




前言
最近在翻译 Postgres-howto 系列时看到的一篇不错的文章,翻译一下。简而言之,如果系统时钟开销很高,那么 auto_explain,包括 explain analyze 都有可能会欺骗你,最好使用 pg_test_timing 测量一下。
the measurement overhead added by
EXPLAIN ANALYZEcan be significant, especially on machines with slowgettimeofday()operating-system calls.
介绍
auto_explain 是一个非常酷的模块,可以自动记录最慢查询的执行计划。它通过跟踪每个查询 (或其中的一部分),仅记录那些超过所设定阈值的查询结果。
这篇文章并不是关于 auto_explain 的介绍,但这可能是未来一个不错的主题。目前,如果你对它不熟悉,我建议阅读 PostgreSQL 文档中的 auto_explain 部分。
我们在此将探讨 auto_explain 的开销。很多地方都提到它的开销,但具体的信息难以获取。
通常提到的主要问题是 log_timing 参数,但我听说 log_buffers 也可能带来一定开销。听到的数字大约从 "约 3%" 到 "接近 2 倍" (这个范围相当大),但我没见过有明确的基准测试数据。
基于这些警告,我怀疑很多人不会在生产环境中使用 auto_explain,或者至少会关闭 log_timing 功能。但我也看到一些严谨的组织在生产环境中开启了 auto_explain 的 log_timing,这让我开始怀疑在某些条件下其开销是否会相对较低。
当然,即使没有每个操作的时间信息,记录执行计划也是有用的。不过,这在分析查询为何变慢时会有些限制。pgMustard 目前要求每个操作的时间数据,这也让我更有动机深入研究这个问题。
Ongres PostgreSQL 咨询公司的创始人 Álvaro Hernández 去年做了很好的工作,他发布了系统时钟缓慢对 EXPLAIN ANALYZE 开销的影响。在他的文章末尾,他还指出了不同操作的开销差异,举例说明了连接操作的高开销。
因此,我的假设是,在 1) 系统时钟开销较低的系统上,以及 2) 事务型负载下,auto_explain.log_timing 可能具有较低的开销。
研究不同系统时钟开销和工作负载是很有趣的,但这只能等到以后再做了。
设置
以下是我进行测试的设置:
PostgreSQL 13.2,安装于 macOS 10.15.7,使用 Postgres.app 2.4.2
2 核心,4GB 内存,SSD
postgresql.conf 的修改
shared_buffers = 1GB effective_cache_size = 3GB maintenance_work_mem = 256MB pgbench
默认的 TPC-B 类似负载 10 倍缩放 (~160MB) – 小于 shared_buffers 4 个客户端 – 在此设置下,每秒的事务数大致最佳 1800 秒 (30 分钟) 的测试时长 pg_test_timing
首先,我使用了我所熟悉的一个系统进行测试。
此处是 pg_test_timing 的结果:
michael$ pg_test_timing
Testing timing overhead for 3 seconds.
Per loop time including overhead: 90.61 ns
Histogram of timing durations:
< us % of total count
1 90.95840 30113986
2 9.03888 2992542
4 0.00080 264
8 0.00010 33
16 0.00168 555
32 0.00013 42
64 0.00002 5
128 0.00000 1
根据 pg_test_timing 文档所说,"好的结果是大多数 (>90%) 的单次时间测量在 1 微秒以内",所以从这一点来看,我们没问题。
结果
基准测试
在新安装好 PostgreSQL 并修改了参数之后,是时候获得一个基线进行比较了。
michael$ pgbench -i -s 10
...
michael$ pgbench -c 4 -T 1800
...
latency average = 1.585 ms
tps = 2523.482861 (including connections establishing)
tps = 2523.488970 (excluding connections establishing)
这给出了一个平均延迟为 1.585ms 的基准值。
记录每个查询计划
auto_explain 默认是关闭的。它还有一个 log_min_duration 参数,默认为 -1 (不记录)。所以通常会将 log_min_duration 设置为一个查询长度的阈值 (以毫秒为单位),用于想要调查的查询。作为起点,我想测试记录每个查询的执行计划,因此我将最小持续时间设为 0。注意,我们还没有跟踪时间或与此相关的任何其他执行细节。sample_rate 参数默认为 1 (所以 100% 的查询会被"采样"),但我希望明确说明这一点。
所以我将以下内容添加到 postgresql.conf 文件中并重启:
shared_preload_libraries = 'auto_explain'
auto_explain.sample_rate = 1
auto_explain.log_min_duration = 0
注意:可以降低 sample_rate 参数以对随机查询样本运行 auto_explain (例如,0.1 表示 10%)。我预计这是一种非常有效的方式来降低开销,但代价是信息的不完整。
我用之前的设置运行了 pgbench:
michael$ pgbench -i -s 10
...
michael$ pgbench -c 4 -T 1800
...
latency average = 1.994 ms
tps = 2005.883159 (including connections establishing)
tps = 2005.887957 (excluding connections establishing)
结果显式,平均延迟为 1.994ms,比基准值慢了约 26%。这让我很惊讶,因为据我所知的数字包括了跟踪时间,而这次并没有!我相信这是由于此系统的日志记录开销 (默认是 stderr)。此测试生成了约 6GB 的日志,这是不记录所有内容的另一个好理由!
仅记录最慢的查询
我决定尝试一个更合理的阈值,这次仅记录查询执行时间超过 10 毫秒的输出。
所以新的设置是:
shared_preload_libraries = 'auto_explain'
auto_explain.sample_rate = 1
auto_explain.log_min_duration = 10
然后再次重启:
michael$ pgbench -i -s 10
...
michael$ pgbench -c 4 -T 1800
...
latency average = 1.597 ms
tps = 2504.327824 (including connections establishing)
tps = 2504.334064 (excluding connections establishing)
结果显式,平均延迟为 1.597ms,仅比基准慢 0.8%。对于这种工作负载,10ms 的阈值意味着我们避免了记录大约 99.9% 的查询计划,只记录了最慢的查询及其计划 (由于测试运行了半小时,仍然记录了几百个计划)。值得注意的是,每个查询的执行计划的细节仍然会被跟踪,因为它事先不知道查询是否会超过我们的阈值 (auto_explain source code)。
总的来说,在我看来,这对于 log_timing 测试来说是一个更现实的起点。
不带时间的 analyze 的开销
开启 log_analyze 将跟踪每个查询的 EXPLAIN ANALYZE 细节。默认情况下,这会跟踪每个操作的时间数据,因此我们先关闭 log_timing。
以下是我们的新设置:
shared_preload_libraries = 'auto_explain'
auto_explain.sample_rate = 1
auto_explain.log_min_duration = 10
auto_explain.log_analyze = true
auto_explain.log_timing = false
再次重启后:
michael$ pgbench -i -s 10
...
michael$ pgbench -c 4 -T 1800
...
latency average = 1.590 ms
tps = 2515.130430 (including connections establishing)
tps = 2515.136821 (excluding connections establishing)
结果显式,平均延迟为 1.590ms,仅比基准慢 0.3%。虽然比上一次测试略快,但我怀疑这小于误差范围,因为我们现在跟踪了更多信息 (它变快对我来说没什么道理)。
时间记录的开销
我们再试一次,不过这次开启时间记录:
shared_preload_libraries = 'auto_explain'
auto_explain.sample_rate = 1
auto_explain.log_min_duration = 10
auto_explain.log_analyze = true
auto_explain.log_timing = true
再次重启后:
michael$ pgbench -i -s 10
...
michael$ pgbench -c 4 -T 1800
...
latency average = 1.620 ms
tps = 2469.825217 (including connections establishing)
tps = 2469.831173 (excluding connections establishing)
结果显式,平均延迟为 1.620ms,比基准慢了 2.2%,比不开启 log_timing 慢了 1.9%。这比我听到的最低的非正式数据还低——有趣!
buffers、verbose 等等的开销
因为我听说 buffers 也可能有开销,所以我也看了一下。事实证明,它对这种工作负载没有可测量的影响,因此为了简洁起见,我将所有其他可用的设置归为一组,看看它们是否有可测量的影响。这包括切换到更详细的 JSON 格式,pgMustard 目前需要这种格式来审查计划。
因此,postgresql.conf 文件中的新 auto_explain 参数是:
shared_preload_libraries = 'auto_explain'
auto_explain.sample_rate = 1
auto_explain.log_min_duration = 10
auto_explain.log_analyze = true
auto_explain.log_timing = true
auto_explain.log_buffers = true
auto_explain.log_verbose = true
auto_explain.log_triggers = true
auto_explain.log_settings = true
auto_explain.log_nested_statements = true
auto_explain.log_format = 'JSON'
再次重启后:
michael$ pgbench -i -s 10
...
michael$ pgbench -c 4 -T 1800
...
latency average = 1.613 ms
tps = 2479.817711 (including connections establishing)
tps = 2479.823888 (excluding connections establishing)
结果平均延迟为 1.613ms,比基准慢了 1.7%。与之前相似,尽管这次测量和记录了更多的内容,但结果却比上次快,因此我认为可以假定至少有几个基点的误差范围。但总体来说,我很惊讶 buffers 等等在这次工作负载上并没有增加可测量的开销。
总结
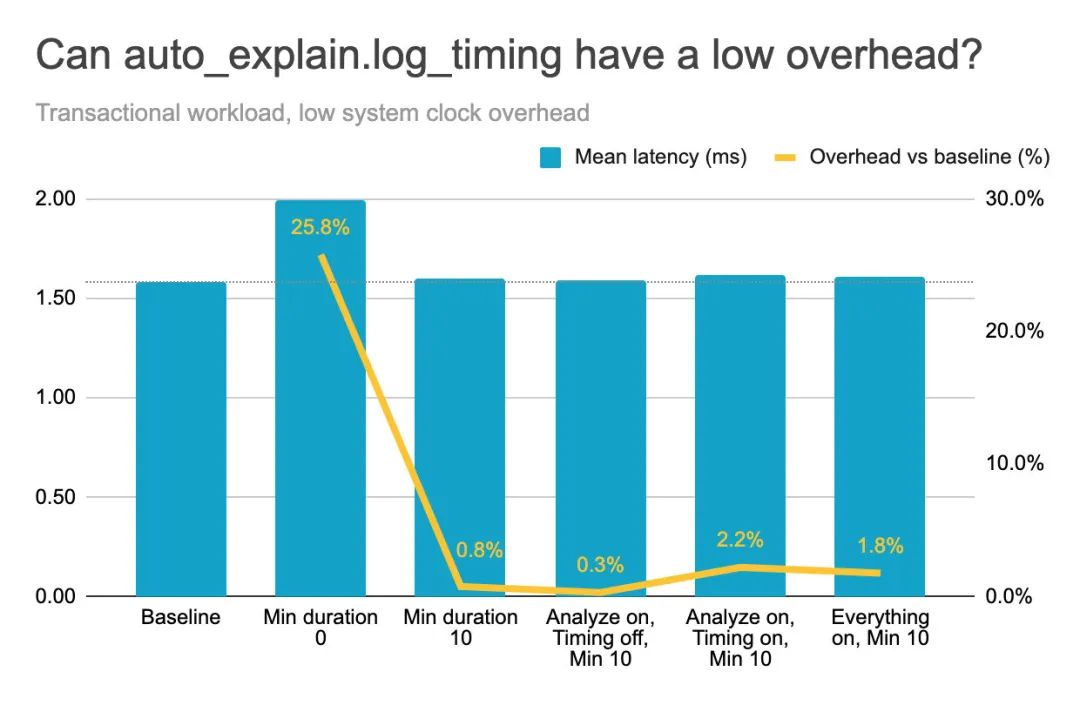
因此,当我们设置了一个合理的最小持续时间后,在这个小型事务型工作负载 (系统时钟开销较低) 上,关闭 timing 时,auto_explain 的开销不到 1%,而开启 timing 时,开销约为 2%。这是在没有进行采样的情况下完成的,因此每个查询的细节都被跟踪,但只记录了最慢的查询。
当我们将 min_duration 设置为 0 毫秒 (记录所有内容) 时,即使没有启用 analyze 和 timing 参数,开销也要高得多,超过 25%。我认为这是由于日志记录的开销所致。

结论和后续步骤
在这个小型事务型工作负载上,系统时钟开销较低的情况下,auto_explain.log_timing 的开销仅约为 2%。考虑到我听到的警告和数据,这比我预期的要低,我认为对很多人来说这是一项值得的投资。请记住,这还是在没有进行采样的情况下,因此每个查询的计划细节都被跟踪。
在这台系统/工作负载上,我发现唯一有可测量开销的参数是 timing,但请记住,我们的系统时钟开销较低,查询也不复杂。
作为下一步,我们可以在更接近生产环境的机器上检查这些结果。我还认为研究分析型工作负载的开销也非常有趣,或者尝试测量不同系统时钟开销的影响。最后,我相信大幅降低 sample_rate 会显著减少开销 (以错过相应比例的慢查询计划为代价),但这值得进一步测量。
很想听听大家是否对这些方面的研究感兴趣,以及接下来应该研究哪些。
非常感谢 Nikolay Samokhvalov 和 Haki Benita 对本文草稿的审阅。
原文译自:https://www.pgmustard.com/blog/auto-explain-overhead-with-timing
