





凭安征信作为央行上海总部备案的企业征信机构以及国家中小企业公共服务示范平台,承担着为中国超过1.5亿的市场主体提供综合信用服务的重要角色。面向小微企业这一庞大且多元化的市场,凭安征信采集、分析、加工并整理企业的信用信息,已形成深具影响力的系列服务和产品。旗下的水滴信用产品已成功服务超过1000万小微企业,同时还与银行、证券公司、央国企等多个行业的头部客户保持紧密合作,有效促进了信用信息的健康流动和行业透明度。
凭安征信对客服务的基础是企业信用大数据,提供全国3.3 亿 + 多维度企业信息,涵盖企业背景、实际控制人、对外投资、融资历史、股权结构、法律诉讼等。凭安将采集的原始数据经过数据加工、清洗、关联之后形成大规模的结构化数据保存在MySQL数据库中。
凭安征信作为一家对外提供企业数据服务的公司,数据库是其技术栈的核心组成部分。近年来,企业数量持续上升,政策法规日益增多,外部服务指标也在不断拓展。加之在信息化时代的大背景下,企业信息变更频繁,客户服务的并发调用需求显著增加,这对凭安征信的技术架构带来了更大挑战,尤其对作为核心数据存储的数据库而言,压力尤为严峻。数据库面临扩展性、一致性和运维等方面的挑战。
为了解决业务痛点,凭安征信将数据从传统MySQL数据库迁移到了阿里云云原生数据库PolarDB。PolarDB基于云原生架构,计算存储分离,软硬件一体化设计,为用户提供具备超高弹性和性能、高可用和高可靠保障、高性价比的数据库服务。
存算分离架构解决性能瓶颈
凭安征信原先使用的传统MySQL数据库使用本地盘,存储空间有限(最大支持2TB空间),无法支撑不断膨胀的数据量,且资源扩容不灵活,增加只读计算节点通常需要数小时的时间,无法有效维系24h业务的连续性要求。尤其是在每年审计期间,业务高峰来临,添加只读节点缓慢加剧了主库压力。
此外,传统MySQL数据库采用集中式存储,IOPS性能不高。作为工信部认定的“国家中小企业公共服务示范平台”,凭安征信的数据系统每天24小时不间断地被调用,无法很好地应对业务极高的IOPS压力,甚至在严重情况下会导致高可用(HA)切换。
PolarDB采用计算与存储分离架构「注1」,使得数据库服务器的CPU、内存能够快速扩容,只需数分钟即可完成集群配置升降级,满足公共云计算环境下根据业务发展弹性扩展集群的刚性需求。当业务需要更多资源的时候,客户新增一个节点仅需1分钟左右,做到了极致的快速弹性。正是因为存算分离的架构,PolarDB的共享存储IOPS一般是同规格传统MySQL的2~5倍,直接、有效地解决了因IO带来的业务访问压力问题。
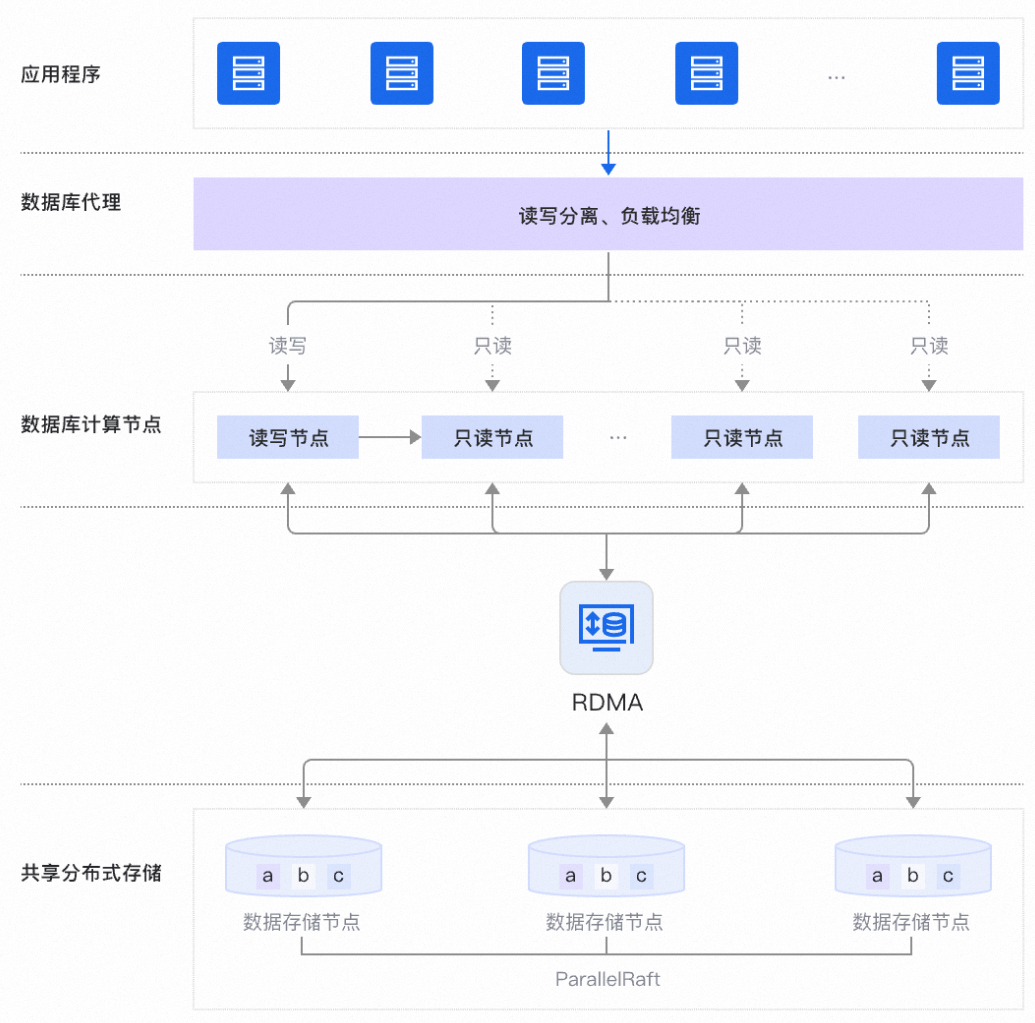
PolarDB支持大容量数据存储,单实例最大可以支持500TB的存储空间。此外,PolarDB还实现了共享分布式存储,多个计算节点共享一份数据,而不是每个计算节点都存储一份数据,可以极大地降低存储成本。基于全新打造的分布式块存储和文件系统,PolarDB的存储容量可以在线平滑扩展,不会受到单个数据库服务器的存储容量限制,可应对上百TB级别的数据规模。
凭安征信选择十余个PolarDB实例来承载企业信用大数据,无需扩容,很好地满足了日益增长的大数据量需求,解决了存储空间不足、资源扩容不灵活、IOPS性能差的问题。
并行DDL和秒级加字段优化大表操作效率
在凭安的数据库系统里,部分表的数据量非常大,如商标数据、司法数据表已达3亿行,预计未来会增长到10亿行。在运维过程中,随着客户数量和信息维度的增加,数据量也在不断攀升。这导致大表的DDL操作(如增加索引、增加列)变得异常缓慢,进而影响了外部服务的响应效率,无法保障征信产品的高口碑。随着时间和数据累积,更改表困难,运维人员只能在凌晨业务相对低峰期进行操作,操作复杂且工作量重。
并行DDL
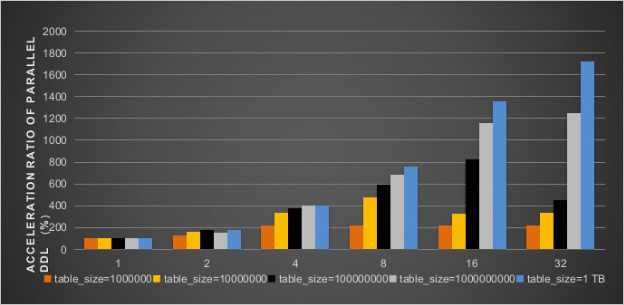
PolarDB支持并行DDL「注2」,充分利用多核多线程能力加速支持创建主键索引和二级索引(不包括全文索引、空间索引和虚拟列上的二级索引)的DDL操作。当数据库硬件资源空闲时,可以通过并行DDL功能加速DDL执行,避免阻塞后续相关的DML操作,缩短执行DDL操作的窗口期。
在一个规格为16核128 GB的PolarDB MySQL标准版8.0版本集群上进行测试,集群存储空间为50 TB。
通过如下语句创建一张名为 t0
的表:
CREATE TABLE t0(a INT PRIMARY KEY,b INT) ENGINE=InnoDB;复制
通过如下语句生成测试数据:
DELIMITER //CREATE PROCEDURE populate_t0()BEGINDECLARE i int DEFAULT 1;WHILE (i <= $table_size) DOINSERT INTO t0 VALUES (i, 1000000 * RAND());SET i = i + 1;END WHILE;END //DELIMITER ;CALL populate_t0() ;复制
并行DDL加速比效果如下图所示:
秒级加字段
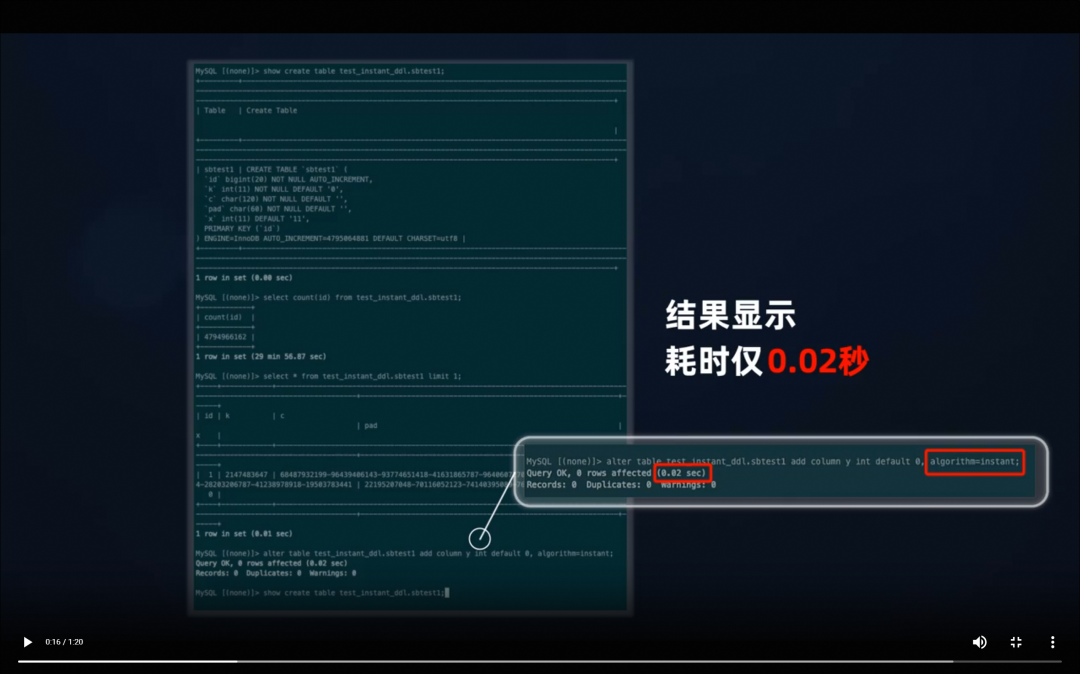
在使用传统MySQL数据库执行加列操作时,需要重建整个表数据,占用大量系统资源。PolarDB支持秒级加字段功能「注3」,在加列操作时只需变更表定义信息,无需修改已有数据,可在秒级完成对上亿级别表的加列操作。
在PolarDB中,需要开启loose_innodb_support_instant_add_column
参数,并通过如下语句指定ALGORITHM=INSTANT
以强制使用秒级加字段功能:
ALTER TABLE test.t ADD COLUMN test_column int, ALGORITHM=INSTANT;复制
在1TB数据量的表中使用秒级加字段功能进行加列操作,结果显示耗时仅0.02秒。
高性能全局一致性保障数据0时延
凭安征信对接的客户涵盖银行、金融服务商等对数据一致性要求极高的行业。由于司法数据和企业工商信息的唯一性,必须确保及时更新且准确无误,如有错误不仅可能引发投诉,还会对企业口碑造成负面影响。在金融场景中,部分数据如银行四要素验证和企业经营状态信息对时效性要求尤其严格,写入数据库后必须立即可供业务读取。凭安所使用的传统MySQL数据库只读节点和主节点之间存在时延,经常读取错误或者读到历史数据,出现过数据不一致现象,无法最大程度保障高可用,这对金融数据服务公司来说是非常严重的问题。
PolarDB具备高性能全局一致性「注4」。高性能全局一致性是对原有全局一致性级别的升级,具有比全局一致性更严格的强一致性要求。此功能特性实现了数据在横向扩容的RO节点上跟RW节点的写入数据同步,数据0延迟。
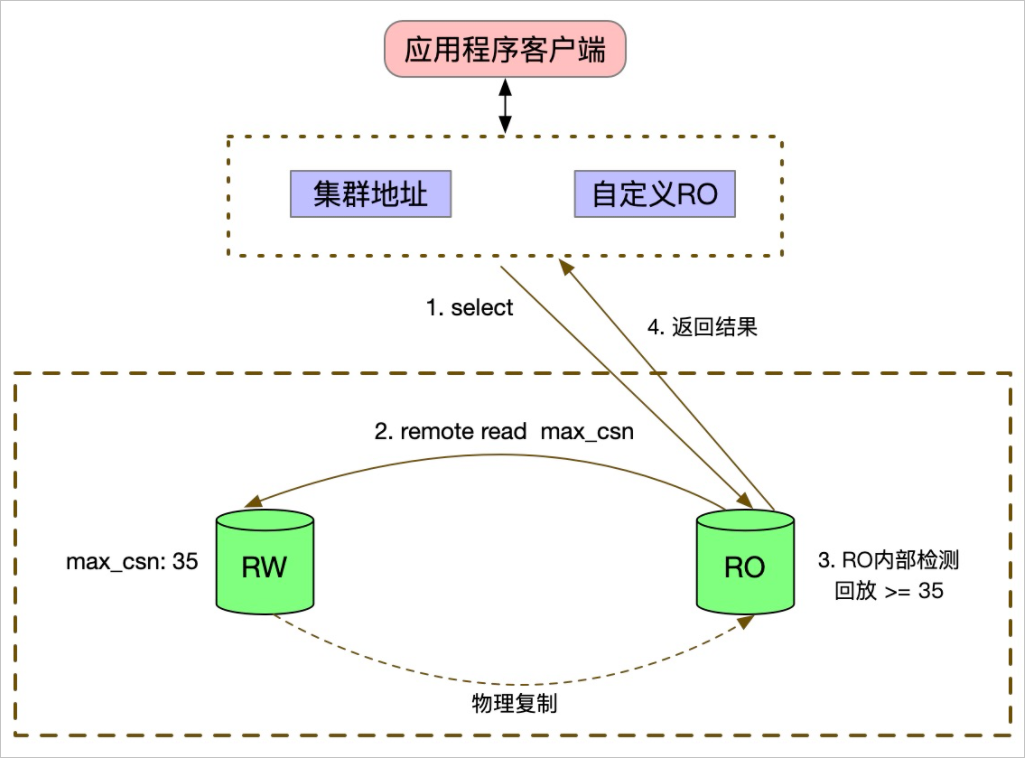
传统数据库在主节点和从节点之间通过日志流进行同步,这种架构已经沿用了几十年。PolarDB 改变了这种方式,利用RDMA(Remote Direct Memory Access,远程直接内存访问)技术实现多个计算节点间数据、信息的直接交互,实现了性能无衰减的RO节点全局强一致读。在高性能全局一致性中,RO节点通过RDMA one-side remote read获取RW节点上当前最新的提交时间戳,用于计算当前的事务延迟情况,构建强一致性读视图。
此外,PolarDB结合PolarProxy,实现了跨计算节点事务一致性,任何事务内的写前读和写后读均可以分流到只读节点中,这样就保障了凭安征信在处理企业数据的时候,任何时间点读取的数据都是最新的数据。
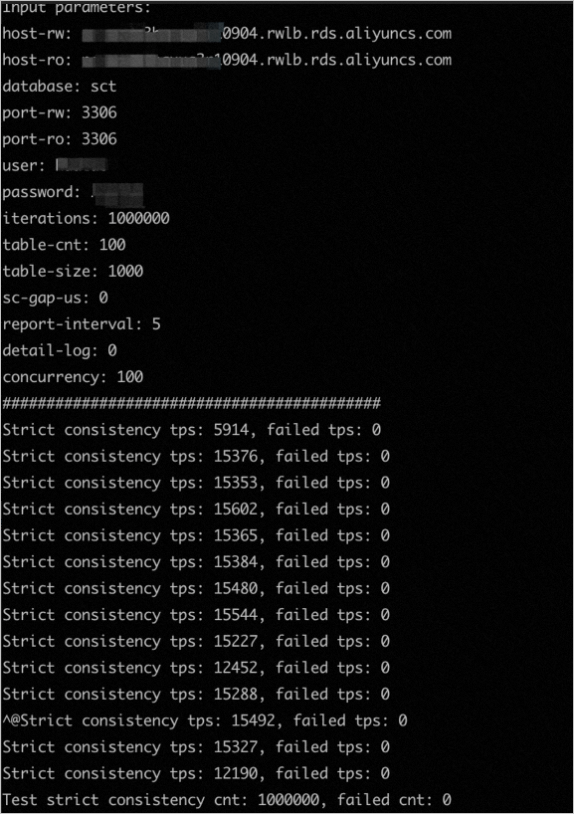
开启高性能全局一致性模式后,执行如下命令来进行一致性测试:
./mysqlsct--host-rw=pc-**********.rwlb.rds.aliyuncs.com //测试环境中PolarDB MySQL版的集群地址。host-rw与host-ro的集群地址相同。--host-ro=pc-**********.rwlb.rds.aliyuncs.com //测试环境中PolarDB MySQL版的集群地址。host-ro与host-rw的集群地址相同。--port-rw=3306 //测试环境中PolarDB MySQL版的集群地址端口--port-ro=3306 //测试环境中PolarDB MySQL版的集群地址端口--user=****** //PolarDB MySQL版的集群测试账号--password=****** //PolarDB MySQL版的集群测试密码--iterations=1000000 //测试总次数(一次update+一次select为一次测试)--table-cnt=100 //测试表数量--table-size=1000 //测试表行数--concurrency=100 //测试并发线程数--database=sct //测试数据库--sc-gap-us=0 //update和select之间的休眠时间, 0表示update后立刻发起查询--report-interval=5 //打印日志间隔--detail-log=0 //不输出详细错误日志复制
复制
测试结果如下图所示:
复制
复制
通过引入PolarDB,凭安征信的数据系统得到了显著的优化。首先,PolarDB通过分离架构有效分担了查询压力,确保了高峰期业务的连续性和稳定性,为客户提供了及时、准确的数据服务,避免了因数据不一致而导致的潜在风险。其次,PolarDB的并行DDL机制使得运维效率显著提升,运维人员不再需要在业务低峰期进行繁琐的表更改,工作量得到大幅减轻。
总结而言,凭安征信通过引入PolarDB,克服了传统MySQL带来的性能瓶颈,提升了业务的敏捷性和高可用性,成功应对了日益复杂的市场需求和业务挑战。
客户反馈
"阿里云PolarDB帮助我们解决了很多业务难题。PolarDB通过计算存储分离架构,实现了高效扩容和数据读取稳定性,大幅提升了运维效率。”
——凭安征信联合创始人兼CTO 徐骥
注释
注1: https://help.aliyun.com/zh/polardb/polardb-for-mysql/what-is-polardb-for-mysql-enterprise-edition
注2:https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/parallel-ddl
注3:https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/instant-add-column
注4:https://help.aliyun.com/zh/polardb/polardb-for-mysql/user-guide/scc
