




写在前面
 。
。

扫描二维码更精彩
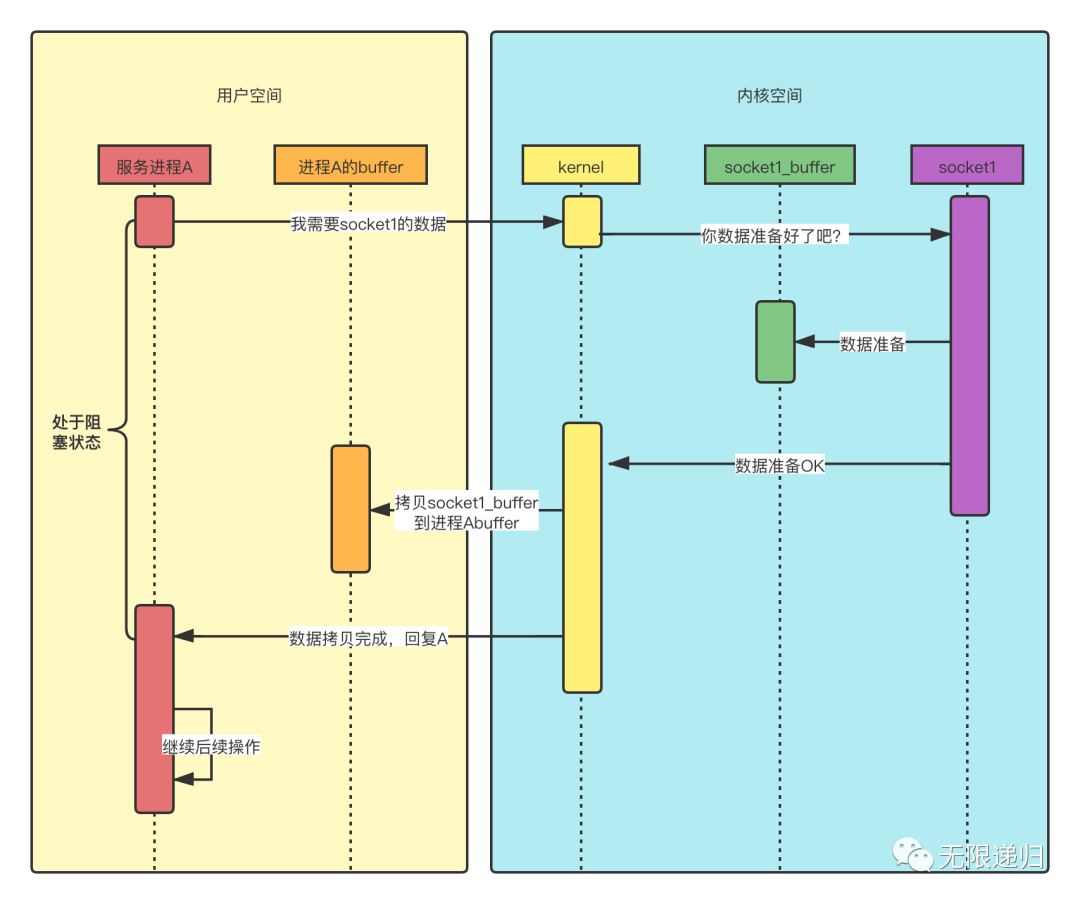
上图即为阻塞IO模型读取数据的时序图:线程A想要读socket1的数据,这时它发起系统调用,向kernel要数据,但是由于数据还没准备好,所以它发起读取请求后,就阻塞住了,直到数据准备好了,然后kernel把数据从socket1缓冲区拷贝到进程A的缓冲区后,才给进程A做出响应,然后进程A才能继续做后续操作。

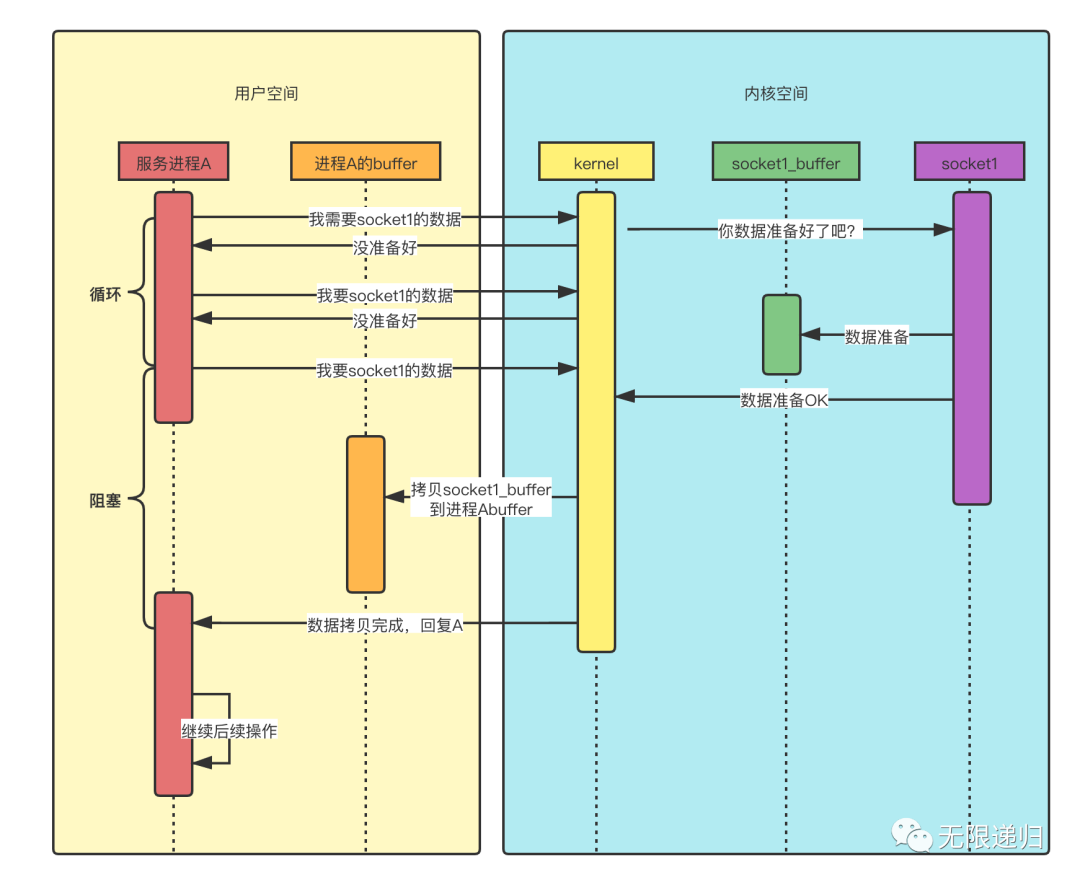
这个图呢就是非阻塞IO模型读取数据的时序图:从图中可以看出,与阻塞IO模型不同的是,当数据未准备好的时候,kernel会先返回给进程A一个消息,告诉它还没准备好,这时进程A就会搞一个while循环,一直在这里不停的问kernel数据好了没(在每次询问之间进程A还是可以做一点其他事情的,而不是像阻塞IO那样啥也不能做,就一直等着),直到数据准备好了,然后开始阻塞住,等待数据拷贝完成,kernel再回复进程A,进程A就可以处理数据了。这里的非阻塞是指发出要数据的请求后,kernel直接会给出一个数据还没准备好的答复,而不像阻塞IO那样,一个回音都没有。但是后面数据准备好了,在数据拷贝的过程中,进程A依然是阻塞的,要等到kernel拷贝好数据后给出答复再进行数据处理。
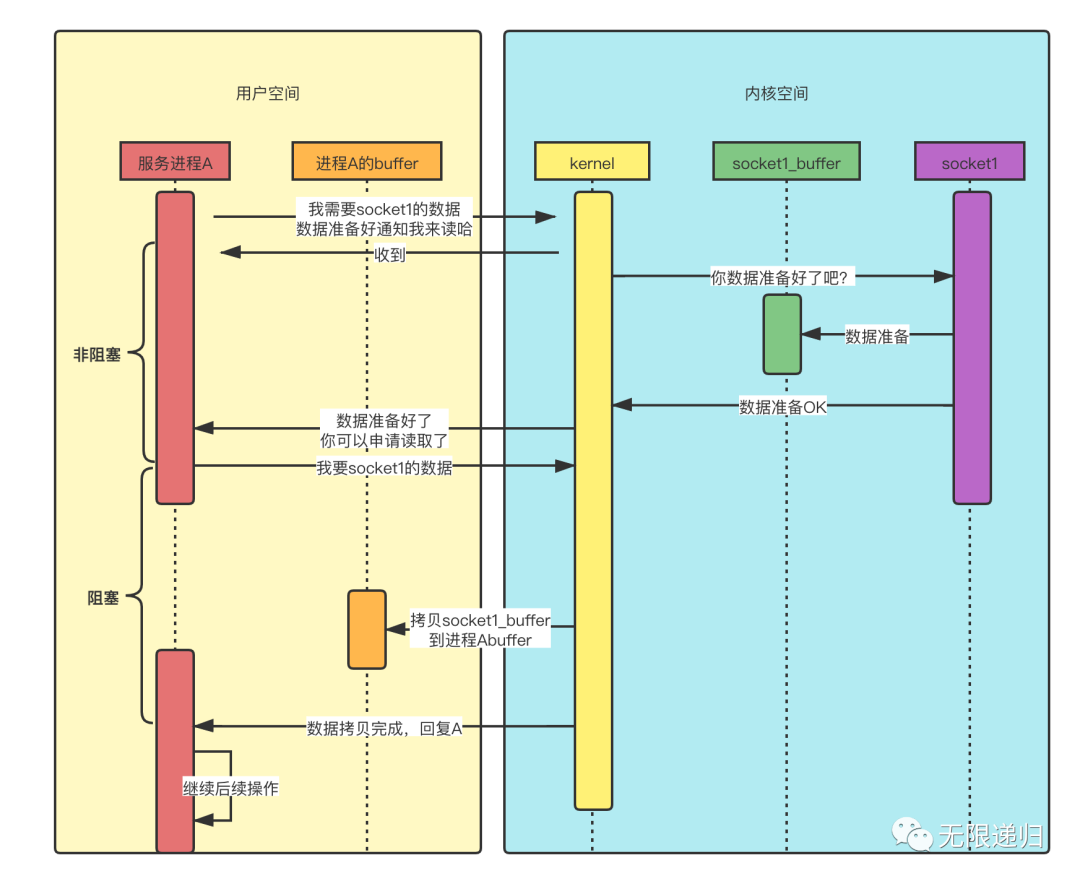
那这张图呢就是信号量IO模型的时序图了:这个过程呢,就是进程A和kernel说,“老哥,我要socket1的数据,它数据准备好了你和我说昂”,然后kernel就回复它“好的”。过了一会数据准备好了,kernel就通知进程A说:“数据好了,你来拿吧”,然后进程A就再次发起拿数据的请求,然后阻塞住,等kernel把数据拷贝到了它的buffer中后,通知它数据拷贝好了,然后进程A就可以愉快的处理数据了。相较于非阻塞IO模型,信号量模型不用循环的询问数据是否准备好了,只需要等数据准备好kernel发信号通知它来拿数据就可以了。
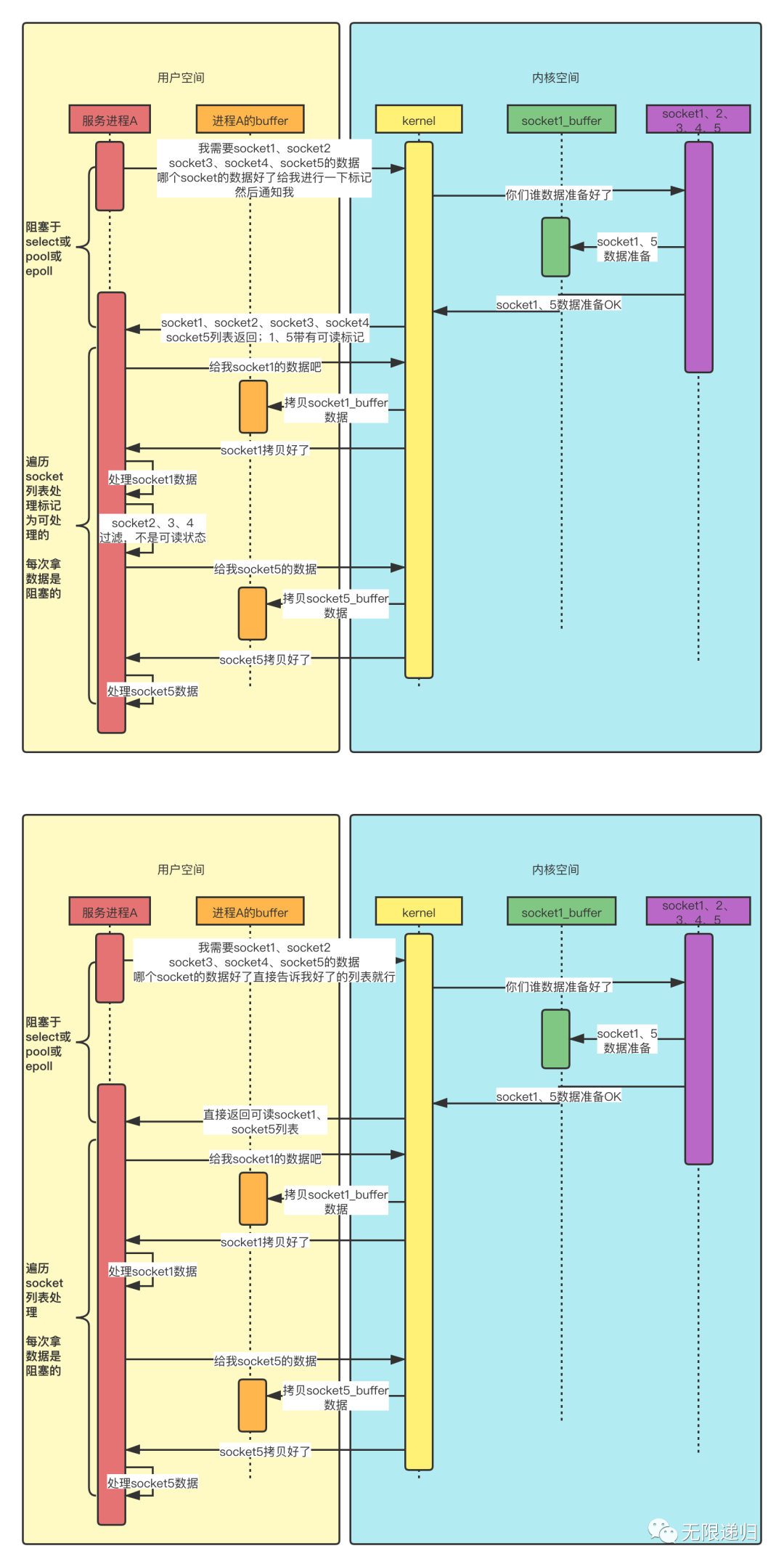
那这个图呢就是多路复用IO模型的时序图:为啥它画了两张呢?因为它的实现方式有这么几种:select、poll、epoll、kqueue。这里的两张图分别是select(也可以代表poll的)和epoll。我们需要好好看看这两张图与上面三种方式的不同之处。经过仔细对比,可以看出,两个图中,进程A一次向kernel要了好几个socket的数据,这就是多路,即一个进程可以实现对多个socket的监听。那么从图中我们可以看出select和epoll方式的不同之处在于kernel在返回socket列表时,select是返回的所有传入的socket,只是在这个socket列表中标记了哪些socket是可以处理的了,这样进程A就需要再遍历一遍所有的socket,然后只处理数据准备好的socket。而epoll的方式,kernel返回的socket列表就是所有的可以处理的socket了,进程A只需要遍历socket列表进行处理就可以了。poll方式与select方式相似,只是select监听的sockets个数是有限制的,而poll是没有限制的。从时序图中我们还可以看出,在处理socket的过程中,数据的拷贝过程还是会阻塞进程A的,只有数据拷贝完成后,进程A才能继续工作。
Redis中的单进程模型中使用的就是这种IO模型,不过它在外层针对这个模型又进行了一次封装,将对应的事件转换成了自己定义的事件类型,具体可以看Redis日记20210904--文件事件模型。IO多路复用模型的使用也是Redis如此之快的原因之一。
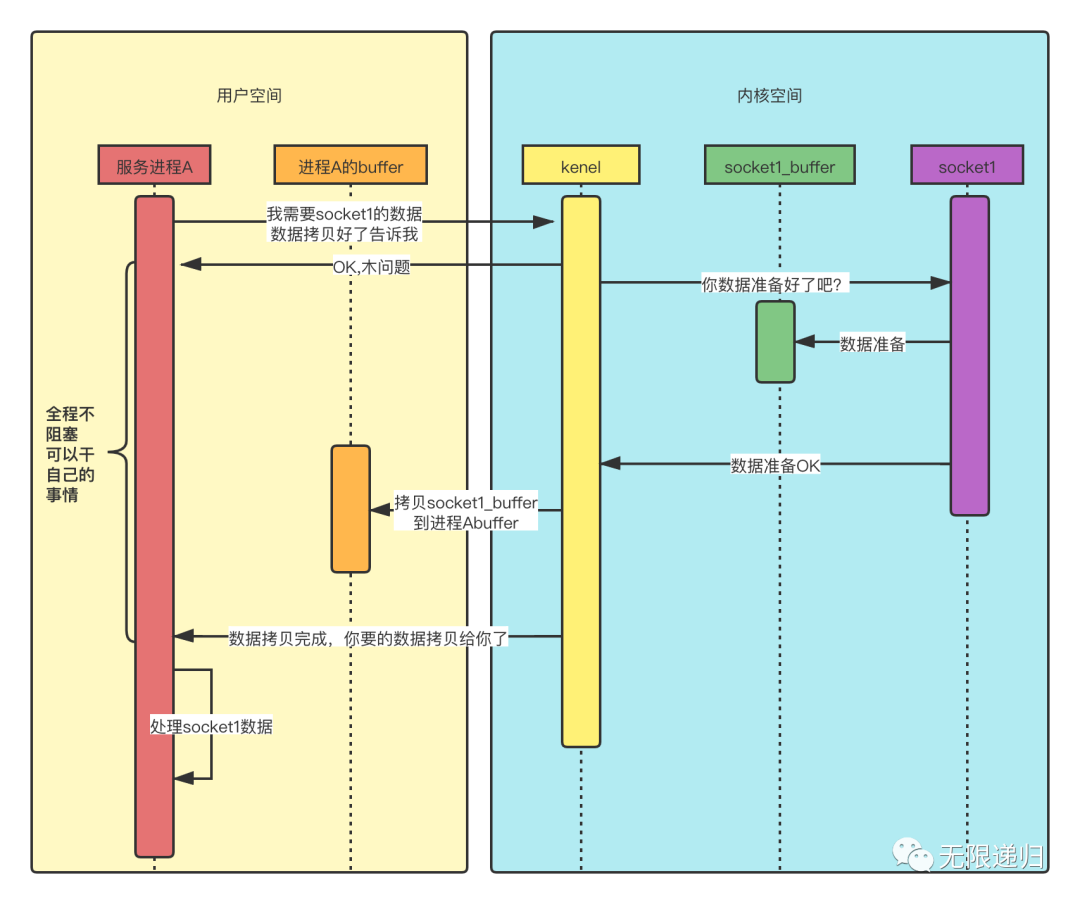
最后这个就是异步IO模型的时序图:从图中我们可以看到这种模型不存在进程A阻塞的情况。进程A只需要告诉kernel我需要socket1的数据,然后就可以去优哉游哉的干别的事情了,kernel在数据准备好并且拷贝好后,会直接通知进程A,说数据拷贝到你家里了哈,你可以处理了,这时进程A只需要回到家里拿数据处理就行了。

最后总结一下:
同步模型包括:阻塞IO模型、非阻塞IO模型、信号量IO模型、多路复用IO模型
异步模型包括:异步IO模型
同步是指在数据准备和数据拷贝的过程中,进程A是处于阻塞状态的,不能干其他的事情。
异步则是指在数据准备和数据拷贝过程中,进程A全程都不用关心,可以一直做别的事情,只需要等着kernel通知,然后进行数据处理就可以了。

往期推荐


扫码关注更多精彩
