




背景
收到客户oracle库在做truncate table卡住,从11点55分钟开始接近30分钟未执行完,该问题原来发生过,排查到是bug原因造成,并且已经打过补丁。
环境
| 硬件平台 & 操作系统 | Linux x86 64-bit |
|---|---|
| 操作系统版本 | |
| 内存 | 126G |
| Oracle产品及版本 | Oracle 11.2.0.4 |
问题排查细节
排查过程
下午到客户现场,检查awr报告和ash报告,发现等待事件如下:
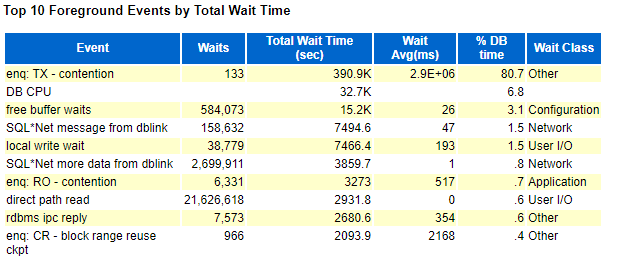
该事件与上次未打补丁的基本一致,检查sql执行情况,发现truncate确实执行并长时间未完成,如下:
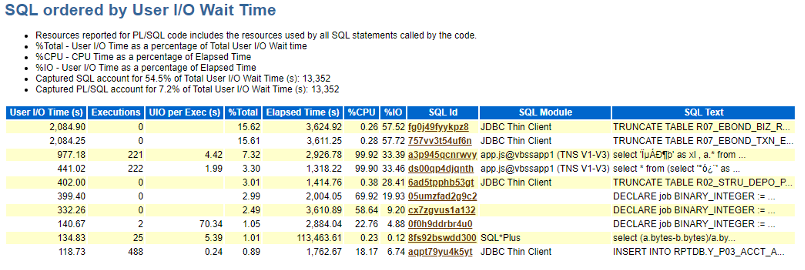
检查ash报告,主要存在“enq: TX - contention”事件,查询语句均是监控的语句:

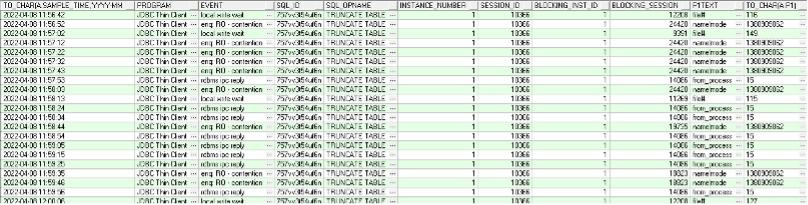
发现truncate table表的事件都是“enq: RO - contention”和“local write wait”,如下图;
由于该事件在打补丁后重复发生,4月8日下午通过升级,开SR(Service Requests)处理。
4月11日补充trace日志和ASH DUMP信息给SR,经过SR分析,造成该问题原因是:3个 Session(Sid:24420、10366、18823) 同时做 Truncate 处理,被 CKPT(sid:14086)、DBRW(sid:10330)进程阻塞,发生 enq: RO - contention,local write wait 等待。
问题原因
TRUNCATE 和 DROP TABLE 的时候,ORACLE 必须使 BUFFER Cache 中所有该对象的数据块失效或者刷新到磁盘。步骤:此时请求 RO 队列锁,找缓冲区中该对象的块,并使其无效化或者刷新到磁盘,然后释放 RO 锁,如果多个进程并发地进行 TRUNCATE 的时候,就会在 RO 队列上发生竞争,表现为等待事件 enq: RO fast object reuse或者 . enq: RO - contention。如果 TRUNCATE 等待 DBWR 相关的块刷新到磁盘,就表现为等待时间 local write wait。
也就是说 TRUNCATE 动作会等待 CKPT、DBWR 执行 Checkpoint 把 Dirty Buffer Data 全部写入到 Disk。
所以,等待时间取决于以下因素。
- Buffer Cache 状况(Buffer Cache 越大,等待事件可能越长)
- I/O 状况(I/O 越慢,等待事件越长)
- 并行 TRUNCATE(并行越多,RO enqueue 的等待越显著)。
通过 AWR Report 来看,db file async I/O submit 的平均等待事件很长,说明 System I/O 很慢。
总结建议
1、TRUNCATE 处理不要多个并发处理,避免 RO Enqueue 锁的争用。
2、TRUNCATE 处理建议放在业务空闲时间段实施,避免 Checkpoint 操作时的等待。
通过 alert log 来看,问题发生时间段 log switch 非常频繁。
3、通过 OS 层面确认 I/O performance,改善 db file async I/O submit 等待的时间。
4、对于要频繁 Truncate 的表可以使用不同的 Buffer Pool(比如:KEEP Pool、Recycle Pool),
使得 Buffer Cache 使用上没有争用。

