参与 Replay Delete。
2.4 哪个系统表可以跟踪删除向量?
Vertica 系统表 DELETE_VECTORS 包含有关删除向量和已删除记录数的信息。
3、删除操作的过程
3.1 删除操作过程中发生了什么?
以下图片和步骤显示了删除生命周期流程的示例。此示例显示了一个包含一个 WOS 容器和一个 ROS 容器的表。
步骤 1:运行以下 DELETE 语句:
=> DELETE from Table1 where C1 in (60,300);
执行这个语句后,在内存中分别为 WOS 容器和 ROS 容器创建了删除向量 DVWOS 1 和 DVWOS 2,并在 Epoch = 102 提交此语句:
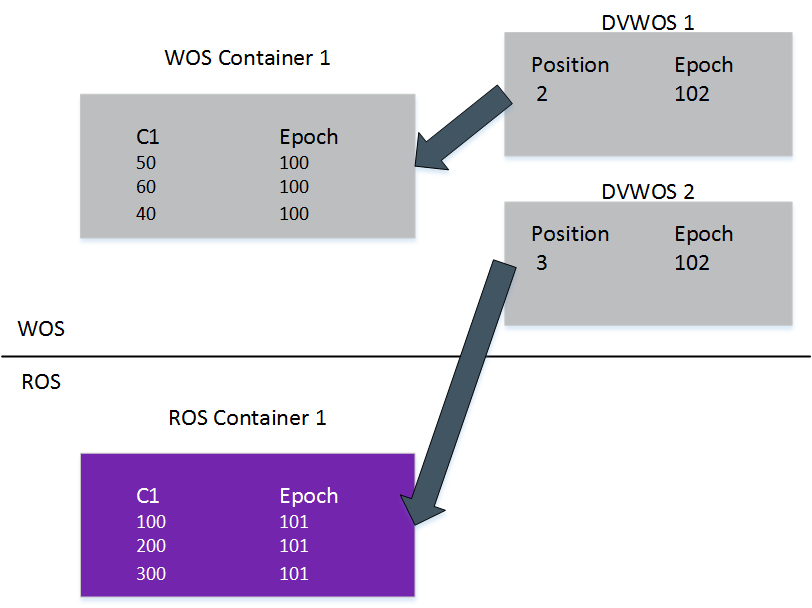
步骤 2:Tuple Mover 通过 Moveout 操作,将数据从 WOS 移动到 ROS,并在 ROS 中创建了删除向量 DVROS 1 和 DVROS 2 。
如图所示,在 moveout 操作之后,数据的位置发生了变化,DVROS 捕获了新的位置:
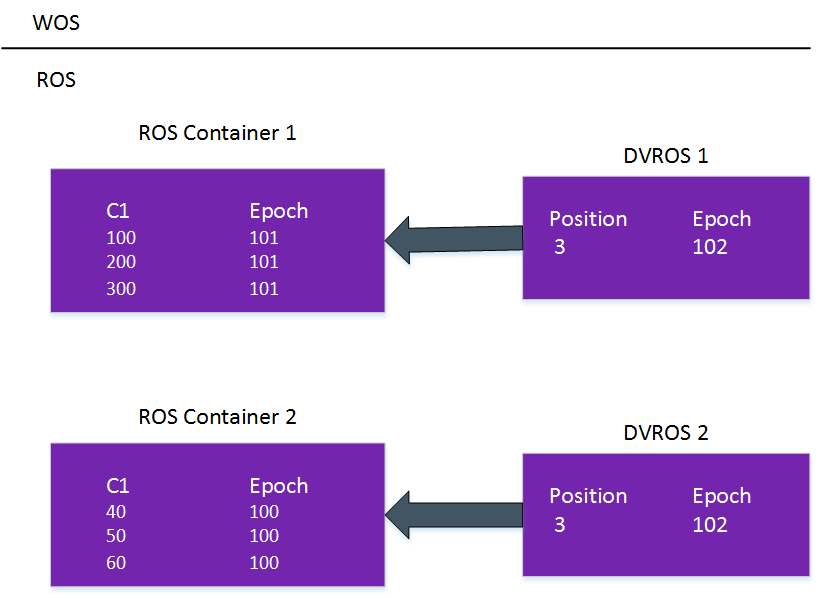
步骤 3:AHM 前进到 103。运行以下删除语句:
DELETE from Table1 where C1=200; commit;
DELETE /*+direct*/ from Table1 where c1=40; commit;
这两条语句分别在 Epoch = 105 和 Epoch = 106 提交。DELETE 语句会在内存中创建一个新的 DVWOS 容器,而使用 /*+direct*/ 的 DELETE 语句会直接在磁盘上创建一个 DVROS 容器。
此时一共有4个删除向量。
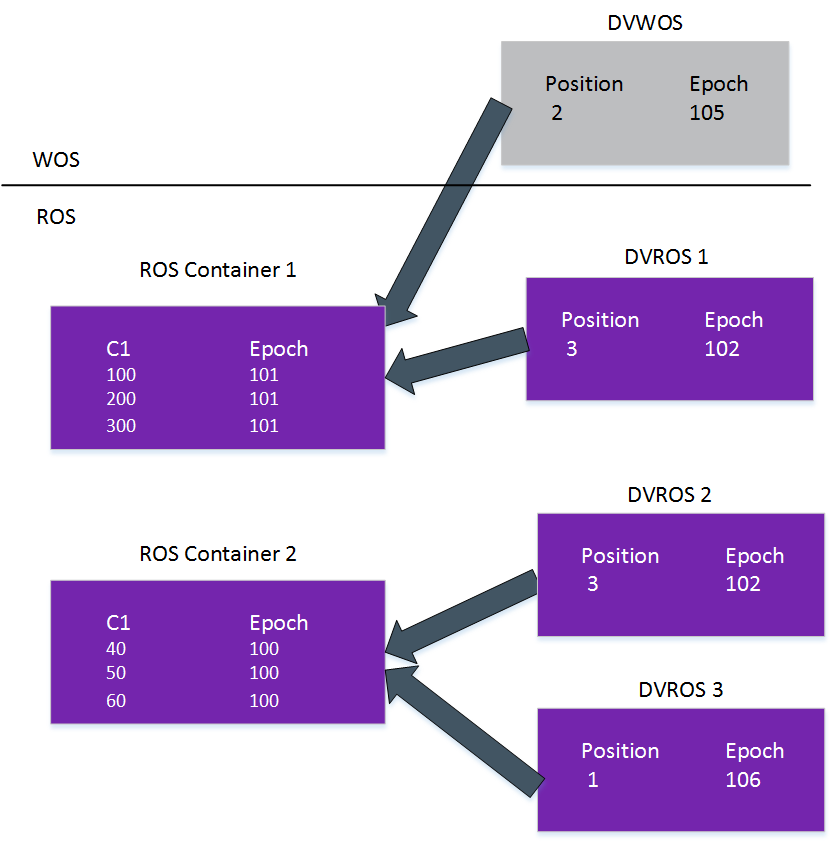
步骤 4:Tuple Mover 通过 Mergeout 操作,将所有的 ROS 容器合并为单个已排序的 ROS 容器。
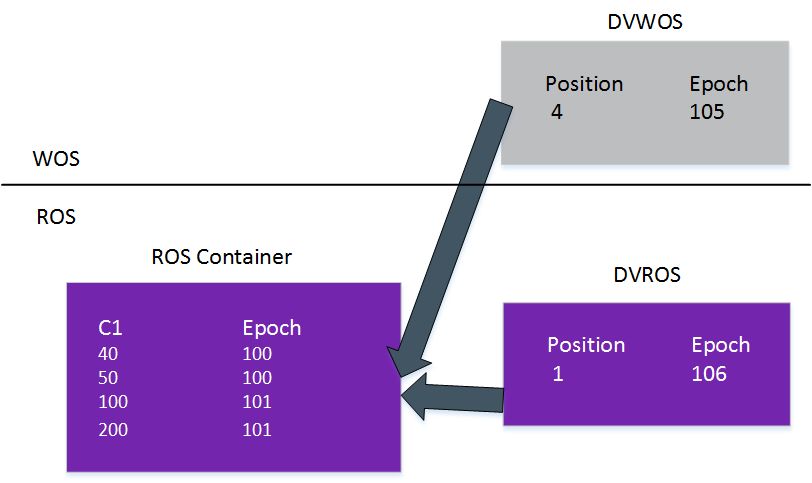
合并操作会清除 AHM = 103 之前删除的所有记录。下图显示在 epoch 105 和 106 中删除的数据未能清除,原因是 DELETE 语句提交的 Epoch 大于 AHM Epoch。
4、Projection 设计注意事项
4.1 应该如何设计投影以实现最佳 DELETE 和 Replay Delete 性能?
对于包含 DELETES 或 UPDATES 的表,请考虑以下投影设计注意事项。如果您的投影设计不符合这些注意事项,请创建新投影,执行刷新并删除旧投影。
4.1.1 DELETE 性能
如果 DELETE 语句中使用的谓词列存在于该表的所有投影中,则 DELETE 语句的性能最佳。
如果在表上的每个投影中都有谓词列,则 Vertica 选择优化的删除算法。
使用优化的删除算法,Vertica 可以根据这些谓词列为表上所有的 PROJECTION 快速定位需要删除的数据并创建删除向量。此算法速度很快,并且是默认行为。
如果表上有 PROJECTION 不包含 DELETE 语句的谓词列,Vertica 会从一个包含 DELETE 谓词列的投影中选择标记为删除的记录。然后搜索所有投影以查找构建删除向量所需的已删除记录的位置。这会导致 DELETE 操作变慢,性能大幅下降。
4.1.2 Replay Delete 性能
为了获得最佳的 Replay Delete 性能,应该在 PROJECTION 的 ORDER BY 末尾中放入一个基数最高的字段。Replay Delete 操作要求 Vertica 在新的存储容器中找到已删除记录的位置。Vertica 首先使用投影排序顺序中的列搜索已删除的记录。如果 ORDER BY 中有一个高基数列,Vertica 会更快地找到新位置。
在某些情况下,Vertica 无法使用排序顺序中的基数列来识别已删除行的确切位置。在这些情况下,Vertica 会匹配所有投影列,从而减慢重放删除操作的速度。
4.2 如何评估 PROJECTION 的 Replay Delete 性能?
使用以下语句评估单个投影或表上所有投影的 Replay Delete 性能。
=> SELECT EVALUATE_DELETE_PERFORMANCE ('projection or table name');
输出结果为:
- 未发现投影删除性能问题
或 - 投影显示删除性能问题,随后显示一系列问题
4.3 如何避免在 PROJECTION 恢复时 Replay Delete 操作花费太长时间?
当有节点宕机时,AHM Epoch 不会向前推进。当节点关闭或节点正在恢复时提交的 DELETE 语句的 Epoch 高于 AHM Epoch。作为恢复过程的一部分,必须在恢复节点上重放这些删除。如果目标表很大并且目标表上的投影不是为最佳删除或重放删除性能而设计的,则可能会出现问题。在这种情况下,执行 Replay Delete 时,投影可能会卡在恢复中。
如果遇到这种情况,请将现有投影替换为遵循最佳投影设计建议的投影。您可以通过在排序顺序末尾添加高基数列来执行此操作。
您可以使用以下命令评估重放删除性能:
=> SELECT EVALUATE_DELETE_PERFORMANCE ('projection or table name');
4.4 存在大量已删除记录会影响查询性能吗?
包含数亿条记录的表,如果已删除记录超过 20% 则会影响查询性能。如果查询执行全表扫描,并且在查询处理期间未修剪已删除的记录,则此类表可能会出现性能问题。
5、DELETE 数据的清除
5.1 Vertica 怎么清理已删除的数据?
清除存储容器中已删除的数据需要生成新的存储文件。清除已删除的记录的频率过高会导致 I/O 显著增加。由于 I/O 可能会显著增加,因此 Vertica 仅在存储容器由基于节点的操作重写时才会清除已删除的记录,例如:
- Recovery
- Reorganize
- Rebalance
- Refresh
- Tuple Mover Mergeout
合并操作会根据活动分区和无分区表的分层算法合并符合合并条件的 ROS 容器。在合并期间,Tuple Mover 会清除在 AHM Epoch 之前删除的符合条件的 ROS 容器中的任何记录。
创建新分区时,当前活动分区将变为非活动分区。最新非活动分区的 ROS 容器将合并到单个 ROS 容器中。在此过程中会清除在 AHM Epoch 之前删除的记录。
从非活动分区中删除记录时,如果 ROS 容器中已删除记录的百分比超过 20%,合并算法会从 ROS 容器中清除已删除的记录。PurgeMergeoutPercent 配置参数控制此百分比。
非活动分区的合并操作的优先级低于活动分区和无分区表中的合并操作。
此清除策略意味着,除非您执行手动清除,否则某些已删除记录的 ROS 容器可能不会被清除。
5.2 何时以及如何执行手动清除?
即使存储容器中只有一条已删除的记录,手动清除操作也会重写存储容器。除非您有一个包含数亿行且其中 20% 或更多是已删除记录的大型表,否则请避免运行手动清除。您可以运行以下查询来识别所有包含超过 1 亿条记录且其中 20% 或更多是已删除数据的表…
SELECT projection_name, sum(deleted_row_count)*100/sum(total_row_count) as percentage_deleted
FROM STORAGE_CONTAINERS
GROUP BY 1
HAVING sum(total_row_count) > 100000000
and sum(deleted_row_count) * 100/SUM(total_row_count) > 20
ORDER BY 2 DESC;
验证 AHM 是否顺利推进,并且投影是否针对 DELETE 和 Replay Delete 进行了优化。
在决定执行手动清除之前,请使用 DELETE_VECTORS 系统表检查要清除的已删除记录的提交时期。验证提交时期是否小于当前 AHM 时期。如果要从特定分区清除已删除的记录,请使用 PURGE_PARTITION 函数,因为它针对特定的 ROS 容器。
使用 PURGE_PROJECTION 函数针对所有包含删除并降低性能的 ROS 容器。
您可以运行以下查询来检测包含超过 20% 已删除数据的投影和分区。以下示例显示了一个包含 1 亿条记录的分区:
SELECT table_schema,
projection_name,
partition_key,
sum(deleted_row_count)*100/sum(ros_row_count) as percentage_deleted
FROM PARTITIONS
GROUP BY 1,2,3
HAVING sum(ros_row_count)> 100000000
and sum(deleted_row_count)*100/sum(ros_row_count)> 20
ORDER BY 2 DESC;
5.3 从单个表中删除大量数据时应遵循哪些最佳实践?
要从表中删除大量数据,请按照以下步骤操作:
1、使用以下命令将数据从 WOS 移出到 ROS:
SELECT do_tm_task('moveout', '<table_name>');
2、使用 DIRECT HINT 运行 DELETE 或 UPDATE 语句:
DELETE /*+direct*/ FROM <table_name> where <column1> = 1;
commit;
3、使用以下命令获取 AHM Epoch 的当前值:
SELECT get_ahm_epoch();
4、使用以下命令手动推进 AHM:
SELECT make_ahm_now();
5、验证 AHM 是否已推进:
SELECT get_ahm_epoch();
6、如果 DELETE 语句只删除了单个分区或几个分区的数据,请运行 PURGE_PARTITION 函数。否则,运行 PURGE_TABLE 函数。使用至少具有 4GB 查询预算的资源池运行 PURGE 命令。更高的预算可以提高 PURGE 命令的性能,尤其是在表较宽的情况下。您可以通过查询 RESOURCE_POOL_STATUS 系统表来查找资源池的查询预算。
如果已经删除了表中的大部分数据,则可以通过以下方式创建一个新表:
CREATE TABLE <new_table_name> like <table_name> ;
您可以在新表中插入必须保留的数据,然后交换表。

