




使用 pgvector 创建向量索引非常简单 - 只需运行CREATE INDEX ON t USING hnsw(col vector_l2_ops)。但是当我们运行它并插入或修改数据时,实际上发生了什么?
在本文中,我们将深入了解pgvectorPostgres 中创建的底层索引文件。
Postgres 存储概述
pgvector在深入了解索引存储之前,让我们快速回顾一下 Postgres 如何存储数据。
Postgres 将关系(即表和索引)存储在磁盘上的文件中。每个文件在逻辑上分为多个页面,每个页面默认为 8KB。页面通常具有以下结构:
| 物品 | 描述 |
|---|---|
| 商品编号数据 | 指向实际项目的项目标识符数组。每个条目都是一个(偏移量,长度)对。每个项目 4 个字节。 |
| 可用空间 | 页面上最右侧的 ItemId 和最左侧的 Item 之间的未分配空间。新项目标识符从此区域的开头分配,新项目从结尾分配。 |
| 项目 | 实际物品本身。 |
| 特殊空间 | 索引访问方法特定的数据。不同的方法存储不同的数据。在普通表中为空。 |
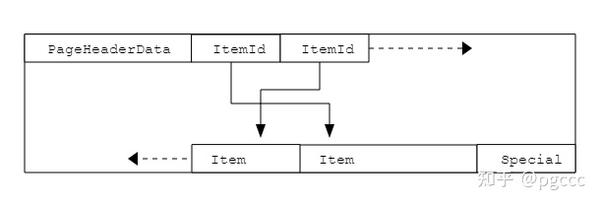
补充:有人可能会问,为什么还要有 ItemID?为什么不一个接一个地列出项目?答案是,当前设计允许重新排序。页面外的实体通过 ItemID 引用页面,只有页面本身知道相应项目的位置。这意味着,如果删除了某些项目,并且页面上有碎片,Postgres 可以在内部对项目进行碎片整理和重新排序,而不必担心外部引用。
有关更多详细信息,请参阅Postgres 的文档。
pgvector索引元数据页面
HNSWpgvector索引页分为两类:元数据页(第 0 页)和包含 HNSW 图表的其余页面。
元数据页包含 Postgres 页眉(每个页都需要)、一个结构体,以及页尾的HnswMetaPageData一个结构体。HnswPageOpaqueData
从视觉上看,元数据页面具有以下结构:

页面数据
该HnswMetaPageData结构包含用于管理 HNSW 索引的元数据。这定义了 HNSW 图的配置和操作参数。
typedef struct HnswMetaPageData {
uint32 magicNumber;
uint32 version;
uint32 dimensions;
uint16 m;
uint16 efConstruction;
BlockNumber entryBlkno;
OffsetNumber entryOffno;
int16 entryLevel;
BlockNumber insertPage;
} HnswMetaPageData;复制magicNumber→ 常数,0xA953A953十六进制数,用于检测早期潜在的标题损坏或意外的页面结构不匹配。
version→ 包含索引布局版本(目前为 1)。如果索引在磁盘中的存储方式发生重大变化,这可以帮助区分索引文件。
dimensions→ Vector 元素的尺寸
m→ HNSW 参数决定了图中节点(或数据点)可以拥有的最大连接数(或边数)
efConstruction→ HNSW 参数决定了每个元素在构建阶段要探索的候选邻居的数量
entryBlkno和entryOffno→ HNSW 图的条目元素在索引页中的位置
entryLevel→ HNSW 图中条目元素的级别
insertPage→ 应插入新元素的 Postgres 索引页码
HnswPageOpaqueData
用于HnswPageOpaqueData索引内的页面管理。它有助于组织索引页。
typedef struct HnswPageOpaqueData {
BlockNumber nextblkno;
uint16 unused;
uint16 page_id; /* for identification of HNSW indexes */
} HnswPageOpaqueData;复制nextblkno→ 下一页的块号(用于真空操作)
unused→ 保留以供以后使用
page_id→ 标记该页面为 HNSW 索引页
pgvector 索引页
元数据页之后是索引页,其中包含索引的核心组件。pgvector 的 HNSW 索引页具有以下结构:

它遵循 Postgres 页面的一般结构。它以 PageHeaderData 开始,以特殊空间结束。ItemIdData 空间包含Line Item Pointers 数组,它们是页面中每个元素的相对偏移量(以字节为单位),实际索引元素存储在 Items 空间中。
索引元素分为2种类型:元素元组和邻居信息元组。
元素元组
元素元组包含有关 HNSW 图节点的信息。底层结构如下。
typedef struct HnswElementTupleData {
uint8 type;
uint8 level;
uint8 deleted;
uint8 unused;
ItemPointerData heaptids[10];
ItemPointerData neighbortid;
uint16 unused2;
Vector data;
} HnswElementTupleData;复制type→ 常量,表示元组是邻居信息元素还是实际图形元素。对于元素元组,它将是HNSW_ELEMENT_TUPLE_TYPE(1)
level→ HNSW 图中元素的级别
deleted→ 清理(非满)后,如果删除了元素的所有表行,则该元素将被标记为已删除,其数据将清零。然后可以在新插入期间覆盖此元素,从而节省存储空间。
unused并且unused2→这些属性目前未使用,保留以供将来使用,以免改变存储布局。
heaptids[10]→ 这是指向实际表行的 TID 数组。您可能认为单个属性heaptid就足够了,因为每个图形元素将与表行进行一对一映射,但有pgvector两种情况可以进行优化:
- 重复元素将插入表中
- 非热更新将增加索引大小
neighbortid→ TID 指针,指向索引页内的元组,其中包含有关元素最近邻居的信息。
data→ 这是矢量数据
邻居信息元组
现在让我们看一下邻居信息元组,它提供了有关图节点的邻居的信息。底层结构如下。
typedef struct HnswNeighborTupleData
{
uint8 type;
uint8 unused;
uint16 count;
ItemPointerData indextids[FLEXIBLE_ARRAY_MEMBER];
} HnswNeighborTupleData;复制type→ 常量,指示元组是邻居信息元素还是实际图形元素。对于邻居元组,它将是HNSW_NEIGHBOR_TUPLE_TYPE(2)
unused→ 保留以供将来使用
countindextids→数组大小
indextids→ 索引页内的 TID 指针(元素的邻居)。此数组的大小取决于M图形和level元素的参数,计算方式如下:(level + 2) * m
可视化索引页
让我们尝试通过将结构映射到 JSON 表示来可视化索引元组的连接,以便更好地了解幕后发生的情况。
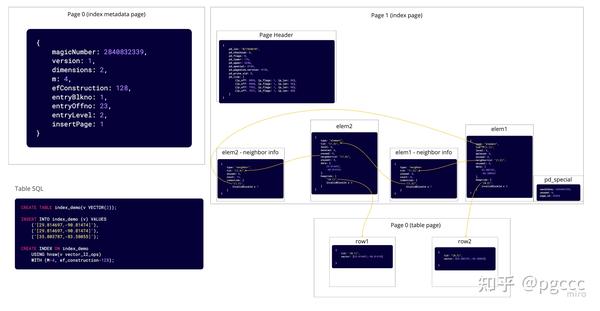
在本例中,我们创建了一个包含 2 行的表。然后,我们在数据上创建了一个 HNSW 索引。为此,pgvector 将创建 2 个索引页:元数据页(第 0 页)和用于保存 HNSW 图的页。我们可以看到索引页上插入了 4 个元组:一个用于每行的元素元组,一个用于每行的邻居信息元组。
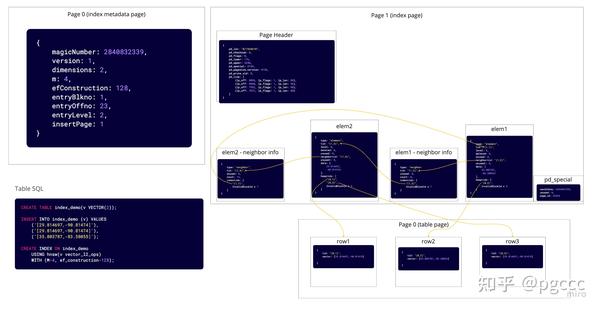
然后,当我们在表中插入一个新行,该行具有与第一行相同的值时。人们可能期望在该行的索引页上添加一个新元素和邻居元组,但由于我们前面提到的优化——第一行和第三行的值相同,它们将共享一个元素元组和一个邻居信息元组。元素元组的 heaptids 数组将包含指向第一行和第二行的指针。
将索引文件的十六进制转储映射到结构体
现在让我们看看实际的字节如何映射到上面描述的结构。
首先,我们将生成索引文件的十六进制转储。要找到该文件,我们可以使用以下查询:
testvec@hostname| 64046=# SELECT pg_relation_filepath('index_demo_v_idx');
pg_relation_filepath
----------------------
base/1154333/1172326
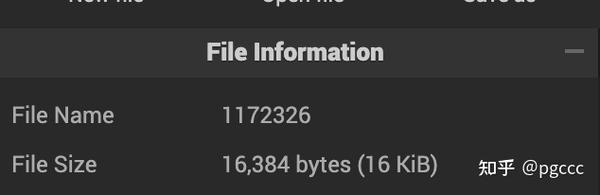
(1 row)复制现在我们可以在以下位置找到索引文件$PGDATA/base/1154333/1172326
我们可以观察到该文件大小为 16KiB,这意味着有 2 页(因为 Postgres 默认每页为 8KiB)。
使用 010 编辑器和模板,我们可以将十六进制字节映射到 pgvector 结构。在第一页上,我们可以看到 PageHeaderData 和 HnswMetaPageData 结构:
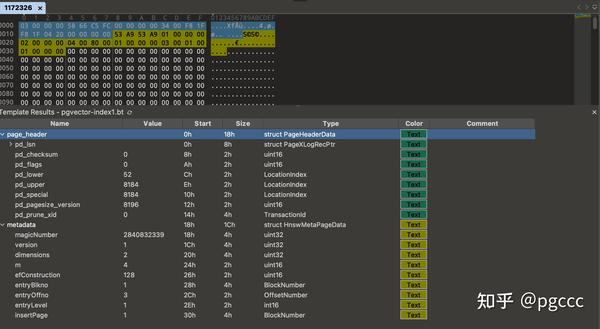
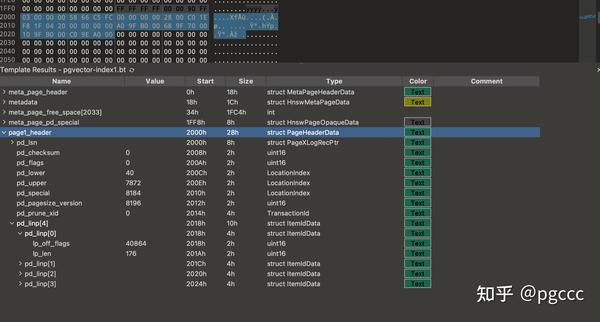
紧接着pd_special元数据页的特殊部分 ( ),第一个索引页开始。此页面的标题包含行指针 (pd_linp),其中包含 4 个元素:
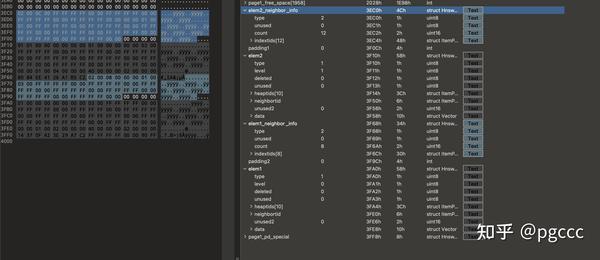
在空闲空间之后,我们可以找到索引元素(元素元组和邻居信息元组):
#PG证书#PG考试#postgresql初级#postgresql中级#postgresql高级



