1️⃣ 选择具体字段:
查询employee表时,用SELECT id, name代替SELECT *。
2️⃣ 使用LIMIT 1:
查找名为”Jay”的员工,使用SELECT id, name FROM employee WHERE name='Jay' LIMIT 1。
3️⃣ 替代OR条件:
SELECT * FROM user WHERE user_id=1 OR age=18
改写为:
SELECT * FROM user WHERE user_id=1
UNION ALL
SELECT * FROM user WHERE age=18
4️⃣ 优化分页查询:
改写SELECT * FROM employee LIMIT 10000, 10为SELECT * FROM employee WHERE id > 10000 LIMIT 10。
5️⃣ 优化LIKE查询:
用SELECT user_id, name FROM user WHERE user_id LIKE '123%'代替LIKE '%123'。
6️⃣ 限定查询数据:
检查用户是否为VIP,使用SELECT user_id FROM user WHERE user_id='123' AND isVip=1。
7️⃣ 避免索引列使用函数:
将SELECT user_id, loginTime FROM loginuser WHERE DATE_ADD(loginTime, INTERVAL 7 DAY) >= NOW()改写为在应用层处理日期。
8️⃣ 避免表达式操作:
用SELECT * FROM user WHERE age = 11代替age-1 = 10。
9️⃣ 优先使用INNER JOIN:
连接orders和customers表,使用INNER JOIN而不是LEFT JOIN,如果只需订单数据。
🔟 索引列顺序:
确保SELECT * FROM user WHERE user_id=10 AND age=10中的索引列顺序与索引定义一致。
🔢 索引建立:
在WHERE和ORDER BY列上建立索引,如
CREATE INDEX idx_user_age ON user(age)。
⏩ 批量插入:
使用INSERT INTO logs (log_data) VALUES ('data1'), ('data2'), ...代替单条插入。
💡 覆盖索引:
确保查询字段与索引字段一致,如
SELECT user_id, loginTime FROM loginuser WHERE loginTime >= NOW()。
⚠️ 慎用DISTINCT:
避免在大数据集上使用SELECT DISTINCT name FROM employee。
✂️ 删除冗余索引:
分析索引使用情况,删除未使用的索引。
🔄 优化DML语句:
对大量数据操作时,优化SQL语句,如使用
DELETE FROM user WHERE user_id < 1000
代替逐条删除。
🎯 使用EXISTS和IN:
查询部门所有员工,使用
SELECT * FROM A WHERE EXISTS (SELECT 1 FROM B WHERE A.dept_id = B.dept_id)。
➡️ 优先使用UNION ALL:
如果不需要去重,使用UNION ALL代替UNION。
🔢 使用数字型字段:
将age字段定义为INT而不是VARCHAR。
🚫 限制索引数量:
保持索引数量在5个以内,避免过多索引。
🚫 避免返回过多数据:
限制返回的数据量,如SELECT id, name FROM employee LIMIT 100。
🚫 避免在重复数据字段上建立索引:
如性别字段。
📝 使用表别名:
SELECT e.id, e.name FROM employee e WHERE e.id = 10086。
🔤 优先使用VARCHAR/NVARCHAR:
定义name字段为VARCHAR(50)。
📊 优化GROUP BY:
在GROUP BY前过滤数据,如
SELECT department, COUNT(*) FROM employee WHERE department IS NOT NULL GROUP BY department。
📌 字符串字段使用引号:
SELECT * FROM user WHERE name='John'。
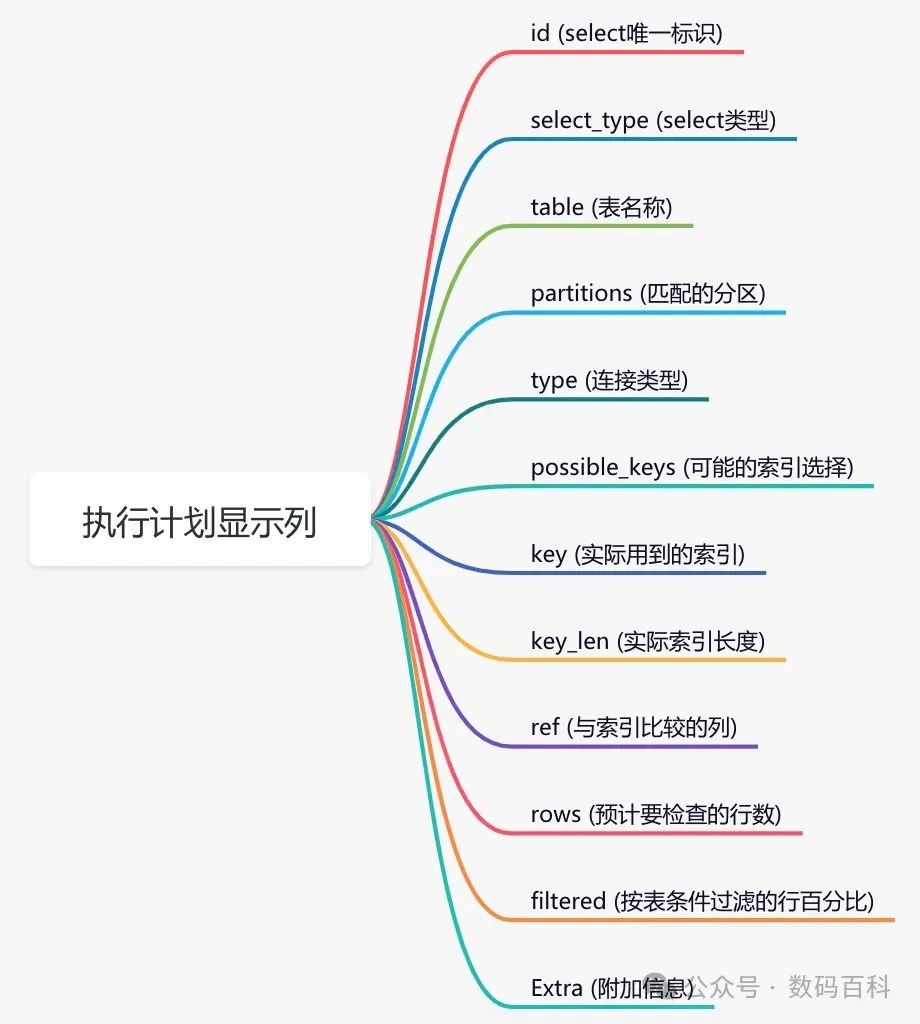
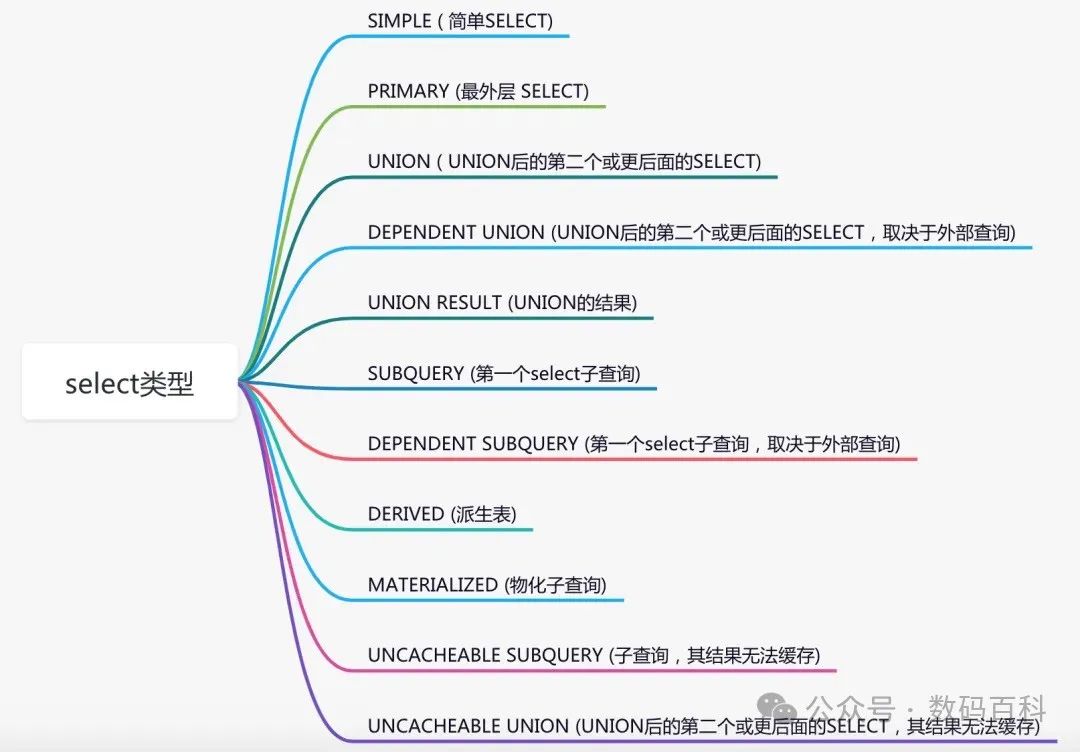
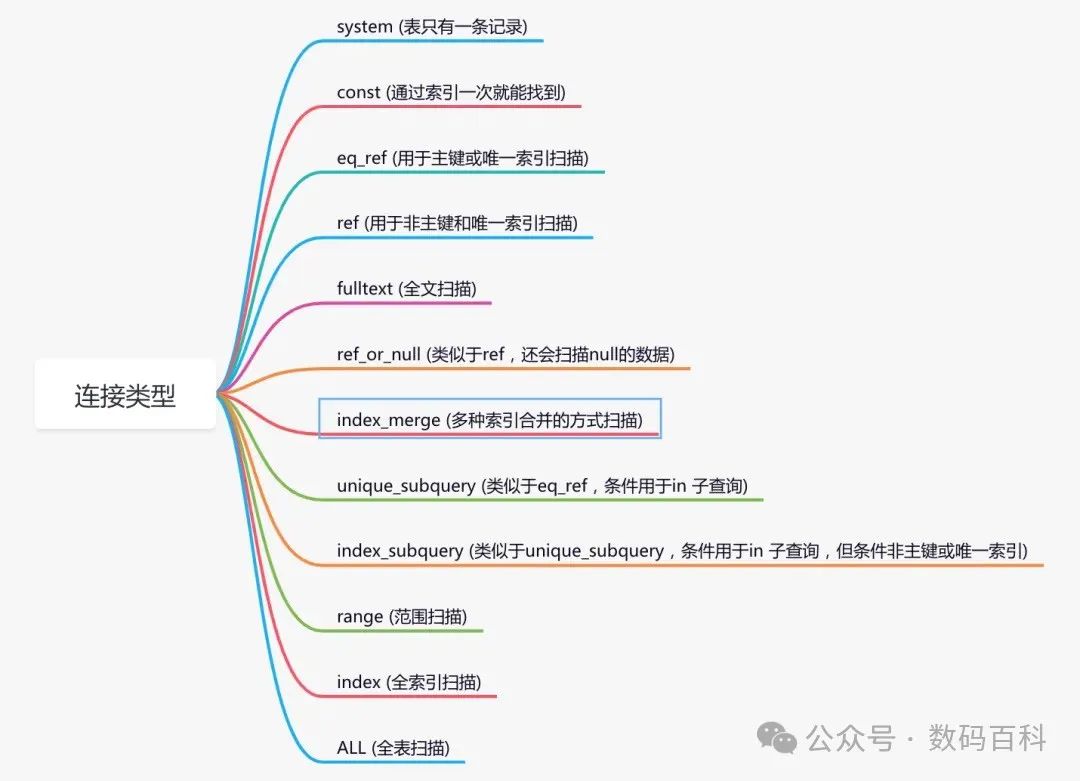
🔍 使用EXPLAIN:
分析SQL执行计划,如EXPLAIN SELECT * FROM user WHERE user_id=10086。