





在本文中,我们重点介绍使用 Anteon 的 Kubernetes PostgreSQL 监控功能来监控 PostgreSQL 数据库。
译自Monitoring PostgreSQL Database on Kubernetes using eBPF,作者 Teodor Podobnik Guest Writer。
在这篇博文中,我们将重点介绍如何使用 Kubernetes PostgreSQL 监控功能监控 PostgreSQL 数据库。具体来说,我们将展示我们如何跟踪各种客户端查询,并帮助我们的客户识别潜在的 数据库瓶颈。
我们将从理论概述开始,最后以一个你可以自己运行的实用代码示例作为结束。
监控 PostgreSQL 数据库
监控数据库不仅对于深入了解资源利用率和故障检测至关重要,而且对于优化应用程序性能、检测恶意流量、管理和规划成本以及防止宕机也至关重要。这适用于所有类型的 数据库,包括使用最广泛的 数据库之一:PostgreSQL。
PostgreSQL 协议
PostgreSQL 使用基于消息的协议在客户端和服务器之间进行通信,通过 TCP/IP 和 Unix 域套接字进行操作。虽然 IANA 注册的默认 TCP 端口是 5432,但可以使用任何非特权端口。为了避免混淆,我们将前端称为 数据库客户端,将后端称为 数据库服务器。
PostgreSQL 中的众多消息格式用于执行 SQL 命令,我们主要关注的两个是:
简单查询:使用 Q 消息类型执行作为单个字符串发送的单个 SQL 命令,以便直接执行如 SELECT * FROM users 这样的查询。
扩展查询:使用一个包含解析、绑定、执行和其它消息类型在内的多步骤流程来支持复杂交互,包括参数化查询和 prepared statement。
prepared statement 通过在准备期间解析和分析语句一次来优化性能。执行时,它使用特定的参数值,减少重复解析并提高效率。
在后端开发期间,这些消息格式通常由编程语言库抽象出来。然而,理解它们对于我们的工作至关重要,因为我们使用 eBPF 直接从内核中从头开始解析它们。
Kubernetes 中的 Anteon 和 PostgreSQL
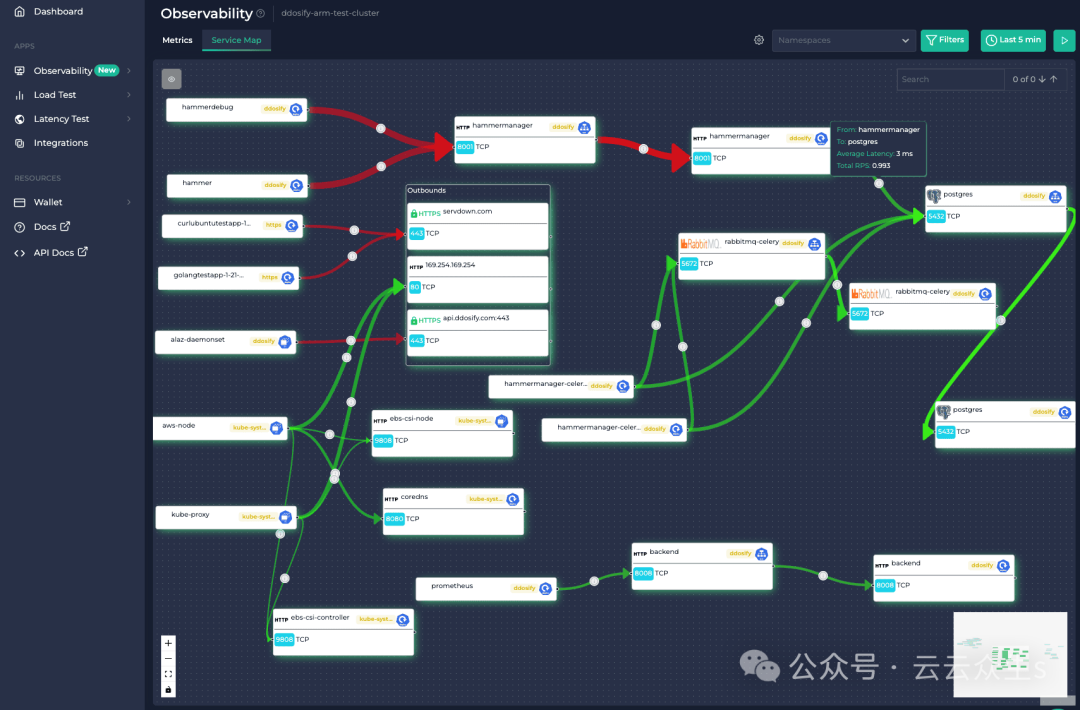
在我们的 Web 界面中,对于每个 PostgreSQL 数据库 部署,你可以轻松查看客户端查询、按查询类型分类以及每个请求的状态,如下面的图片所示。
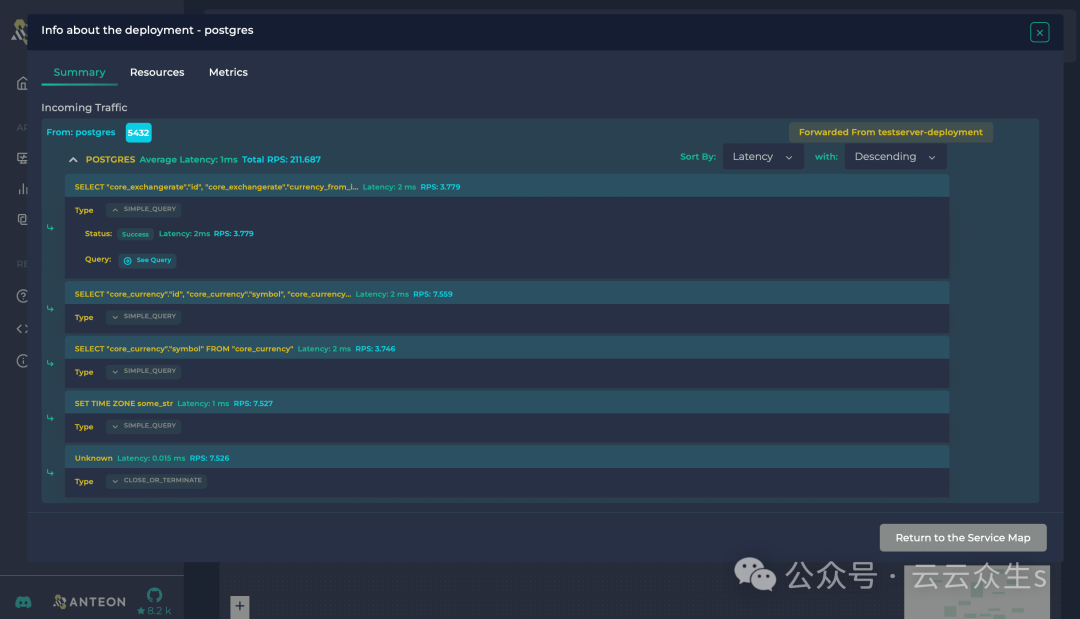
如果你仔细观察图片,你还会注意到请求延迟和 RPS 等见解。我们将在另一篇文章中讨论这些参数,因为它们主要与 PostgreSQL 构建在其上的底层 TCP 协议相关。现在,让我们重点介绍我们如何实现这种全面的可见性。
使用 Alaz eBPF 代理实现 PostgreSQL 可观察性
在后台,我们的平台利用了一个名为Alaz的 eBPF 代理,它在你的 Kubernetes 集群上作为 DaemonSet 运行。该代理的主要任务是在每个 Kubernetes 节点上加载和附加 eBPF 程序,然后侦听通过 eBPF 映射传输到用户空间的内核事件。虽然我们很想在这里详细探讨 eBPF,但它值得专门写一篇帖子,甚至是一系列帖子。如果你还不熟悉它,网上有许多在线资源可以为你提供快速入门。
以下代码片段引用了我们代理的特定部分。完整的源代码可在我们的 GitHub 存储库中获得。
eBPF 挂钩点
在 eBPF 程序的上下文中,内核内附加点通常称为挂钩或挂钩点。每个挂钩点主要在可以访问哪些内核数据类型和变量方面有所不同。对于 PostgreSQL,在客户端和服务器之间创建套接字并建立连接后,内核将调用套接字协议处理程序的 write 函数以向服务器发送数据。内核将调用套接字协议处理程序的 read 函数以从远程对等方接收数据。因此,目标是附加到这些 syscall 挂钩点:
tracepoint/syscalls/sys_enter_write:在写系统调用上触发,用于捕获发送的数据。提供对写系统调用的输入参数的访问。
tracepoint/syscalls/sys_enter_read:在读系统调用的进入上触发,用于捕获接收的数据。提供对读系统调用的输入参数的访问。
tracepoint/syscalls/sys_exit_read:在读系统调用的退出上触发。提供对读系统调用的返回值的访问。
这些挂钩点为我们提供了对连接文件描述符、套接字地址和 PostgreSQL 查询(包括其类型、参数)的访问。
PostgreSQL (L7) 协议解析
PostgreSQL 协议是一个 L7 协议,这意味着我们的程序应该能够从内核内部获取并解析其应用程序数据。类似的概念适用于 HTTP、HTTP/2、AMQP、RESP 和其他协议。
注意:为了简单起见,我们只关注描述未加密流量的代码流,为即将发布的关于观察加密流量的文章奠定一些基础。
在write
系统调用期间,我们的跟踪点程序解析发送数据(buf
变量),并使用以下函数检查它是否与任何 PostgreSQL 消息格式匹配:
static __always_inlineint parse_client_postgres_data(char *buf, int buf_size, __u8 *request_type) {// Return immeadiately if buffer is emptyif (buf_size < 1) {return 0;}// Read the first byte from the buffer// This should be the identifier of the PostgresQL messagechar identifier;if (bpf_probe_read(&identifier, sizeof(identifier), (void *)((char *)buf)) < 0) {return 0;}// The next four bytes of the buffer should specify the length of the message__u32 len;if (bpf_probe_read(&len, sizeof(len), (void *)((char *)buf + 1)) < 0) {return 0;}// Check if the identifier represents connection termination ("X") and// the length is 4 bytes (as per protocol docs)if (identifier == POSTGRES_MESSAGE_TERMINATE && bpf_htonl(len) == 4) {bpf_printk("Client will send Terminate message\n");*request_type = identifier;return 1;}// Check if the identifier represents Simple Query Protocol ("Q")if (identifier == POSTGRES_MESSAGE_SIMPLE_QUERY) {*request_type = identifier;bpf_printk("Client will send a Simple Query message\n");return 1;}// Check if the identifier represents and Extended Query Protocol, which is either:// - P/D/S (Parse/Describe/Sync) creating a prepared statement// - B/E/S (Bind/Execute/Sync) executing a prepared statementif (identifier == POSTGRES_MESSAGE_PARSE || identifier == POSTGRES_MESSAGE_BIND) {// Read last 5 bytes of the buffer (Sync message)char sync[5];if (bpf_probe_read(&sync, sizeof(sync), (void *)((char *)buf + (buf_size - 5))) < 0) {return 0;}// Extended query protocol messages end with a Sync ("S") message.// Sync message is a 5 byte message with the first byte being "S" and// the rest indicating the length of the message, including self (4 bytes in this case - so no message body)if (sync[0] == 'S' && sync[1] == 0 && sync[2] == 0 && sync[3] == 0 && sync[4] == 4) {bpf_printk("Client will send an Extended Query\n");*request_type = identifier;return 1;}}return 0;}复制
我们在服务器上read
系统调用的入口处利用一个跟踪点来捕获其输入参数,例如文件描述符和查询负载。然后将此数据转发到read
系统调用出口处的跟踪点以进行协议分类。
最后但并非最不重要的一点是,服务器上read
系统调用出口处的跟踪点执行消息标识符检查,具体来说,使用以下方法检查消息的第一个字节:
static __always_inline__u32 parse_postgres_server_resp(char *buf, int buf_size) {// Return immeadiately if buffer is emptyif (buf_size < 1) {return 0;}// Read the first byte from the buffer// This should be the identifier of the PostgresQL messagechar identifier;if (bpf_probe_read(&identifier, sizeof(identifier), (void *)((char *)buf)) < 0) {return 0;}// Checks if the message identifies an error.if (identifier == 'E') {return ERROR_RESPONSE;}// Identify SQL commands (tag field, e.g. SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, etc.)if (identifier == 't' || identifier == 'T' || identifier == 'D' || identifier == 'C') {return COMMAND_COMPLETE;}return 0;}复制
一旦我们对消息格式进行分类,我们就会通过 perf 缓冲区将其数据发送到用户空间应用程序,然后在我们的 Web 界面上呈现它。
Perf 缓冲区 (Perfbuf)是一个按 CPU 组织的循环缓冲区集合,允许在内核和用户空间之间高效地交换数据。
性能评估
总之,我们进行了基本的性能测试来评估我们的 eBPF 程序对主机服务器的影响,特别关注在拦截和解析 PostgreSQL 协议流量时的延迟和 CPU 负载。测试涉及测量 10,000 个请求的平均延迟。
首先,我们使用以下命令在本地 部署PostgreSQL 容器:
docker run --name my-postgres-container -e POSTGRES_PASSWORD=mysecretpassword -d -p 5432:5432 --memory=4g --cpus=4 -v ./postgresql.conf:/etc/postgresql/postgresql.conf -e POSTGRES_CONFIG_FILE=/etc/postgresql/postgresql.conf postgres复制
为了优化性能并防止节流,我们为容器分配了 4 个 CPU 和 4GB 内存。此外,我们使用一些通常推荐的内存设置对其进行了配置:
# PostgreSQL configuration file - postgresql.conf# Memory settingsshared_buffers = 1GB # recommended: 25% of total memoryeffective_cache_size = 3GB # recommended: 75% of total memorywork_mem = 64MB # recommended: 2-4MB per CPU coremaintenance_work_mem = 512MB # recommended: 10% of total memory复制
复制
然后在有和没有 eBPF 程序监视 PostgreSQL 流量的情况下评估设置,以观察影响:

我们的结果表明,eBPF 程序增加了大约0.03 毫秒(平均值)的恒定 eBPF 开销。此外,每个挂钩引入的平均 CPU 负载如下:
0.4%用于
tracepoint/syscalls/sys_enter_read1.41%用于
tracepoint/syscalls/sys_exit_read0.8%用于
tracepoint/syscalls/sys_enter_write
你可以在下面引用的资料库的/perf目录中找到负载测试程序。
老实说,有相当多的代码围绕着所述的功能,主要集中于提取缓冲区并执行其他与协议有关的检查。现在,完整展示 Alaz 可能会有些复杂。但是,为了向您提供一个实际的示例,我们准备了一段重点演示代码,它仅包含与 PostgreSQL 相关的功能。您可以访问以下链接访问它。
结论:使用 eBPF 在 Kubernetes 上监视 PostgreSQL 数据库
总之,我们的基于 eBPF 的监视解决方案已集成到Anteon 平台中,为 部署在 Kubernetes 上的 PostgreSQL 数据库提供了全面的可观察性。通过利用 eBPF,我们有效地捕获和分析客户端查询和协议消息格式,而无需修改应用程序代码。此功能对于识别性能瓶颈、确保最佳资源利用以及增强整体应用程序安全性至关重要。敬请期待即将发表的文章,在这些文章中,我们将深入探讨监视加密流量并探索我们平台的其他功能。


