




【前言:如果你经常使用Spark SQL进行数据的处理分析,那么对笛卡尔积的危害性一定不陌生,比如大量占用集群资源导致其他任务无法正常执行,甚至导致节点宕机。那么都有哪些情况会产生笛卡尔积,以及如何事前"预测"写的SQL会产生笛卡尔积从而避免呢?(以下不考虑业务需求确实需要笛卡尔积的场景)】
select * from test_partition1 join test_partition2;
select * from test_partition1 t1 inner join test_partition2 t2 on t1.name <> t2.name;
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id or t1.name = t2.name;
select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id || t1.name = t2.name;
--在Spark SQL内部优化过程中针对join策略的选择,最终会通过SortMergeJoin进行处理。select * from test_partition1 t1 join test_partition2 t2 on t1.id = t2.id and t1.name<>t2.name;
-- Spark SQL内部优化过程中选择了SortMergeJoin方式进行处理select * from test_partition1 t1 cross join test_partition2 t2 on t1.id = t2.id;
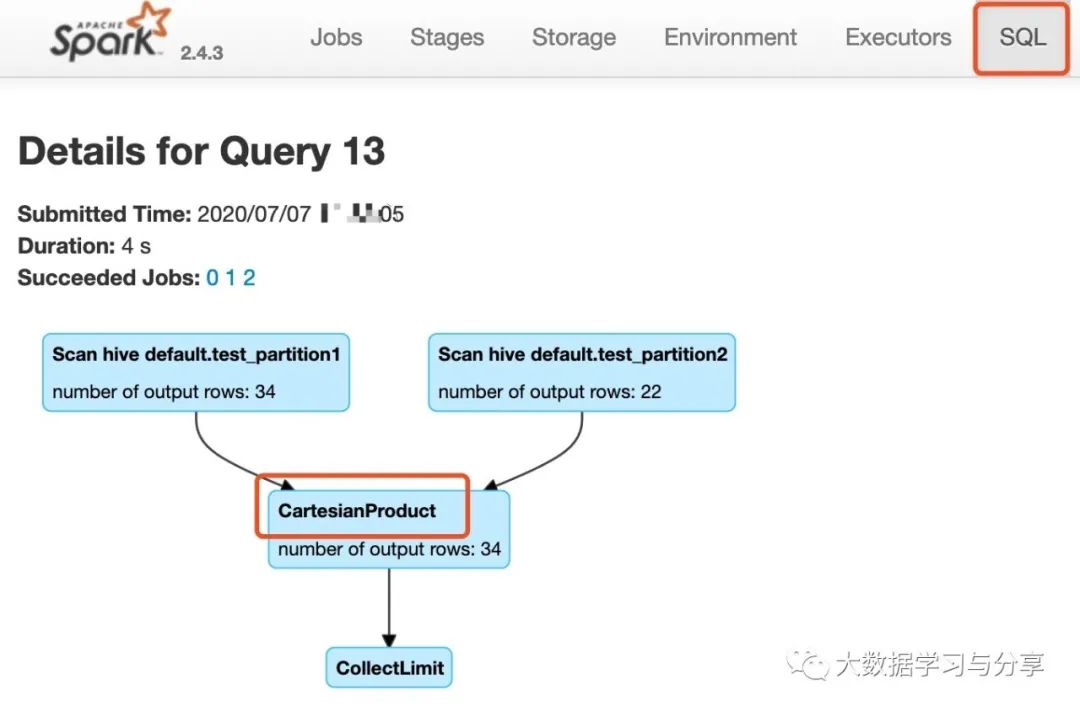
-- test_partition1和test_partition2是Hive分区表select * from test_partition1 join test_partition2;
== Parsed Logical Plan =='GlobalLimit 1000+- 'LocalLimit 1000+- 'Project [*]+- 'UnresolvedRelation `t`== Analyzed Logical Plan ==id: string, name: string, dt: string, id: string, name: string, dt: stringGlobalLimit 1000+- LocalLimit 1000+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]+- SubqueryAlias `t`+- Project [id#84, name#85, dt#86, id#87, name#88, dt#89]+- Join Inner:- SubqueryAlias `default`.`test_partition1`: +- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]+- SubqueryAlias `default`.`test_partition2`+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]== Optimized Logical Plan ==GlobalLimit 1000+- LocalLimit 1000+- Join Inner:- HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]+- HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]== Physical Plan ==CollectLimit 1000+- CartesianProduct:- Scan hive default.test_partition1 [id#84, name#85, dt#86], HiveTableRelation `default`.`test_partition1`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#84, name#85], [dt#86]+- Scan hive default.test_partition2 [id#87, name#88, dt#89], HiveTableRelation `default`.`test_partition2`, org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe, [id#87, name#88], [dt#89]
在利用Spark SQL执行SQL任务时,通过查看SQL的执行图来分析是否产生了笛卡尔积。如果产生笛卡尔积,则将任务杀死,进行任务优化避免笛卡尔积。【不推荐。用户需要到Spark UI上查看执行图,并且需要对Spark UI界面功能等要了解,需要一定的专业性。(注意:这里之所以这样说,是因为Spark SQL是计算引擎,面向的用户角色不同,用户不一定对Spark本身了解透彻,但熟悉SQL。对于做平台的小伙伴儿,想必深有感触)】 分析Spark SQL的逻辑计划和物理计划,通过程序解析计划推断SQL最终是否选择了笛卡尔积执行策略。如果是,及时提示风险。 具体可以参考Spark SQL join策略选择的源码: def apply(plan: LogicalPlan): Seq[SparkPlan] = plan match {// --- BroadcastHashJoin --------------------------------------------------------------------// broadcast hints were specifiedcase ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if canBroadcastByHints(joinType, left, right) =>val buildSide = broadcastSideByHints(joinType, left, right)Seq(joins.BroadcastHashJoinExec(leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))// broadcast hints were not specified, so need to infer it from size and configuration.case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if canBroadcastBySizes(joinType, left, right) =>val buildSide = broadcastSideBySizes(joinType, left, right)Seq(joins.BroadcastHashJoinExec(leftKeys, rightKeys, joinType, buildSide, condition, planLater(left), planLater(right)))// --- ShuffledHashJoin ---------------------------------------------------------------------case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if !conf.preferSortMergeJoin && canBuildRight(joinType) && canBuildLocalHashMap(right)&& muchSmaller(right, left) ||!RowOrdering.isOrderable(leftKeys) =>Seq(joins.ShuffledHashJoinExec(leftKeys, rightKeys, joinType, BuildRight, condition, planLater(left), planLater(right)))case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if !conf.preferSortMergeJoin && canBuildLeft(joinType) && canBuildLocalHashMap(left)&& muchSmaller(left, right) ||!RowOrdering.isOrderable(leftKeys) =>Seq(joins.ShuffledHashJoinExec(leftKeys, rightKeys, joinType, BuildLeft, condition, planLater(left), planLater(right)))// --- SortMergeJoin ------------------------------------------------------------case ExtractEquiJoinKeys(joinType, leftKeys, rightKeys, condition, left, right)if RowOrdering.isOrderable(leftKeys) =>joins.SortMergeJoinExec(leftKeys, rightKeys, joinType, condition, planLater(left), planLater(right)) :: Nil// --- Without joining keys ------------------------------------------------------------// Pick BroadcastNestedLoopJoin if one side could be broadcastcase j @ logical.Join(left, right, joinType, condition)if canBroadcastByHints(joinType, left, right) =>val buildSide = broadcastSideByHints(joinType, left, right)joins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nilcase j @ logical.Join(left, right, joinType, condition)if canBroadcastBySizes(joinType, left, right) =>val buildSide = broadcastSideBySizes(joinType, left, right)joins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nil// Pick CartesianProduct for InnerJoincase logical.Join(left, right, _: InnerLike, condition) =>joins.CartesianProductExec(planLater(left), planLater(right), condition) :: Nilcase logical.Join(left, right, joinType, condition) =>val buildSide = broadcastSide(left.stats.hints.broadcast, right.stats.hints.broadcast, left, right)// This join could be very slow or OOMjoins.BroadcastNestedLoopJoinExec(planLater(left), planLater(right), buildSide, joinType, condition) :: Nil// --- Cases where this strategy does not apply ---------------------------------------------case _ => Nil}
阿里巴巴开源大数据技术团队成立Apache Spark中国技术社区,定期推送精彩案例,技术专家直播,问答区近万人Spark技术同学在线提问答疑,只为营造纯粹的Spark氛围,欢迎钉钉扫码加入!
对开源大数据和感兴趣的同学可以加小编微信(下图二维码,备注“进群”)进入技术交流微信群。

Apache Spark技术交流社区公众号,微信扫一扫关注

文章转载自Apache Spark技术交流社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
