




随着PostgreSQL 17的第一个候选版本(RC1)的发布,我们即将迎来一系列新特性、改进和优化。
作为后端开发者,有一个特性特别引人注目,它在众多新功能中脱颖而出:
允许B-tree索引更有效地找到一组值,例如使用常量IN子句提供的值(Peter Geoghegan, Matthias van de Meent)
B-tree是PostgreSQL最常用且优化最好的索引类型,用于查找表的主键或二级索引,无疑支撑着世界各地的各种应用,其中许多是我们日常互动的。
在查找过程中,B-tree被扫描,PostgreSQL从根节点开始,一直向下直到在叶子节点找到目标值。以前,像id IN (1, 2, 3)或id = any(1, 2, 3)这样的多值查找需要多次重复该过程。尽管不是非常高效,但因为B-tree查找非常快,所以这并不是一个大问题。只有对性能极其敏感的用户才会注意到这种不足。
从PostgreSQL 17开始,nbtree的ScalaryArrayOp执行得到了增强,情况不再总是如此。任何具有多个标量输入的特定扫描都会在遍历B-tree时考虑所有这些输入,并且当多个值落在同一个叶子节点时,它们会一起被检索,以避免重复遍历。
一个专门针对原始问题的脚本显示了在ScalaryArrayOp改进前后的显著性能提升,因此我们已经知道这些提升是非常真实的。随着PostgreSQL 17即将到来,我们想要尝试测量一个真实的Web应用程序可能从优化中获得的性能提升,通过测试它对Crunchy Bridge提供动力的真实API服务。
在我们的实验中,我们看到了大约30%的吞吐量提升和平均请求时间20%的下降——至少可以说是有希望的。继续阅读以了解更多细节。
列表端点和预加载
API是一个生产级别的程序(即具有认证、遥测和防御性加固等功能),用Go编写。我选择了它的GET /teams/:id/members端点(团队成员列表)作为测试对象,因为它在性能和复杂性之间是一个很好的中间地带。足够复杂,可以从索引改进中受益,但也足够简单,易于理解。
它返回团队成员API资源的列表:
// A team member. type TeamMember struct { apiresource.APIResourceBase // Primary ID of the team member record. ID eid.EID `json:"id" validate:"-"` // Properties of the account associated with the team member. Account *Account `json:"account" validate:"-"` // The role assigned to the team member. Role dbsqlc.TeamMemberRole `json:"role" validate:"required,teammemberrole"` } // Account information nested in a team member. type Account struct { // Primary ID of the account. ID eid.EID `json:"id" validate:"-"` // Email associated with the account. Email string `json:"email" validate:"required,email,apistring200"` // Indicates that the account has a password set, as opposed to being // SSO-only with no usable password. It's possible for an account to have // both a password and a federated identity through a provider like Google // or Microsoft. HasPassword *bool `json:"has_password" validate:"required"` // Indicates that the account has a federated identity for single sign-on // through an identity provider like Google or Microsoft. HasSSO *bool `json:"has_sso" validate:"required"` // Whether the account has at least one activated multi-factor source. MultiFactorEnabled *bool `json:"multi_factor_enabled" validate:"required"` // Full name associated with the account. Name string `json:"name" validate:"required,apistring200"` }复制
团队成员本身是最小的,只包含ID和角色作为其自己的属性,但嵌入了一个账户,详细说明了与团队成员关联的用户(在这个例子中,团队成员可以被认为是账户和团队之间的连接表)。
账户有像电子邮件和名称这样的明显属性,但也有像has_password和multi_factor_enabled这样的不太常见的属性,这些属性在UI中渲染团队成员列表时使用,以显示每个人的安全功能徽章,如“仅限SSO(无密码)账户”或“启用多因素”。这使管理员能够审查团队中每个人的安全姿态,为他们提供所需的信息,以便联系那些例如没有启用MFA的团队成员。
这些细节并不重要,但展示了一个常见的模式,即渲染最终产品需要多个数据库记录。团队成员和账户直接由它们自己的数据库模型支持,但尽管它们是布尔值,has_password和multi_factor_enabled需要为关联账户加载联合身份和多因素凭证记录。
加载团队成员页面并呈现API资源的最简单版本大致如下:
fetch_team_member_page().map do |team_member| account = fetch_account(team_member.account_id) render_team_member(team_member, account: render_account(account))复制
我们的版本看起来更像是:
team_members = fetch_team_member_page() bundle = fetch_load_bundle(team_members) team_members.map do |team_member| render_team_member(bundle, team_member, account: render_account(bundle, account))复制
关键区别在于循环中没有加载数据(例如fetch_account)。相反,我们使用两阶段加载和渲染,这是一种技术,其中渲染一组API资源所需的所有数据库记录都在一次通过中批量加载,使得N+1问题难以编写。
批量查询模式
获取团队成员页面的方式正如您所期望的(查询已简化以便于理解):
SELECT * FROM team_member WHERE team_id = <team_id>;复制
从结果中提取一组账户ID,并用它们进行几次查找:
- 为每个提取的账户ID选择账户记录:
SELECT * FROM account WHERE id = any(<account1>, <account2>, ...);复制
- 为账户获取联合身份,以便我们可以填充像
has_sso这样的属性。
SELECT * FROM account_federated_identity WHERE id = any(<account1>, <account2>, ...);复制
- 同样,为设置
multi_factor_enabled的值获取多因素。
SELECT * FROM multi_factor WHERE id = any(<account1>, <account2>, ...);复制
如果我们的应用程序的特定细节有点模糊,没关系,但请注意:
-
像任何Web应用程序或API一样,许多不同的数据库模型交织在一起以呈现最终产品。我们在这个端点上只使用了四个,但对于一个复杂的应用程序,渲染一个页面可能需要使用数百个不同的模型。
-
查找大量使用
id = any(...),其中被查询的集合可能相当大。我们API的默认页面大小是100,所以给定一个完整的页面,每个any(...)包含100个账户ID。
虽然我们使用了两阶段加载和渲染,但在像Ruby on Rails这样的框架中发现的预加载将产生类似的查询模式。
诱导负载
我们将使用出色的go-wrk来基准测试API,确保在持续一段时间(60秒)内进行,以补偿冷启动和缓存。
在典型的Web应用程序中,数据库调用通常占据了服务请求所花费时间的大部分,对于我们的团队成员列表端点也是如此,但还有相当数量的非数据库工作也在进行。传入的请求被解析,通过中间件堆栈发送,其认证被检查,遥测/日志被发出,响应被序列化,等等。
我们故意保留了这些额外的开销。使用大量合成数据结合精心设计的查询可以展示极端的性能优势,但我们试图展示索引查找改进将如何使现实用例受益。
为了有一组合理的数据进行测试,我生成了一个拥有100名(我们的默认页面大小)团队成员/账户的团队,以及联合身份和激活的多因素等相关记录。
使用PostgreSQL 16进行基准测试:
$ go-wrk -d 60 -H 'Authorization: Bearer cbkey_dbGR3HgJkeFyJ8VUXAXeQHlnb5gIlZdoNYoNI51jmCVH6V' -M GET http://localhost:5222/teams/matjsvug6vb7javsjsugxbjtiy/members Running 60s test @ http://localhost:5222/teams/matjsvug6vb7javsjsugxbjtiy/members 10 goroutine(s) running concurrently 74272 requests in 59.977486758s, 2.54GB read Requests/sec: 1238.33 Transfer/sec: 43.35MB Overall Requests/sec: 1237.71 Overall Transfer/sec: 43.33MB Fastest Request: 2.427ms Avg Req Time: 8.074ms Slowest Request: 147.039ms Number of Errors: 0 10%: 2.841ms 50%: 3.105ms 75%: 3.206ms 99%: 3.283ms 99.9%: 3.285ms 99.9999%: 3.285ms 99.99999%: 3.285ms stddev: 3.934ms复制
在PostgreSQL 17上:
$ go-wrk -d 60 -H 'Authorization: Bearer cbkey_4SgqjRk3B9lcZp7sIb8vWZiJQRtT2MUr4cn7SBapnC2tTX' -M GET http://localhost:5222/teams/matjsvug6vb7javsjsugxbjtiy/members Running 60s test @ http://localhost:5222/teams/matjsvug6vb7javsjsugxbjtiy/members 10 goroutine(s) running concurrently 94484 requests in 59.978741362s, 3.23GB read Requests/sec: 1575.29 Transfer/sec: 55.14MB Overall Requests/sec: 1574.54 Overall Transfer/sec: 55.12MB Fastest Request: 1.943ms Avg Req Time: 6.347ms Slowest Request: 97.279ms Number of Errors: 0 10%: 2.424ms 50%: 2.713ms 75%: 2.806ms 99%: 2.877ms 99.9%: 2.879ms 99.9999%: 2.88ms 99.99999%: 2.88ms stddev: 2.441ms复制
图表形式的亮点:
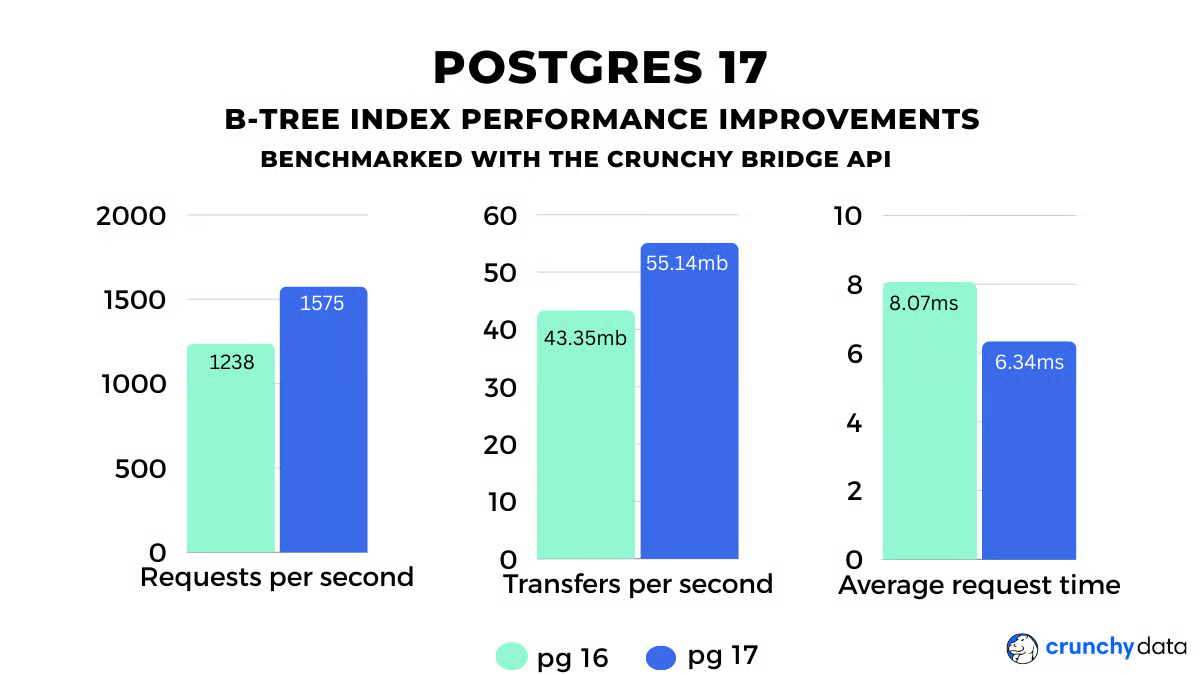
从PostgreSQL 16到17的跳跃显示了吞吐量约30%的提升(从1,238 RPS到1,575 RPS)和平均请求时间20%的下降(从8毫秒到6.3毫秒)。这不是像合成基准测试那样产生的完整倍数,但对于现实世界的应用来说,请求时间全面下降20%是一件大事。多年来,包括本文作者在内的许多开发人员都花费了更多的时间进行优化,但收益却远不如这次。
我们基于Go的API的设计和实现无疑是相当定制的,但我预计在像Rails这样大量使用预加载的框架的应用程序中,性能提升不会与此相差太远。
任何新版本的旗舰特性往往会获得最多的荣耀,但这些看不见但影响巨大的优化同样很好。没有什么比看到整个堆栈仅仅通过按下升级按钮就变得更快更令人满意的了!

原文作者:Brandur Leach
2024年9月23日



