Postgresql数据库和Oracle数据库一样,都是单独的序列,而不像MySQL其序列是绑定在一张表的字段上。MySQL的序列有以下限制:自增长只能用于表中的某一个字段、自增长只能被分配给固定表的某一个固定的字段,不能被多个表共用。但是Postgresql数据库没有以上限制。
泽拓昆仑Klustron完全支持PostgreSQL的序列功能并且用法也完全相同。并且Klustron也支持Oracle的序列功能和语法。
原文作者:CSDN博主[Major_ZYH]
关键词:PostgreSQL、序列
01 
CREATE [ TEMPORARY | TEMP ] SEQUENCE [ IF NOT EXISTS ] name
[ AS data_type ]
[ INCREMENT [ BY ] increment ]
[ MINVALUE minvalue | NO MINVALUE ] [ MAXVALUE maxvalue | NO MAXVALUE ]
[ START [ WITH ] start ] [ CACHE cache ] [ [ NO ] CYCLE ]
[ OWNED BY { table_name.column_name | NONE } ]
如果指定了此选项,序列对象会只会创建在当前会话中,会话退出时自动删除,临时序列存在的会话,同名称的永久性序列不可见,但是可以指定模式名称来查看。如果具有相同名称的关系已经存在,则不要抛出错误。在这种情况下会发出提示。要注意的是,不能保证现有的关系与将要创建的序列有任何相似之处—它甚至可能不是一个序列。ata_type的可选子句指定序列的数据类型。有效的类型有smallint、integer和bigint。默认是bigint。数据类型决定了序列的默认最小值和最大值。可选子句INCREMENT BY INCREMENT指定将哪个值添加到当前序列值以创建新值。也就是序列步长。一个正的值将使一个上升的序列,一个负的值将使一个下降的序列。默认值是1。可选子句MINVALUE minvalue 、NO MINVALUE确定序列可以生成的最小值。如果没有提供这个子句,或者将使用默认值 NO MINVALUE。升序序列的默认值是1。降序序列的默认值是数据类型的最小值。可选子句MAXVALUE maxvalue、NO MAXVALUE 确定序列的最大值。如果没有提供这个子句,或者将使用默认值 NO MAXVALUE。升序序列的默认值是数据类型的最大值。降序序列的默认值是-1。指定cache的数值,缓存几个系列值,默认是1,表示一次性生成1个值,也就是不缓存。在序列达到最大值maxvalue或最小值minvalue时,是否循环从新开始。默认是NO CYCLE。11.OWNED BY table_name.column_name 或 OWNED BY NONEOWNED BY 选项用于将序列关联到一个特定的表字段上,当删除字段或所在的表时序列也会自动删除。指定的表和序列必须在同一个模式下被同一个用户拥有。默认是无关联OWNED BY NONE。02 postgres=# create sequence seqtest01;
CREATE SEQUENCE
postgres=# select nextval('seqtest01');
nextval
---------
1
(1 row)
postgres=# select nextval('seqtest01');
nextval
---------
2
(1 row)
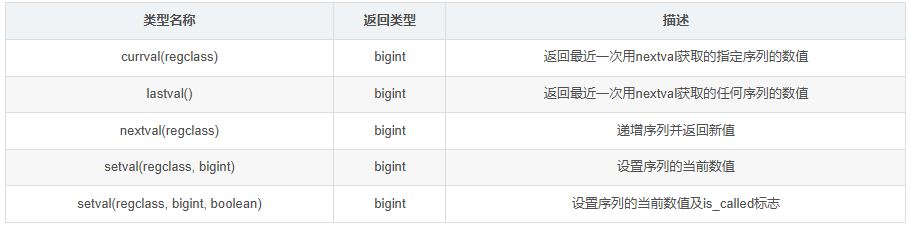
nextval函数的参数是regclass,而输入的是一个字符串,这因为regclass类型会自动把字符串转成regclass类型。使用currval函数可以返回最近一次使用nextval获取的指定序列的数值:postgres=# select nextval('seqtest01');
nextval
---------
2
(1 row)
postgres=# select currval('seqtest01');
currval
---------
2
(1 row)
postgres=# select nextval('seqtest01');
nextval
---------
3
(1 row)
postgres=# select currval('seqtest01');
currval
---------
3
(1 row)
注意如果在新会话中直接调用currval会报错,必须是在执行过一次nextval函数的会话中调用才行。lastval函数与currval函数不同,不管最后调用的是哪个序列,总返回最后一次调用的nextval函数的值,不限制序列,只返回最后一次调用的。setval函数能够改变序列的当前值,若之后在调用nextval,返回的值将变成改变后的当前值+1:postgres=# select nextval('seqtest01');
nextval
---------
5
(1 row)
postgres=# select setval('seqtest01', 2);
setval
--------
2
(1 row)
postgres=# select nextval('seqtest01');
nextval
---------
3
(1 row)
三个参数的setval使用时,如果设置了is_called为true,表示下一次的nextval将在返回数值之前递增该序列。如果设置了is_called为false,那么下一次nextval将返回声明的数值,只有再次调用nextval才开始递增该序列。如:postgres=# select setval('seqtest01', 2, true);
setval
--------
2
(1 row)
postgres=# select nextval('seqtest01');
nextval
---------
3
(1 row)
postgres=# select nextval('seqtest01');
nextval
---------
4
(1 row)
postgres=# select setval('seqtest01', 2, false);
setval
--------
2
(1 row)
postgres=# select nextval('seqtest01');
nextval
---------
2
(1 row)
postgres=# select nextval('seqtest01');
nextval
---------
3
(1 row)
03 - 在BEGIN事务中使用序列后,回滚事务,序列不会回滚。
- 序列的范围是bigint范围,在不支持8字节整数的编译器会是普通的integer范围。
- 使用cache缓存大于1的序列到多会话并发环境,因为每次缓存后的数值会在会话后丢失,造成序列出现空洞现象。
https://blog.csdn.net/qq_32838955/article/details/105472627为促进团队内外的沟通联系,我们Klustron团队的bbs论坛开始上线,欢迎各位同学使用!(链接:https://forum.klustron.com/,或者点击文末“阅读原文”,即可跳转)论坛目前是测试版,可能还存在不稳定的现象,欢迎各位老师、朋友共享信息,如果遇到问题还请谅解。欢迎大家下载和安装Klustron数据库集群,并免费使用(无需注册码)。http://downloads.klustron.com/如需购买请邮箱联系sales_vip@klustron.com,有相关问题欢迎添加下方小助手微信联系🌹https://doc.klustron.com/zh/Klustron_Instruction_Manual.htmlhttps://doc.klustron.com/zh/Klustron_Quickly_Guide.htmlhttps://doc.klustron.com/zh/Klustron-function-experience-example.htmlhttps://doc.klustron.com/zh/product-usage-and-evaluation-guidelines.html