




Table of Contents
0 前言
在海山数据库(He3DB)+AI(三)中,介绍了四种旋钮调优方法:基于启发式,基于贝叶斯,基于深度学习和基于强化学习,还介绍了迁移学习技巧。本文带来2024 VLDB的论文:An Efficient Transfer Learning Based Configuration Adviser for Database Tuning,介绍一种基于迁移学习的启发式数据库调优方法。
3 OpAdviser
3.1 主要工作
在现有的旋钮调优方法中,没有一个方法可以在所有任务中都表现较好。本文探讨了以下两个原因:
- 无效的巨大搜索空间:一个数据库中需要配置的参数很多,有些参数的搜索空间很大。寻找最优配置的时间和搜索空间的大小成正比,巨大的搜索空间将导致巨大的调参成本,而研究表明,很多搜索空间是无意义的。
- 合适的优化器:针对不同的任务,不同的优化器表现出不同的性能,有时甚至导致几个数量级的性能损失。选择合适的优化器是一直以来面临的一个挑战。
本研究的目的是通过缩小搜索空间和选择合适的优化器来同时解决上述两个挑战,从而加速数据库调优。为了实现这一点,本文提出了OpAdviser,一种数据驱动的方法。具体来说,OpAdviser从不同的客户端和应用程序的调优任务中积累丰富的历史数据,从历史数据中进一步提取有价值的信息,实现搜索空间的紧凑和优化器的选择,从而减少大量的调试成本。
3.2 总体流程
OpAdviser的计算流程如下图所示。
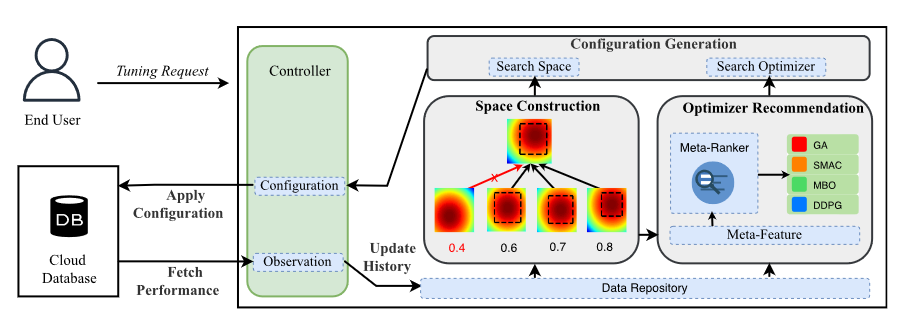
主要包含以下几个部分:
- controller:通过与终端用户和数据库实例的交互来控制调优过程
- data repository:存储历史数据,不同任务不同参数下的模型性能,以${\theta_ji,f(\theta_ji,w_i)}$的形式存储,其中$i$表示任务
- space constructor:构造紧凑的搜索空间
- optimizer adviser:选择合适的优化器
- configuration generator:由所选的优化器在所构造的搜索空间上生成配置参数
工作流程如下:
用户输入调优目标、调优成本预算、数据库实例和目标工作负载,在每一次迭代中,controller使用新的配置获取数据库性能,然后将这组数据放在data repository。基于data repository中的数据,space constructor得到一组范围更小的搜索空间(第4节内容)。optimizer adviser抽取元数据,然后将元数据输入到一个元排序器中(该元排序器在构建的基准数据集上进行预训练),由该元排序器来推荐优化器(第五节内容)。最后,将推荐的优化器和构建的搜索空间传递给配置生成器,生成配置参数,然后将这组参数返回给controller。当调优预算耗尽,就返回目前最好的配置参数。
OpAdviser的设计目的是自我完善,其性能随着数据存储库中积累的调优观测值的增加而提高。
4 确定搜索空间
本文提出了一种新的方法来自动构建精确的搜索空间,而不需要收集大量关于目标工作负载的观测值。本文的方法从以前的任务中提取有效区域来构建精确的搜索空间,主要包括三个部分:
- 相似任务识别:识别出与当前任务具有相似特征的候选任务集合
- 有效区域提取:根据任务相似度从每个候选任务中提取有效区域
- 多数加权投票:利用提取区域的几何结构来生成紧凑的搜索空间
4.1 相似任务识别
一个数据库在执行不同的调优任务时,可以积累丰富的历史经验。对当前任务,找到类似的历史任务,从历史任务中挖掘有用的信息,来指导当前的任务。
那么如何来量化当前任务和历史任务的相似性呢?
通过考虑两个任务在不同配置下是否具有相似的性能分布来解决这个问题。
假设用$(\theta,f(\theta))$来描述参数配置和性能。历史任务$m$在数据仓库中有一组性能数据${(\thetam_1,f(\thetam_1)),(\thetam_2,f(\thetam_2)),…(\thetam_n,f(\thetam_n))}$,并基于这组性能数据在离线阶段使用随机森林训练了性能函数$f’$ 。当前任务在迭代执行得到一组性能参数${(\theta_1,f(\theta_1)),(\theta_2,f(\theta_2)),…(\theta_,f(\theta_n))}$。OpAdviser通过计算两个任务之间$\theta$变化导致的$f()$变化是否一致来判断任务的相似性,即导数方向是否一致,其相似性计算公式如公式1所示:
$$
\begin{array}{l}
S(i, t)=\frac{2}{\left|H{t}\right|\left(\left|H{t}\right|-1\right)} F(i, t)
\end{array}
$$
$$
\begin{array}{l}
F(i, t)=\sum_{j=1}{\left|H{t}\right|} \sum_{k=j+1}{\left|H{t}\right|} \mathbb{1}\left(f\left(\theta_{j}\right) \leq f\left(\theta_{k}\right)\right) \otimes \mathbb{1}\left(f^{\prime}\left(\theta_{j}, w_{i}\right) \leq f^{\prime}\left(\theta_{k}, w_{i}\right)\right)
\end{array}
$$
公式中,$F(i,t)$是性能变化一致性的样本数量,$Ht$是现有任务的观察样本数量,$\frac{2}{|Ht|(|H^t|-1)}$则表示所有样本的组合,OpAdviser使用性能变化一致性样本数量占所有样本组合的比例来表示两个任务之间的相似性。
在判断任务相似性时,设定阈值为0.5,当相似度小于0.5时,将其过滤掉。
4.2 有效区域提取
当找到了与当前任务相似度高的历史任务,如何从中获取有用信息,来帮助缩小搜索的范围?
可以将其建模为一个优化问题,在保证最优参数在其范围内时最小化搜索空间,最优化公式如下所示:
$$\begin{array}{cc}
& \underset{\Phi^{i}}{\arg \min } \Lambda\left(\Phi^{i}\right), \
\text { s.t. } & \forall \theta \in G, \theta \in \hat{\Theta}\left(\Phi^{i}\right) .
\end{array}$$
在公式中,优化目标是最小化搜索空间$\hat{\Theta}\left(\Phi{i}\right)$,约束条件是这个空间中要包含所有的有希望的配置$G$。$G$通过已有的观察点和随机采样的一组配置来确定,若在该组配置下,模型性能超过一定阈值$f_bi$,就将其加入集合。而阈值$f_b^i$的确定由以下公式确定:
$$f_b^i = f_{default}i+2(fi_{best}-f^i_{default})(S(i,t)-0.5) $$
公式中,$fi_{default}$是历史任务在默认配置下的性能,$fi_{best}$是观察到的最好性能,$S(i,t)$是历史任务和当前任务的相似度。
设计这个计算公式的理由如下:
- 如果历史任务和当前任务高度相似,那么$f_b^i$的值会和 $f^i_{best}$很接近,那么搜索的空间很小。
- 如果历史任务和当前任务高度相似性不高,那么搜索空间就会变大。
搜索空间的面积由以下公式确定:
$$\Lambda\left(\Phi{i}\right)=\prod_{k_{j}{i} \in K 1}\left(\hat{u}{j}^{i}-\hat{l}{j}\right) \prod_{k_{t}^{i} \in K 2}\left|\hat{s}_{t}^{i}\right| $$
公式中,$K_1$表示连续的旋钮,$K_2$表示离散的旋钮。对于连续旋钮,其上界和下界分别为$\hat{u}{j}{i}$和$\hat{l}_{j}{i}$,其公式如下所示:
$$\hat{l}{j}^{i}=\min \left{\theta_{j} \mid \theta \in G\right}, \quad \hat{u}{j}^{i}=\max \left{\theta{j} \mid \theta \in G\right} $$
对于离散旋钮,其值由以下公式计算:
$$\hat{s}{t}^{i}=\left{\theta{t} \mid \theta \in G\right} $$
接下来,为了更进一步缩小搜索空间,使用特征算法[5]基于历史的观测信息来选择重要的旋钮。本文使用SHAP[1],SHAP是一个通过配置之间的性能变化来衡量特征重要性的工具,移除一些不值得调优的旋钮,从而进一步缩小搜索空间。
4.3 多数加权投票
通过以上两步,从每个候选任务中提取了有效区域,根据这些信息,来生成最后的目标搜索空间,包括哪些是重要的旋钮和其调参范围。
本文设计了一个多数加权投票策略来聚合来自候选任务的建议,根据每个历史任务和当前任务的相似度来计算其权重,计算公式如下所示:
$$w_{i}=\frac{S(i, t)}{\sum_{j=1}^{m} S(j, t)} $$
将总权重阈值设为50%,具有多数同意删除的旋钮被删除,多数同意保留的旋钮被保留,对于每个保留的旋钮,枚举其提取的有效范围和具有多数投票的区域,生成一个紧凑的区域将其包括在内。
为了避免负迁移,使用两条策略。
策略一:
根据在上一轮迭代中的观察样本和训练好的性能函数$f’$,在获得新的配置参数$\theta$后,使用3.2节的方法提取有效区域,公式如下:
$$
\begin{array}{l}
S(t, t)=\frac{2}{\left | H^{t} \right | (\left|H^{t}\right|-1)} F(t, t)
\end{array}
$$
$$
\begin{array}{l}
F(t, t)=\sum_{j=1}{\left|D{t}\right|} \sum_{k=j+1}{\left|D{t}\right|} \mathbb{1}\left(f\left(\theta_{j}\right) \leq f\left(\theta_{k}\right)\right) \otimes \mathbb{1}\left(f_{-j}^{\prime}\left(\theta_{j}\right) \leq f_{-k}^{\prime}\left(\theta_{k}\right)\right),
\end{array}
$$
随着模型的迭代,$f’$逐步提升,相似度逐渐提升。下图为基于候选任务进行搜索空间提取的过程,其中第一行为上一轮迭代中拟合的模型,第二至第四行为历史任务。随着迭代开始,不断获取新的采样点,根据这些采样点,计算与各个候选模型的相似度,然后基于相似度计算当前任务的权重。从图中可以看到,随着样本数量的增加,自身模型的权重不断上升。
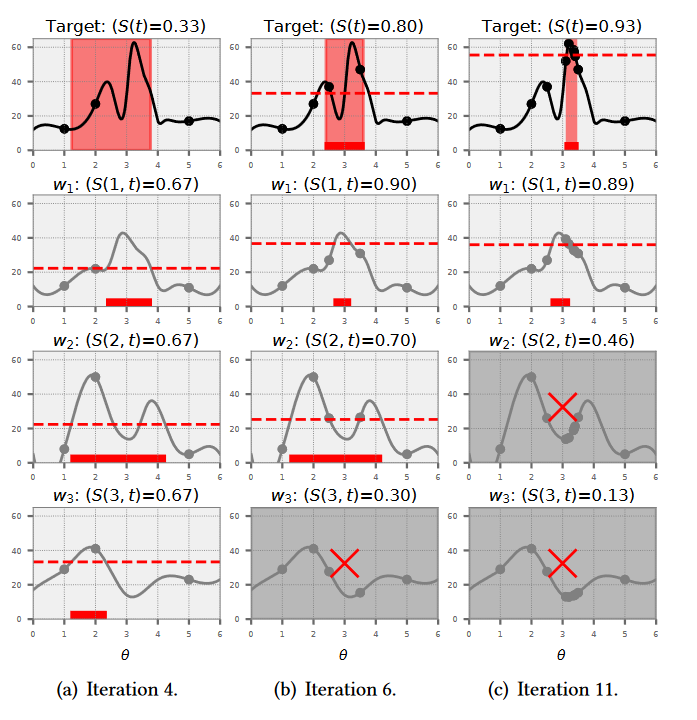
策略二:
对于候选任务,采样其中的$k$个(不是全部使用),根据其相似度来计算权重,采样是为了加入随机性,避免优化器陷入局部最优。
5 确定优化器
在确定优化器上,本文提出了一种数据驱动的方法,为给定的任务选择合适的优化器,该方法结合了任务的特点,进行具体问题具体分析。
5.1 元特征提取
在选择优化器时,要考虑任务的元特征。
已有工作表明,在选择优化器时,以下几个因素需要考虑:
- 搜索空间的维度和类型,一些优化器可能适合离散任务,一些可能适合连续
- 数据库性能响应函数
- 调优阶段,一些优化器可能在早期性能更好,一些在后期性能更好
因此,对于每个调优任务设计了以下元特征:
- 空间特征:该特征包括旋钮的数量、搜索空间和类别
- 相应函数特征:采用了5.2节的协调排序对来衡量当前任务和以往任务之间的相似度,构建了一个相似度向量,来看作是目标响应面的一个分布式表示
- 过程特征:使用迭代次数作为特征来表示调参过程
在每次迭代后更新元特征,使得可以在不同的迭代周期中选择合适的优化器,观测值是可以共享的。
5.2 离线数据生成
启发式的优化器选择依赖人的经验,无法适应变化的场景,本文设计了一种数据驱动的机器学习方法进行优化器的选择。
为了训练这个模型,需要监督数据,获得在不同的情况下各个模型的性能情况。然而,获得这个数据的成本是很高的,为了以较少的测试收集数据,本文采用主动学习的方法来选择测试和标注的样本。
首先通过改变搜索空间和响应来生成一组候选调优任务,然后采用classification margin[2]方法迭代地选择具有最高不确定性的任务进行测试。这一过程一直持续到达到期望的决策阈值或测试预算耗尽为止。
5.3 Meta-Ranker构建
利用收集到的数据,开始构建学习模型,本文采用了LambdaMART[3]算法,将优化器的选择问题转化为排序问题。LambdaMar将任务元特征和两个候选优化器作为输入进行比较,产生在给定任务上的相对性能排名。
模型输入:($m,o_i,o_j,I$)
模型输出:1或0
其中,$m$表示元特征,$o_i$和$o_j$为优化器的独热编码,$I$是一个标识符。当$o_i$的性能优于$o_j$时,输出为1,否则为0。
具体地,OpAdviser从目标任务中提取元特征,将该特征与候选优化器对一起输入到元排序器中,并推荐排名靠前的优化器。
元排序方法与其他方法相比,其优势如下:
1)与分类模型相比,通过考虑成对性能可以提取更多的信息;
2)与回归模型相比,只需要进行两两优化器之间的比较,可以更好地处理噪声数据和不同规模的数据。
6 参考文献
[1]Scott M. Lundberg and Su-In Lee. 2017. A Unified Approach to Interpreting Model Predictions. In NIPS. 4765–4774.
[2]David D. Lewis and Jason Catlett. 1994. Heterogeneous Uncertainty Sampling for Supervised Learning. In ICML. Morgan Kaufmann, 148–156.
[3]Christopher JC Burges. 2010. From ranknet to lambdarank to lambdamart: An overview. Learning 11, 23-581 (2010), 81.
