




近期阿里云新加坡的数据中心遭遇了火灾事故,很多朋友都在关注这个事情,火灾影响了该数据中心的正常运作,对依赖其服务的企业和个人造成了不同程度的影响。

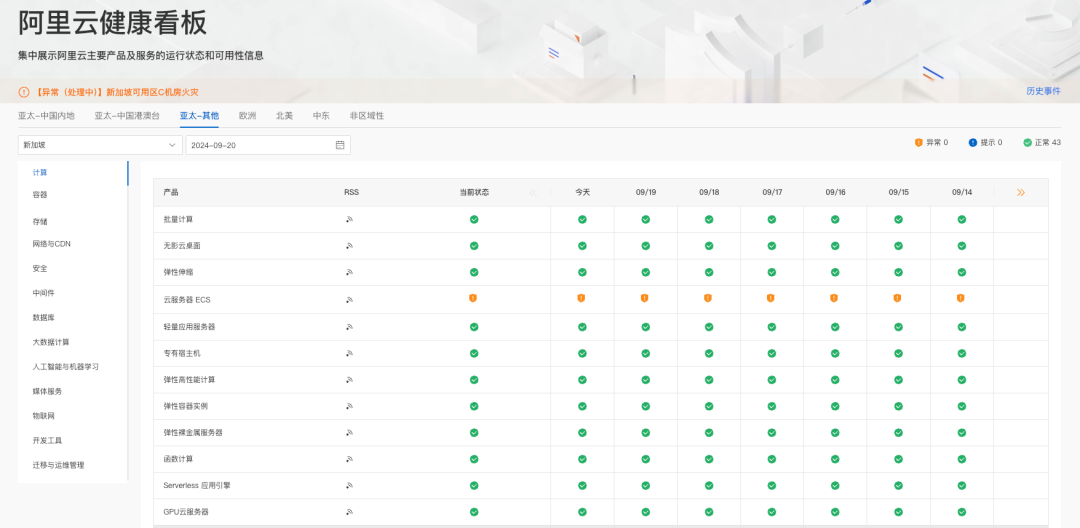
距离发生火灾的时间已经过去了10天的时间,从阿里云的健康看板上可以看到,云服务器至今没有恢复,存储数据的块存储、文件存储等花了9天的时间才恢复。(比较有意思的是,虽然下面云服务器ECS和日志服务状态还是故障,但上面的总异常却变成了0,不知道是不是看板的bug)
现在的应用基本都是无状态的,服务器挂了大不了换个服务器重新部署即可,但数据库的数据,如果没有设计容灾的机制,就会出大问题。
假设数据库都放在这次火灾发生的阿里云新加坡机房,火灾发生后,很可能还没来及将数据迁移出来,就已经和服务器失联了。这个时候,如果在其他地方有备份,还可以抢救一下,丢一些数据,但数据库拉起来还是可以继续提供服务的。如果没有备份,其他机房也没有备库,可能就得祈祷阿里云的硬盘烘干后还是正常的了。
所以设计并维护一套数据库的容灾架构就尤为重要,可以保证在极端事件发生时,公司的核心业务资产也不会受损。中启乘数科技推出了一套底层自研的PostgreSQL/PolarDB数据库管理平台CLup,在页面上点点鼠标,就可以快速的搭建和管理跨机房容灾的高可用数据库集群,使您的业务数据高枕无忧。
CLup数据库管理平台
CLup软件是专为PostgreSQL、PolarDB等数据库实现了高可用(包括读写分离)集群功能和基础监控管理以及对数据库进行定时或立即备份,恢复的平台软件。
基于流复制的高可用功能
在流复制的一主多备集群中,CLup安装在一台独立的机器上,CLup去探测各个数据库是否正常,如果不正常,则会进行相应的切换工作。当主库坏的时候,clup会自动把其中一台延迟最低的Standby库提升为主库,同时把vip也飘到新主库上。也可以手工在管理界面一键完成主备库的角色互换(switchover)。
基于共享存储的高可用功能
类似原先小型机HACMP的高可用方案,把共享存储挂载到两台机器上,数据库运行在其中的一台机器上,这台机器称为主用机,另一台机器称为备用机。当主用机出现问题时,CLup会自动把数据库切换到备用机上运行,同时也会把vip漂移过来,从而实现高可用。
基于流复制多个只读备库上的负载均衡功能
可以把一些可以承受少量延迟的只读请求负载到多个只读备库上。对外提供了一个只读vip,应用连接到这个只读vip时,会负载均衡到多台只读备库上。只读vip是在一台只读备库上,当这台只读备库出现问题时,只读vip会切换到其它的备库上。当一台只读备库出现问题后,这台只读备库会从负载均衡器中移除出去,这样请求就不会在发到这台坏的备库上了。
数据库监控报警功能
监控指标包括数据库连接数、WAL日志吞吐量、备库延迟、每秒操作的行数、TopSQL等指标的监控。可以对事务ID回卷、备库延迟、总连接数、活动连接数、磁盘使用率等指标进行报警。
CLup为什么好用?
集中管理: 可以对几十套至上百套PostgreSQL/PolarDB等高可用集群进行集中管理。通过一个统一的管理界面可以方便的看到所有数据库的运行状态。 功能全面: 可以对主机坏、硬盘坏、网络故障、网络孤岛、数据库故障等各种故障进行完善的高可用切换。可以同时支持对流复制和共享存储的高可用方案的支持。 负载均衡: 负载均衡和高可用机制紧密结合在一起。发生各种故障后无需任何人为干预,负载均衡可以不受影响的工作。 配置简单: 提供图形化的配置界面。内置了各种故障切换机制,无需写自定义的脚本来实现高可用功能,避免人为配置失误导致的系统不稳定。 监控简约实用: 数据库监控的最佳实践,监控项既不显得杂乱,有非常实用。
 点击关注乘数科技
点击关注乘数科技扫码添加乘数小助手微信号
邀您进入《PostgreSQL修炼之道:从小工到专家》
读者技术交流群

