




导读
当我们磁盘空间比较紧张 或者 数据比较’冷’的时候, 就会想到压缩数据来实现空间的释放. 压缩数据可以在业务层实现, 也可以在数据库层实现
| 优点 | 缺点 | |
|---|---|---|
| 业务层 | 减少数据库服务器压力, 减少网络带宽 | 对开发要求高 |
| 数据库层 | 简单,磁盘压力小 | 压力来到了数据库服务器的CPU |
如果是业务初期的话, 在数据库层面直接修改表的属性 加个压缩即可(需要重建表,如果数据量大的话, 会非常慢). 后期的话, 就不太好动了(业务层或者开发层都不好动).
业务层实现:直接调用zlib之类的压缩包就能实现压缩.
数据库层实现: alter table tablename COMPRESSION='zlib' 即可.
mysql支持zlib和lz4两种, 取消的话,设置为None即可.
那么数据库层面具体是怎么实现的呢?

原理分析
我们先来创建一张压缩表和一张非压缩的表.
create table t20240920_compress(id int primary key,name varchar(200)) COMPRESSION="zlib";
insert into t20240920_compress values(1,'ddcw');
insert into t20240920_compress values(2,'ddcw');
create table t20240920_nocompress(id int primary key,name varchar(200));
insert into t20240920_nocompress values(1,'ddcw');
insert into t20240920_nocompress values(2,'ddcw');
既然使用了压缩, 那么磁盘上的空间应该就会小一点.

纳里,一样大?
不对, ls查看的文件系统记录的大小值, 而不是真实的块占用. 所以得使用du来查看才对

果然空间要小很多了. 但mysql的数据存储都是以PAGE为单位存储的啊. 16KB的PAGE压缩之后该是多大呢?
欸, 这时候我们就要看官网对于压缩页的描述了.
InnoDB supports page-level compression for tables that reside in file-per-table tablespaces. This feature is referred to as Transparent Page Compression. Page compression is enabled by specifying the COMPRESSION attribute with CREATE TABLE or ALTER TABLE. Supported compression algorithms include Zlib and LZ4.
只支持file-per-table的表, 可以通过create table 或者alter table的方式来设置压缩属性. 支持zlib和lz4算法.
实现原理如下:
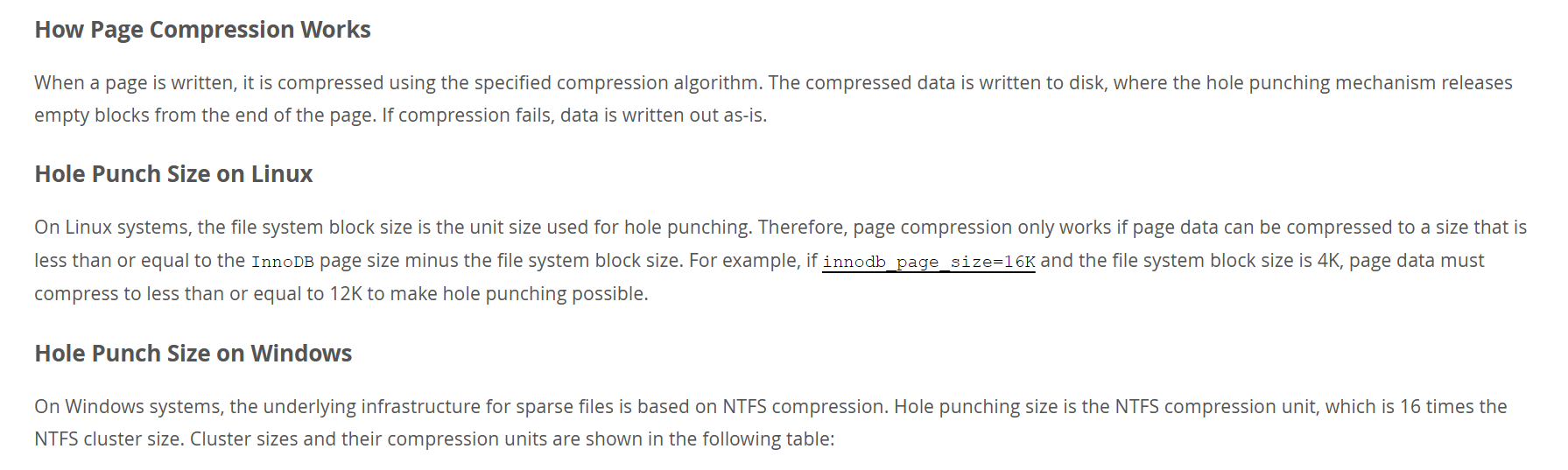
我们只看linux的, 大意是根据OS的hole punching(打孔)来实现的. 也就是我存储16KB的内容, 但是我告诉文件系统,你可以不要后面的4KB(必须是OS_PAGE_SIZE的整数倍), 这样我们就实现了空间的重复利用? 也就是对OS有一定的要求.
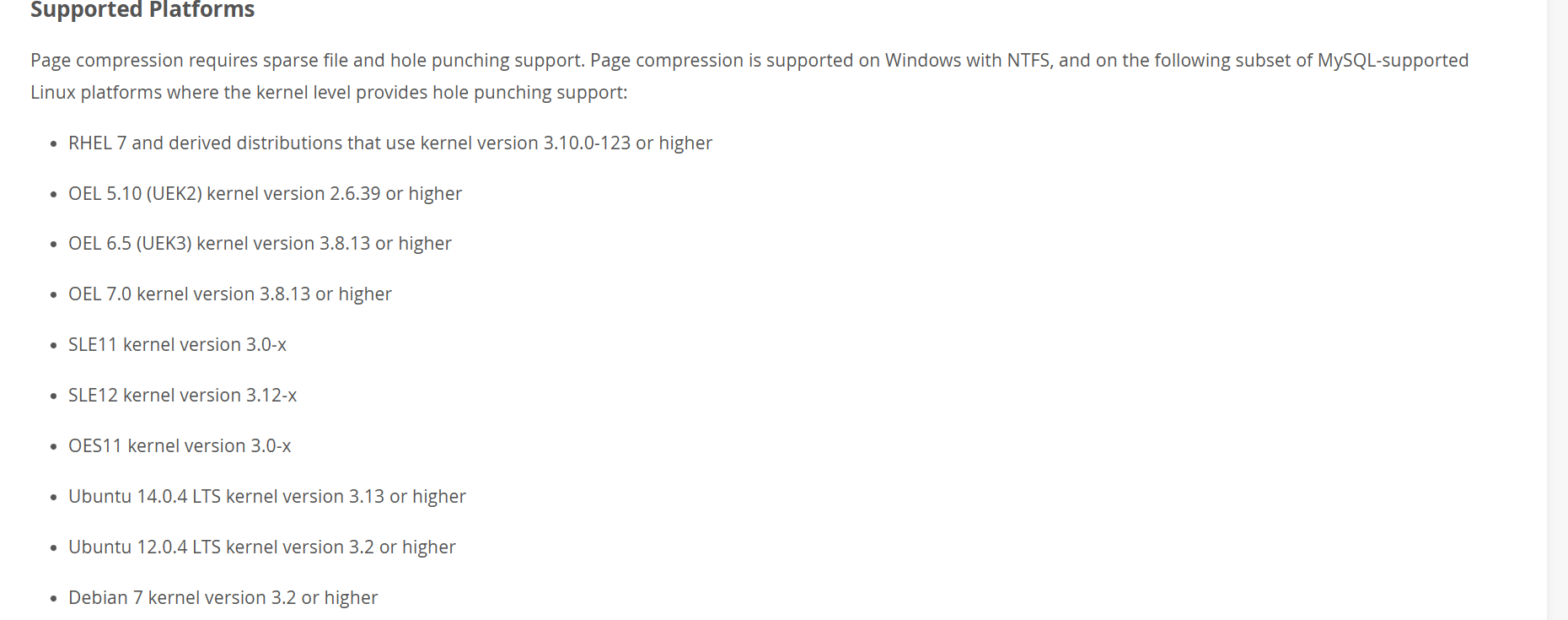
我们来个示意图表示吧.
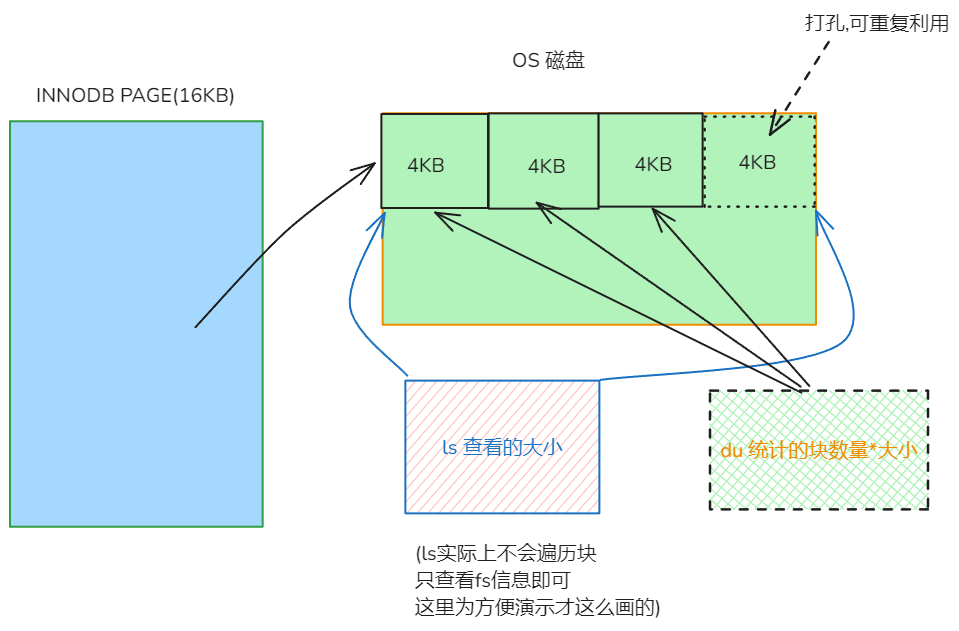
可以说是du比ls慢的原因
du和ls查询值不一致, 是不是优点眼熟, 之前也遇到过的, 就是https://www.modb.pro/db/1796439194323193856. 那是文件系统预分配导致的. 也就是会预分配一部分空间给该文件, 但是不会修改文件的实际大小(也就导致了du和ls看到的不一样), 和我们这里的打孔正好相反. 这两种其实都是fallocate来实现的. 扯远了.
mysql的压缩实现
我们再来看看mysql对于压缩的实现吧. mysql的实现就更简单了, 直接就是把除了FIL_HEADER的全部压缩即可. 嗯, 就没了(ps:之前以为好复杂呢,就没管这个压缩页.) 当然对PAGE有一定要求的, 比如如果压缩之后的大小占用的OS块和之前一样, 那就没必要压缩了, 已经压缩了的页也没必要压缩了. 直接看看源码的逻辑吧
/* storage/innobase/os/os0file.cc */
byte *os_file_compress_page(){
ulint page_type = mach_read_from_2(src + FIL_PAGE_TYPE); /*原理的页类型要的,因为后面要修改页的类型为压缩页了*/
//一些不能压缩的情况
ut_ad(!(src_len % block_size));
ut_ad(page_type != FIL_PAGE_COMPRESSED);
ut_ad(page_type != FIL_PAGE_ENCRYPTED);
ut_ad(page_type != FIL_PAGE_COMPRESSED_AND_ENCRYPTED);
if (page_type == FIL_PAGE_RTREE || block_size == ULINT_UNDEFINED ||
compression.m_type == Compression::NONE || src_len < block_size * 2) {
*dst_len = src_len;
return (src);
}
// 起码压缩后,要少占用1块
out_len = src_len - (FIL_PAGE_DATA + block_size);
ut_ad(out_len >= block_size - FIL_PAGE_DATA);
// 压缩
//把头还回去 (看着咋怪吓人的呢)
memmove(dst, src, FIL_PAGE_DATA);
// 设置一些压缩属性, 即把FIL_PAGE_FILE_FLUSH_LSN的8字节给拆分了. (FIL_PAGE_FILE_FLUSH_LSN: 我TM?)
mach_write_to_2(dst + FIL_PAGE_TYPE, FIL_PAGE_COMPRESSED);
mach_write_to_1(dst + FIL_PAGE_VERSION, Compression::FIL_PAGE_VERSION_2);
mach_write_to_1(dst + FIL_PAGE_ALGORITHM_V1, compression.m_type);
mach_write_to_2(dst + FIL_PAGE_ORIGINAL_TYPE_V1, page_type);
mach_write_to_2(dst + FIL_PAGE_ORIGINAL_SIZE_V1, content_len);
mach_write_to_2(dst + FIL_PAGE_COMPRESS_SIZE_V1, len);
// ....
}

看代码还是比较脑阔疼的, 我们整理下吧
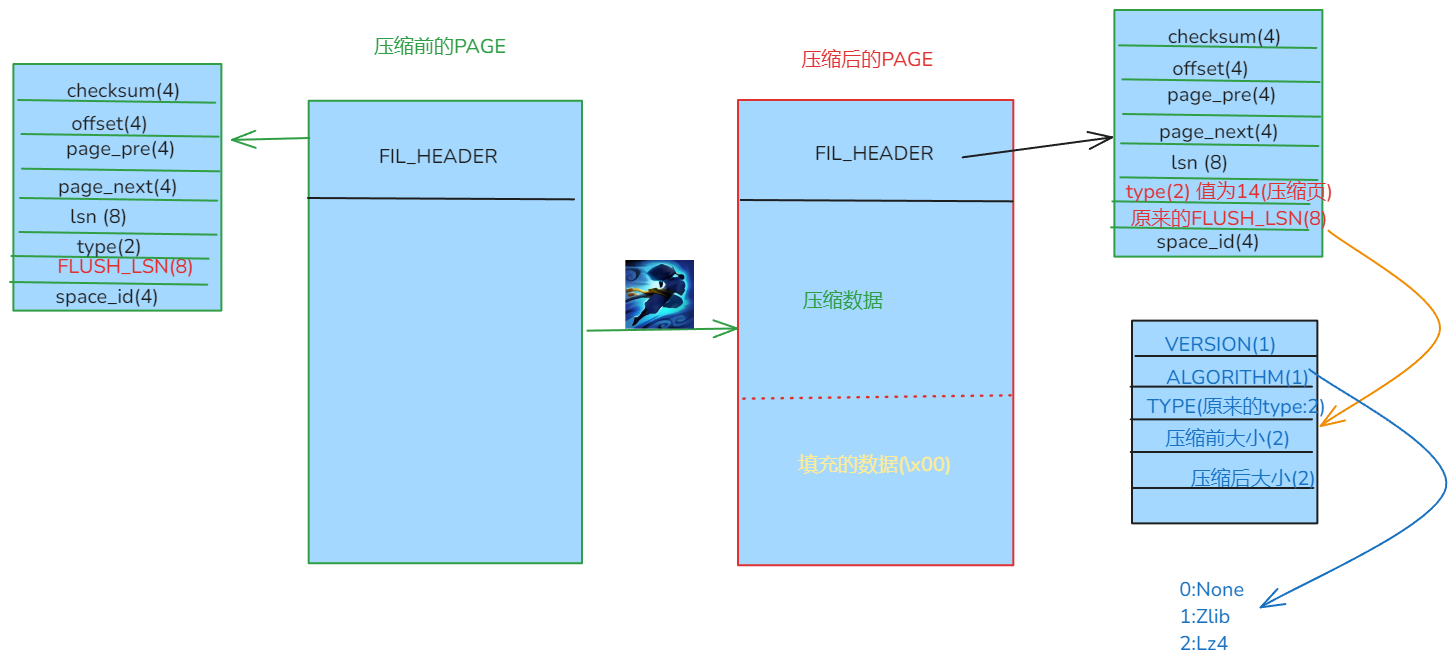
只比原来复杂一丢丢. 填充的数据就是到时候打孔的那部分.

模拟
我们直接使用python来模拟吧. (我这里就不压缩了, 直接使用填充字符)
调的libc来做的, 终究还是调包侠
import os
import ctypes
FALLOC_FL_PUNCH_HOLE = 0x02
FALLOC_FL_KEEP_SIZE = 0x01
libc = ctypes.CDLL('libc.so.6', use_errno=True)
def punch_hole(f, offset, length):
ret = libc.fallocate(f, FALLOC_FL_PUNCH_HOLE | FALLOC_FL_KEEP_SIZE, ctypes.c_long(offset), ctypes.c_long(length))
return ctypes.get_errno() if ret != 0 else 0
f = open('/tmp/t20240920_punch_hole','wb')
data = b'ddcw'*1024*3 # 12KB真实数据
data += b'\x00' * 4*1024 # 4KB填充数据, 模拟压缩
f.write(data)
punch_hole(f.fileno(),12*1024,4*1024)
f.close()
然后我们使用ls和du来验证下
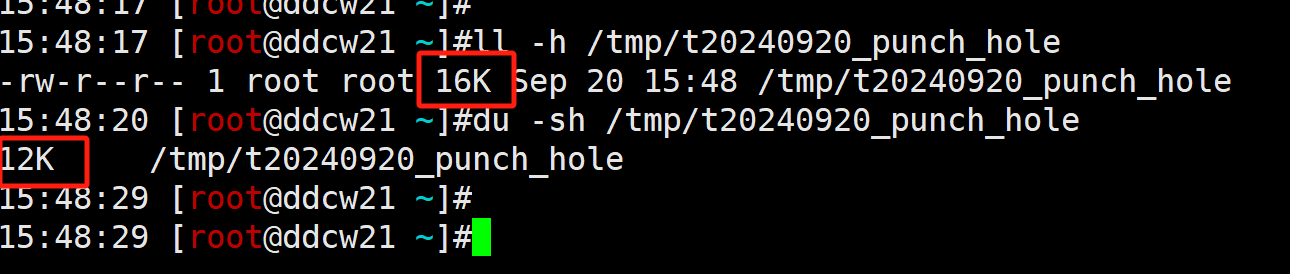
说明数据存储是没得问题的, 那么我们再来读取验证下, 数据是否为我们写入的16KB
f = open('/tmp/t20240920_punch_hole','rb')
data = f.read()
print(len(data))
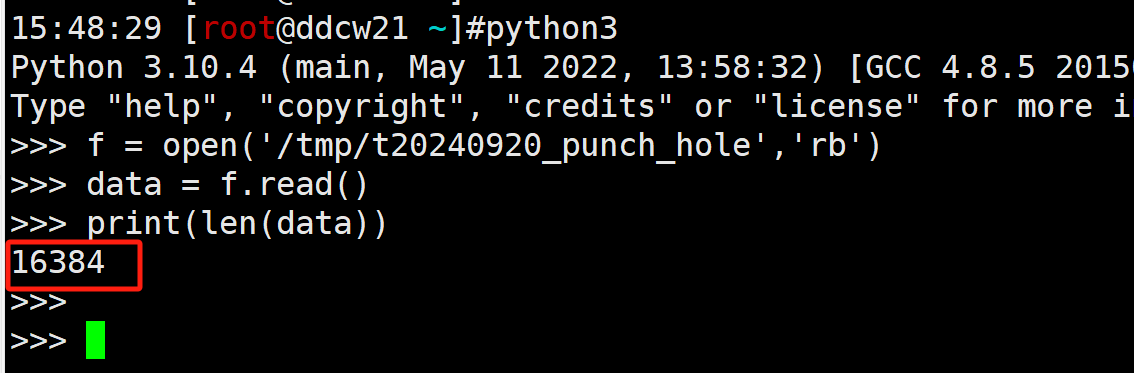
数据确实是16KB, 符合我们的预期.
使用ibd2sql解析压缩表
既然我们知道了压缩的原理, 那我们就稍微改改ibd2sql的源码就能实现压缩表的解析了.
我这里偷个懒, 就不管lz4的死活了, 通通当作zlib来处理
wget https://github.com/ddcw/ibd2sql/archive/refs/heads/main.zip
unzip main.zip
cd ibd2sql-main
vim ibd2sql/ibd2sql.py
# 在开头添加 import zlib
# 然后重写ibd2sql.read()函数
def read(self):
"""
RETURN PAGE RAW DATA
"""
self.debug(f"ibd2sql.read PAGE: {self.PAGE_ID} ")
self.f.seek(self.PAGESIZE*self.PAGE_ID,0)
#self.PAGE_ID += 1
data = self.f.read(self.PAGESIZE)
if data[24:26] == b'\x00\x0e': # 压缩页, 先解压
FIL_PAGE_VERSION,FIL_PAGE_ALGORITHM_V1,FIL_PAGE_ORIGINAL_TYPE_V1,FIL_PAGE_ORIGINAL_SIZE_V1,FIL_PAGE_COMPRESS_SIZE_V1 = struct.unpack('>BBHHH',data[26:34])
data = data[:24] + struct.pack('>H',FIL_PAGE_ORIGINAL_TYPE_V1) + b'\x00'*8 + data[34:38] + zlib.decompress(data[38:38+FIL_PAGE_COMPRESS_SIZE_V1])
return data
然后我们来验证下呢

数据是没毛病的. (但作者DDL里面没有考虑compress属性, 当然我们也懒得改了.)
总结
- mysql的表压缩功能是通过OS的打孔来实现的. 且fil_header这类基础信息是不能压缩的.
- 日常使用还是不太建议使用数据库层的压缩, 主要是影响性能. 现在存储价格已经很便宜了.
- 每页(除了第一页)除了fil_header外均会做压缩, 包括结尾的fil_trailer
参考:
https://dev.mysql.com/blog-archive/innodb-transparent-page-compression/
https://dev.mysql.com/blog-archive/innodb-transparent-pageio-compression/
https://dev.mysql.com/doc/refman/8.4/en/innodb-page-compression.html
https://github.com/mysql/mysql-server/tree/trunk/storage/innobase
https://github.com/ddcw/ibd2sql
https://www.man7.org/linux/man-pages/man2/fallocate.2.html
