




导读
在mysql 8.0版本,系统表的存储引擎由myisam改为了innodb, @@datadir/mysql目录下一堆的数据文件通通放到@@datadir/mysql.ibd文件中了. 但很多表在非debug模式下是无法查看里面的数据的. 这TM就很恼火. (刚学完innodb的磁盘结构, 我能受这气?). 所以我们现在来解析下mysql.ibd文件. (也顺便为 ibd2sql 2.0 做准备)

分析
我们先登录数据库, 随便查看张mysql库下面的表的DDL
show create table mysql.engine_cost;
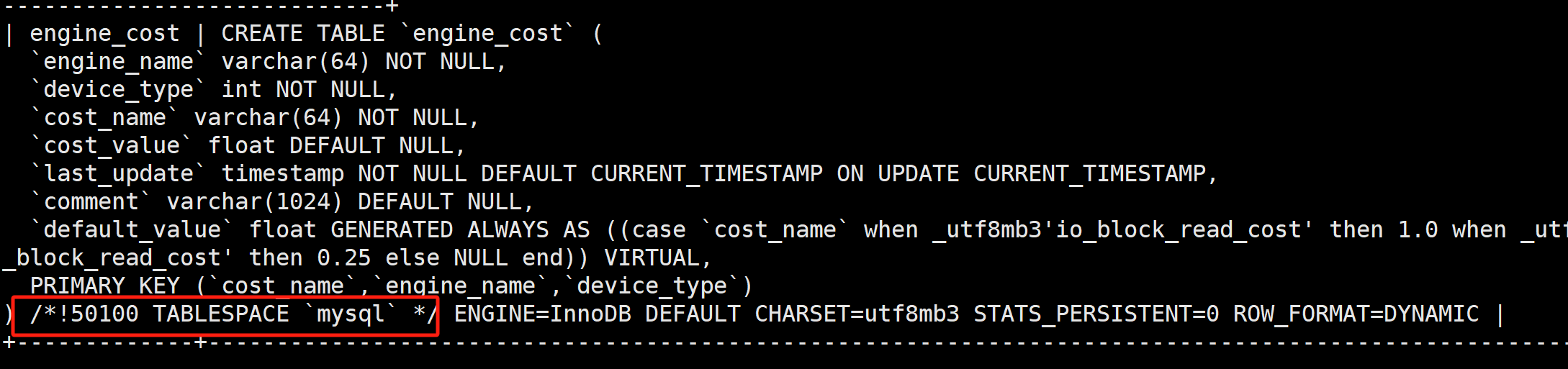
发现使用的表空间都是mysql. 那我们再看下mysql表空间的类型
select * from information_schema.INNODB_TABLESPACES where NAME='mysql'\G
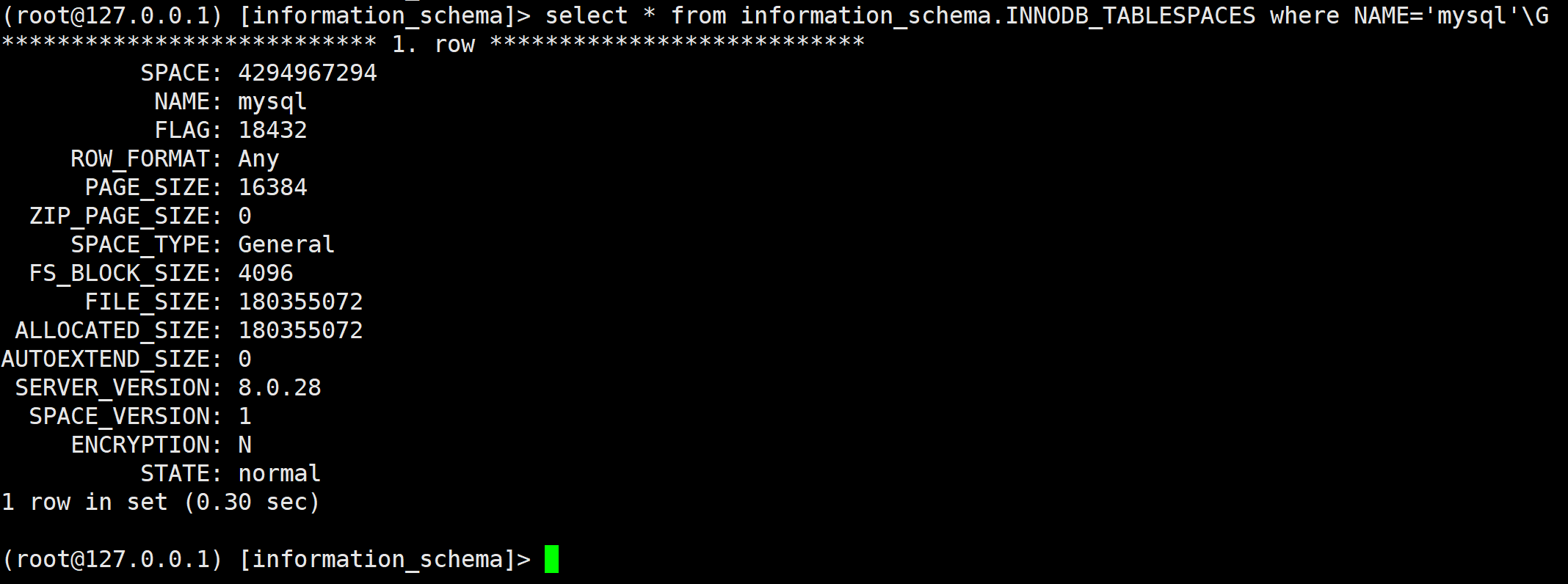
发现是general的.(肯定的啊). 我们查看该表空间的路径:
general tablespace 可以存储多个表
select * from information_schema.files where TABLESPACE_NAME='mysql'\G

发现就是@@datadir/mysql.ibd. 也就是我们这次要解析的文件.
mysql的相对路径都是基于@@datadir的
我们之前解析数据文件的时候都是基于File-Per-Table Tablespaces的, 即一个表空间对应一张表. 上来就是有难度的.
SDI PAGE
既然一个表空间能存储多张表, 那么sdi信息就会记录多张表的信息, 我们之前解析inode的时候, 发现里面第一对segment就是sdi page, 也就是说sdi page 也应该和普通索引一样的格式. 再加上解析sdi的时候也有trx,undoptr之类的信息. 所以sdi page也是数据行, 那么一张表1行就可以存储多张表的元数据信息了.啊,我真是个小天才
FIL_PAGE_INDEX = 17855, FIL_PAGE_SDI = 17853 号比较接近, 所以格式也一样 p_q
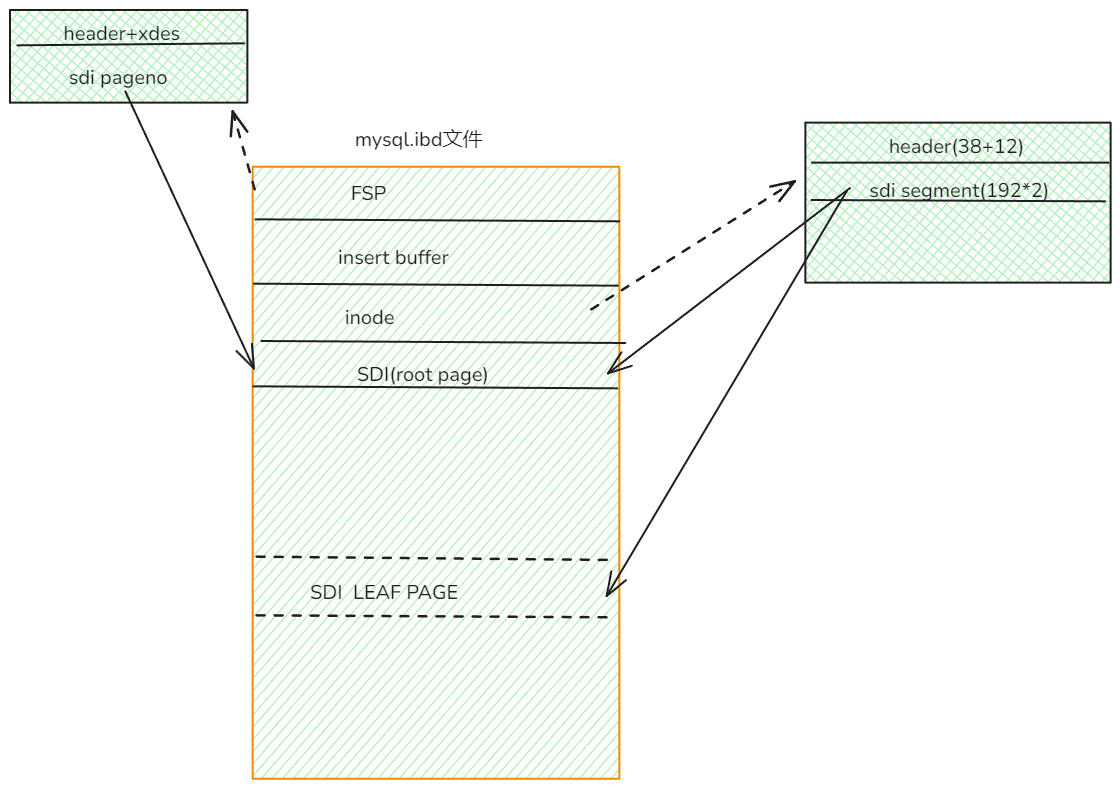
既然知道了格式, 那我们就可以通过如下代码来解析了(先不转为DDL), 为了加强记忆, 我们再来回顾下sdi的结构吧.
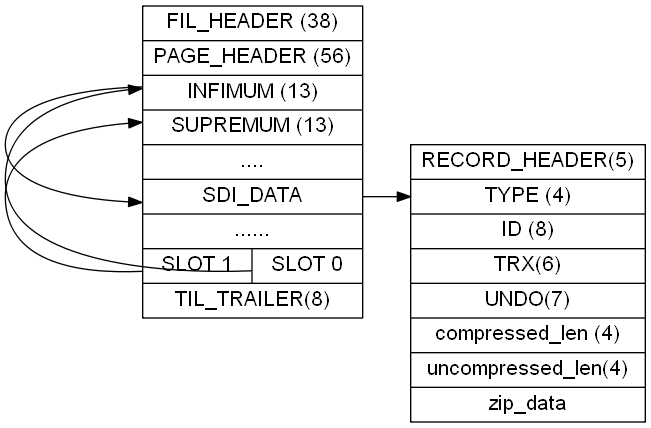
整体格式是这样的, 但可能存在多行数据, 并且(刚处理事情去了,忘记要说啥了-_-).
如果是 non-leaf page的话, 就没得type和数据之类的, 只有PK(id 8字节),trx(6),undoptr(7) 这21字节, 再加上4字节的PAGENO, 感兴趣的字自己去验证, 这里就不验证了.
由于都是数据行(btr+), 所以也是双向链表, 这就涉及到file_header的格式了.
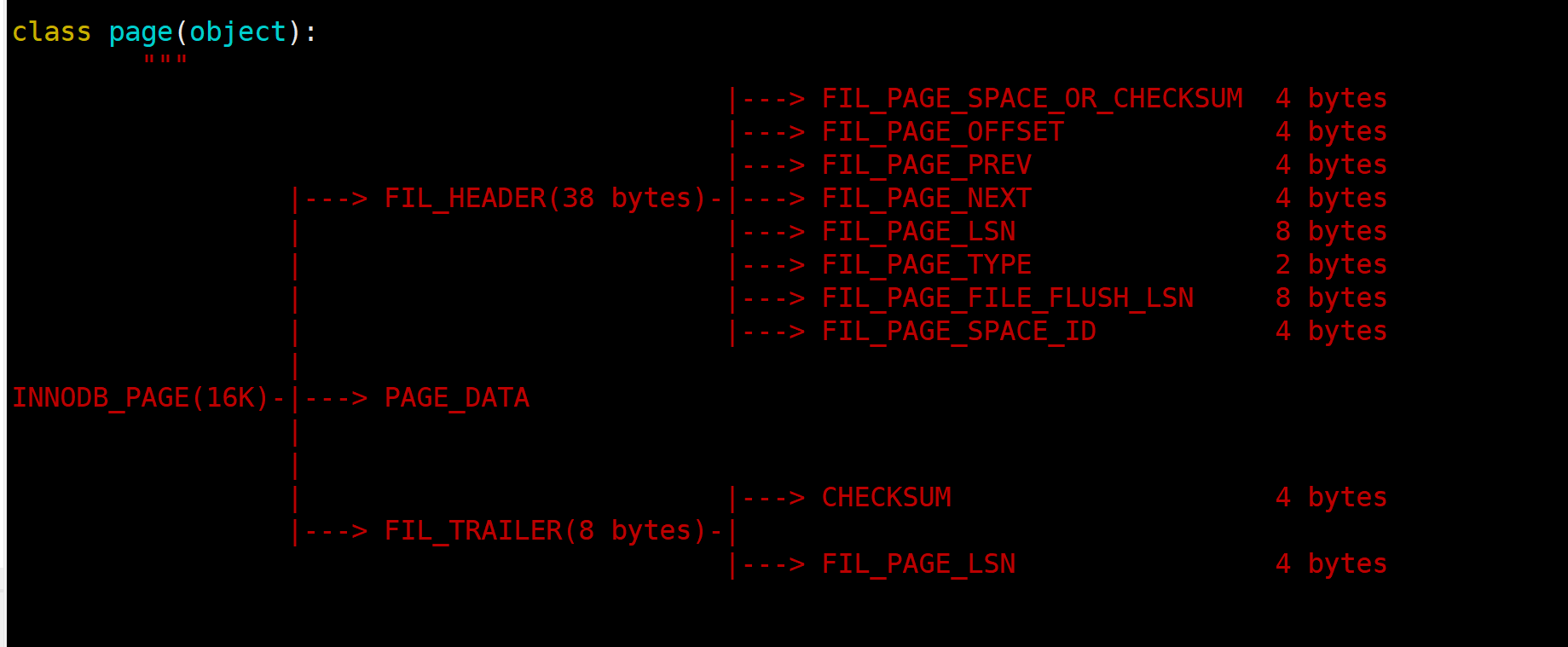
12–16就是下1页的PAGENO. (checksum, space_id,lsn 是不是看着很眼熟, 前两篇解析的时候有用到). 结构介绍完了, 那就开整.
import struct,json,zlib
PAGE_NEW_INFIMUM = 99
filename = '/data/mysql_3314/mysqldata/mysql.ibd'
f = open(filename,'rb')
data = f.read(16384)
# fsp的记录对应general tablespace是没得用的, 但出于礼貌, 我们还是给它留2行代码
sdi_version,sdi_pageno = struct.unpack('>II',data[150+40*256:150+40*256+8])
# inode
f.seek(16384*2,0)
data = f.read(16384)
sdi_segment = data[50:50+192*2]
sdi_leaf_pageno = struct.unpack('>L',sdi_segment[192:][64:68])[0]
# SDI
dd = {}
while sdi_leaf_pageno < 4294967295:
_ = f.seek(16384*sdi_leaf_pageno,0)
data = f.read(16384)
sdi_leaf_pageno = struct.unpack('>L',data[12:16])[0]
offset = PAGE_NEW_INFIMUM + struct.unpack('>H',data[97:99])[0]
while True:
offset += struct.unpack('>h',data[offset-2:offset])[0] # 注意是有符号的. 但不涉及到数据修改, 其实也无所谓
if offset > 16384 or offset == 112:
break
sdi_type,id = struct.unpack('>LQ',data[offset:offset+12])
trx1,trx2,undo1,undo2,undo3 = struct.unpack('>LHLHB',data[offset+12:offset+25])
trx = (trx1<<16) + trx2
undo = (undo1<<24) + (undo2<<8) + undo3
dunzip_len,dzip_len = struct.unpack('>LL',data[offset+25:offset+33])
unzbdata = zlib.decompress(data[offset+33:offset+33+dzip_len])
dic_info = json.loads(unzbdata.decode())
dd[dic_info['dd_object']['name']] = dic_info
print('TOTAL TABLES:',len(dd))
for name in dd:
print(name)
通过这段代码我们就能得到一个sdi dict. 有60张表
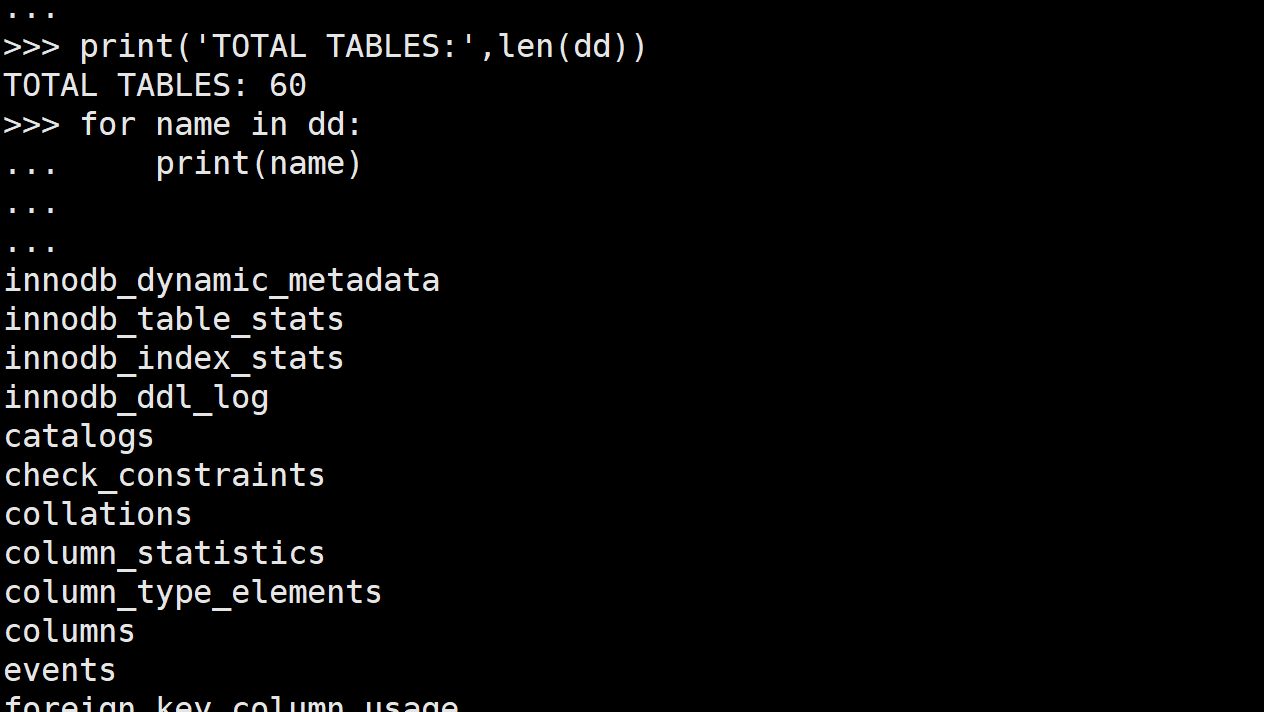
但是我们登录数据库里面查看,却只有37张
(root@127.0.0.1) [mysql]> select count(*) from information_schema.tables where table_schema='mysql';
+----------+
| count(*) |
+----------+
| 37 |
+----------+
1 row in set (0.00 sec)
那是因为像catalogs之类的被隐藏了. 要开debug模式才能查询, 而我们本篇的目的就是直接查询.

解析mysql.ibd文件
既然得到了sdi信息, 那么就可以开始解析那60张表的数据了. 由于存在json之类的数据格式, 所以我们就使用ibd2sql来做吧 (稍微改改就行, 把那几个类的使用方法重写一下)
数据行的结构和上面sdi的结构一致, 就不再介绍了
from ibd2sql.innodb_page_sdi import *
from ibd2sql import __version__
from ibd2sql.ibd2sql import ibd2sql
class sdi2(sdi):
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
self.dd = kwargs['dd']
self.table = TABLE()
self._init_table()
self.table._set_name()
def get_dict(self):
return self.dd
class ibd2sql2(ibd2sql):
def init(self,):
self.f = open(self.FILENAME,'rb')
self.PAGE_ID = 2
self.first_no_leaf_page = 82
self.first_leaf_page = 0
for name in dd:
aa = sdi2(b'\x00'*16384,dd=dd[name])
ddcw = ibd2sql2()
ddcw.FILENAME = filename
ddcw.IS_PARTITION = True
ddcw.table = aa.table
ddcw.replace_schema('ddcw') # 替换schema,方便导入数据库
ddcw._init_table_name()
ddcw.init()
ddcw.first_no_leaf_page = int(dict([ y.split('=') for y in dd[name]['dd_object']['indexes'][0]['se_private_data'].split(';')[:-1]])['root'])
ddcw.init_first_leaf_page()
print(ddcw.get_ddl()) # 打印DDL
print(ddcw.get_sql()) # 打印数据
让我们来瞧瞧
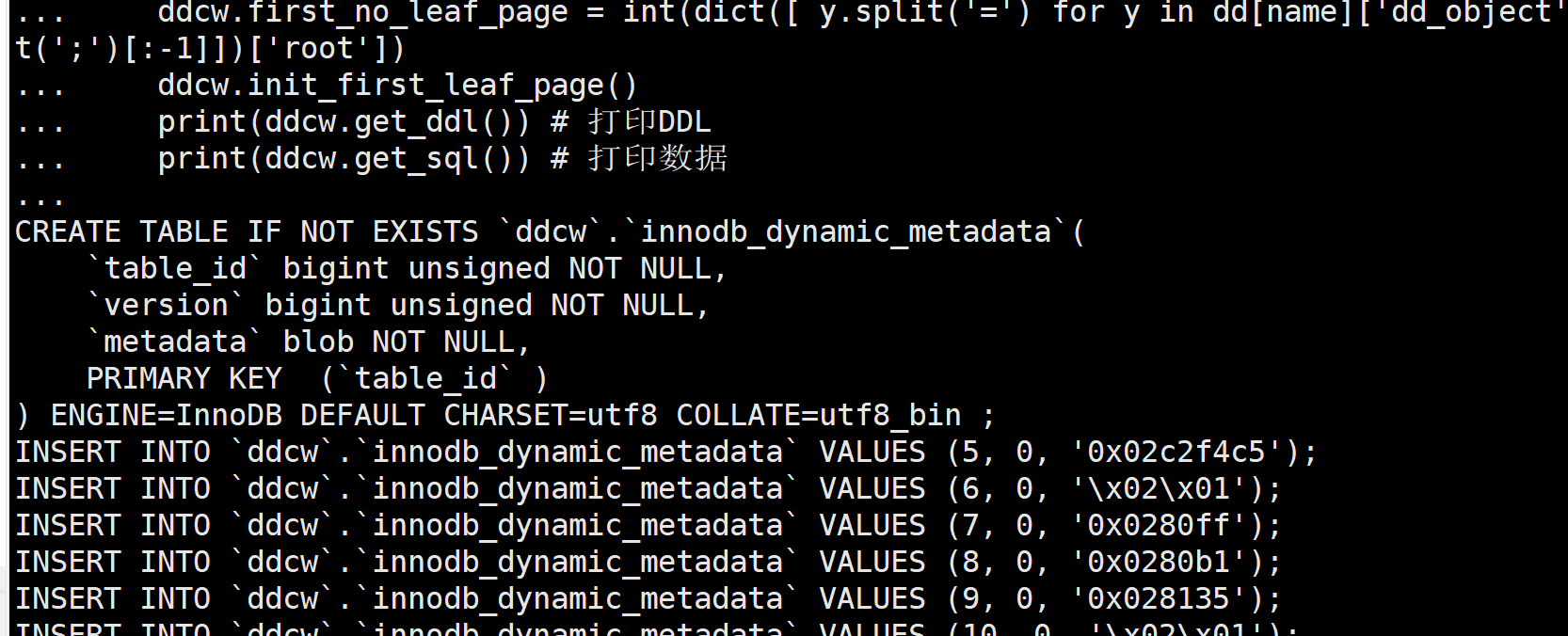
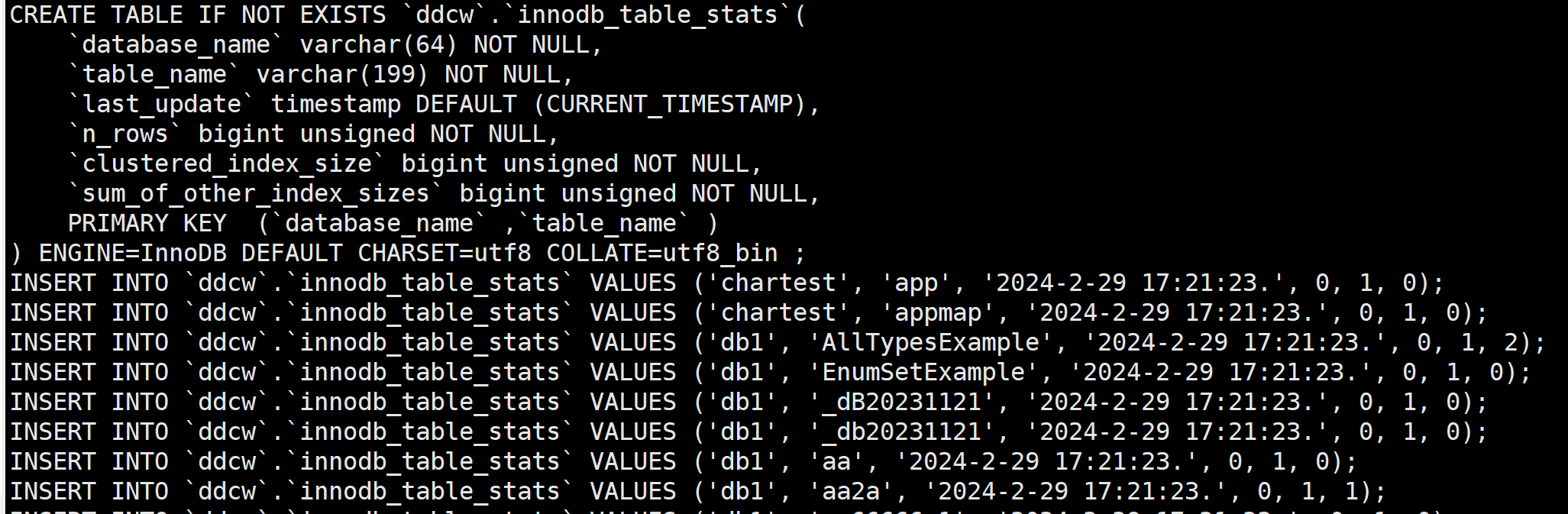
感觉挂怪的, 但好像又没得问题…
就不做更深入的测试了.
总结
-
mysql 8.0的系统表使用innodb存储引擎, 存放在mysql.ibd文件中, 是general tablespace类型, 即多个系统表都存放在一个表空间里面.
-
正常情况需要debug才能看到的系统信息, 现在可以通过解析mysql.ibd文件来获取啦.
-
实际使用的时候, 建议cp到tmp目录之类的再解析.(虽然只要读权限就行, 但稳一手)
-
系统表的信息比较敏感,不要随便传(里面有mysql.user表的啊)
参考
https://github.com/ddcw/ibd2sql
https://dev.mysql.com/doc/refman/8.0/en/general-tablespaces.html
https://github.com/mysql/mysql-server/blob/trunk/utilities/ibd2sdi.cc
附源码
要结合ibd2sql来使用.
例子:
wget https://github.com/ddcw/ibd2sql/archive/refs/heads/main.zip unzip main.zip cd ibd2sql-main/ vim get_mysql_ibd.py # 粘贴下面的那段代码 python get_mysql_ibd.py /data/mysql_3314/mysqldata/mysql.ibd > /tmp/t20240918.sql
源码:
import struct,json,zlib
from ibd2sql.innodb_page_sdi import *
from ibd2sql import __version__
from ibd2sql.ibd2sql import ibd2sql
import sys,os
PAGE_NEW_INFIMUM = 99
if len(sys.argv)!=2:
print('USAGE: python3 get_mysql_ibd.py /data/mysql.ibd')
sys.exit(2)
filename = sys.argv[1]
if not os.path.exists(filename):
print(filename,' not exists')
sys.exit(1)
f = open(filename,'rb')
data = f.read(16384)
# fsp的记录对应general tablespace是没得用的, 但出于礼貌, 我们还是给它留2行代码
sdi_version,sdi_pageno = struct.unpack('>II',data[150+40*256:150+40*256+8])
# inode
f.seek(16384*2,0)
data = f.read(16384)
sdi_segment = data[50:50+192*2]
sdi_leaf_pageno = struct.unpack('>L',sdi_segment[192:][64:68])[0]
# SDI
dd = {}
while sdi_leaf_pageno < 4294967295:
_ = f.seek(16384*sdi_leaf_pageno,0)
data = f.read(16384)
sdi_leaf_pageno = struct.unpack('>L',data[12:16])[0]
offset = PAGE_NEW_INFIMUM + struct.unpack('>H',data[97:99])[0]
while True:
offset += struct.unpack('>h',data[offset-2:offset])[0] # 注意是有符号的. 但不涉及到数据修改, 其实也无所谓
if offset > 16384 or offset == 112:
break
sdi_type,id = struct.unpack('>LQ',data[offset:offset+12])
trx1,trx2,undo1,undo2,undo3 = struct.unpack('>LHLHB',data[offset+12:offset+25])
trx = (trx1<<16) + trx2
undo = (undo1<<24) + (undo2<<8) + undo3
dunzip_len,dzip_len = struct.unpack('>LL',data[offset+25:offset+33])
unzbdata = zlib.decompress(data[offset+33:offset+33+dzip_len])
dic_info = json.loads(unzbdata.decode())
dd[dic_info['dd_object']['name']] = dic_info
f.close()
class sdi2(sdi):
def __init__(self,*args,**kwargs):
super().__init__(*args,**kwargs)
self.dd = kwargs['dd']
self.table = TABLE()
self._init_table()
self.table._set_name()
def get_dict(self):
return self.dd
class ibd2sql2(ibd2sql):
def init(self,):
self.f = open(self.FILENAME,'rb')
self.PAGE_ID = 2
self.first_no_leaf_page = 82
self.first_leaf_page = 0
for name in dd:
try:
aa = sdi2(b'\x00'*16384,dd=dd[name]) # 有空了再改, 先临时用着.... # 其实就是最后一个对象(mysql, 不是表, 即没得mysql.mysql)
except:
continue
ddcw = ibd2sql2()
ddcw.FILENAME = filename
ddcw.IS_PARTITION = True
ddcw.table = aa.table
ddcw.replace_schema('ddcw') # 替换schema,方便导入数据库
ddcw._init_table_name()
ddcw.init()
ddcw.first_no_leaf_page = int(dict([ y.split('=') for y in dd[name]['dd_object']['indexes'][0]['se_private_data'].split(';')[:-1]])['root'])
try:
ddcw.init_first_leaf_page()
print(ddcw.get_ddl()) # 打印DDL
sql = ddcw.get_sql()
if sql is not None:
print(sql) # 打印数据
except:
pass
