结论
01
MySQL8.0以上版本:
无论有无索引,在语义相同的情况下,DISTINCT 和 GROUP BY性能基本相同;
02
MySQL5.7及以下版本:
有索引的情况下,DISTINCT 和 GROUP BY性能基本相同;
无索引情况下,DISTINCT 效率高于 GROUP BY。原因是GROUP BY存在隐式排序,触发filesort,导致SQL执行效率下降;
以上结论部分为个人理解,可能有不对的地方,希望大家留言讨论交流。
实验验证


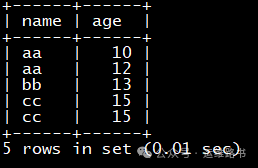
先建两张表t_users_idx(有索引),t_users_no_idx(无索引)
通常DISTINCT可以被看作是特殊的GROUP BY,它们的实现都基于分组操作,且都可以通过松散索引扫描、紧凑索引扫描来实现。
但是GROUP BY 在不同的版本中存在隐式排序,这会触发filesort,进而导致sql性能下降。
一
MySQL5.7
老规矩先看官方手册中的描述
https://dev.mysql.com/doc/refman/5.7/en/order-by-optimization.html
Note
GROUP BY implicitly sorts by default (that is, in the absence of ASC or DESC designators for GROUP BY columns). However, relying on implicit GROUP BY sorting (that is, sorting in the absence of ASC or DESC designators) or explicit sorting for GROUP BY (that is, by using explicit ASC or DESC designators for GROUP BY columns) is deprecated. To produce a given sort order, provide an ORDER BY clause.
翻译一下
接下来我们来证实一下,隐式排序的影响是否存在。
01
有索引
单列去重

执行计划中显示都是用了紧凑索引,索引字段和扫描行数都一样,因此性能也基本相同。
多列去重
DISTINCT 多列的去重,只有所有指定的列信息都相同,才会被认为是重复的信息。
执行计划同样distinct和 group by一致,性能相同。
02
无索引


无索引的情况下,从执行计划中可以看出无论是单列去重还是多列去重,GROUP BY都比DISTINC多了一项 “Using filesort”。
文件排序的过程包括将数据读取到内存中进行排序,如果数据量过大无法全部放入内存,还可能会使用临时文件进行辅助排序。这也是导致SQL性能下降的主要原因。
二
MySQL8.0
先看官方手册
翻译一下
01
有索引



无论单列去重还是多列去重,执行计划都一致,性能无差别。
02
无索引


同样,在无索引的情况下,无论单列去重还是多列去重,都是只用到了临时表,没有出现文件排序的情况,因此性能基本相同。
更推荐GROUP BY的理由
GROUP BY语义更为清晰
GROUP BY适合更为复杂的数据处理
相较于DISTINCT而言,GROUP BY语义更明确。
DISTINCT会对所有字段生效,在进行复合业务处理时,GROUP BY更灵活,GROUP BY能根据分组情况,对数据进行更为复杂的处理,例如通过having对数据进行过滤,或通过聚合函数对数据进行运算。

点击蓝字 关注我们