




Postgres Language Server: implementing the Parser
Language Server's Core: The Role of the Parser
在最高层次上,语言服务器是一个能够:
1. 接受来自客户端的输入源代码
2. 将其转换为代码的语义模型
3. 并将特定语言的智能反馈提供给客户端的东西。
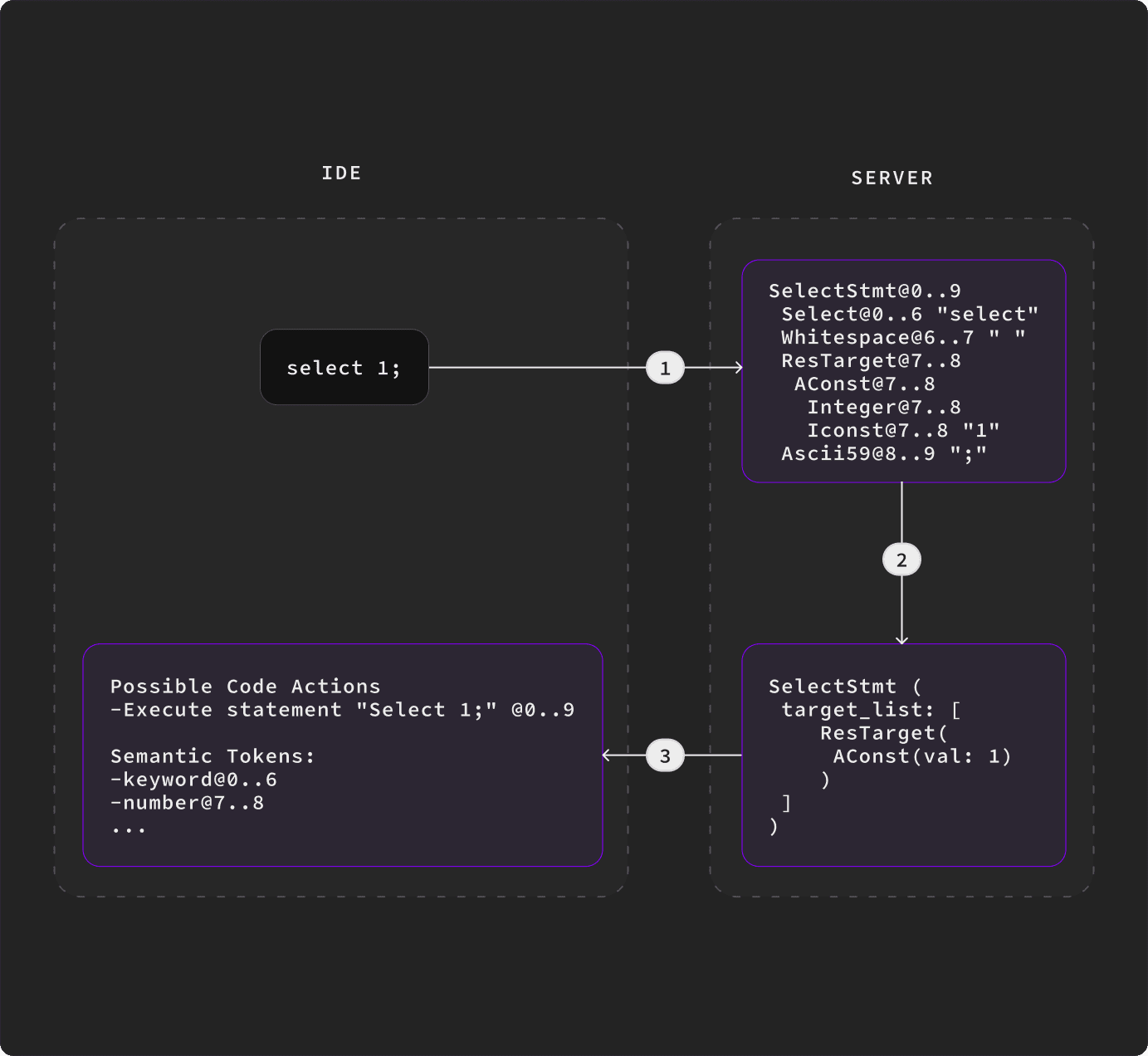
解析器是每个语言服务器的核心。它将原始字符串转换为一系列标记,并构建语法树。然后可以使用这棵语法树提取结构信息。
通常,解析器会先构建一个具体语法树(CST),然后再将其转换为抽象语法树(AST)。CST 保留了源代码中存在的所有语法元素,目的是能够重新创建出与原始源代码完全相同的内容,而 AST 仅包含源代码的意义。例如,考虑一个简单的表达式 2 (7 + 3):

Implementing a Parser for Postgres
实现一个Postgres解析器是具有挑战性的,因为Postgres的语法不断演变且非常复杂。即使是SELECT语句也非常复杂,需要解析。然后还有常见的CTE、子查询等。这是现有的Postgres工具稀缺、维护不善且往往效果不佳的原因之一。
我们决定不创建自定义解析器。相反,我们利用libpg_query来可靠地解析SQL代码。pganalyze团队发布了一篇很棒的博客文章,解释了为什么这种方法更可取。
然而,libpg_query的设计是为了解析可执行的SQL——而不是提供语言智能。将其用于语言服务器意味着需要将其适应我们的特定用例。让我们来探讨一下我们是如何适应它的:
Tokenization
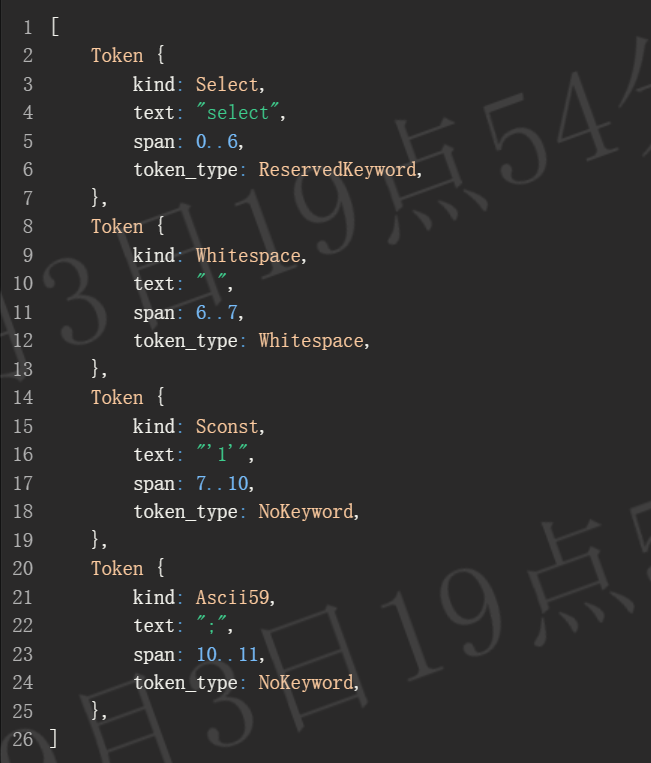
在构建任何语法树之前,输入字符串需要被转换为一系列标记。libpg_query 提供了一个scan API,该 API 返回源代码中的所有非空白标记,即使是无效的 SQL 也能处理。例如,一个简单的语句 `select '1';` 返回:

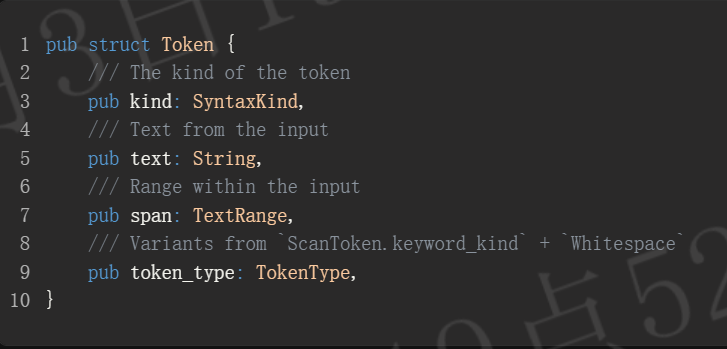
每个 `ScanToken` 标记包含其变体、范围和关键字类型。为了简化解析器的实现,我们目前使用范围提取每个标记的文本。我们得到了如下的 `Token` 结构体。
为了获得完整的标记流,我们将扫描结果与源代码中所有空白标记的列表合并,后者通过一个简单的正则表达式提取。对于一个简单的语句 `select '1';`,词法分析器返回以下标记。
Conversion to a Syntax Tree
Reverse-Engineering the CST
我们遇到的第二个限制是:libpg_query 仅公开了 AST 的 API,而没有 CST 的 API。为了在源代码上提供语言智能,两者都是必需的。由于我们不想实现自己的解析器,我们需要利用现有的资源来构建 CST:即 AST 和一系列标记。目标是将 AST 逆向工程为 CST。这涉及将 AST 节点重新用作 CST 节点,并确定哪个标记属于哪个节点。示例语句 select '1'; 应该被解析为:

为此,我们需要知道 AST 中每个节点的范围。在过去的几个月里,我们进行了多次迭代,以找出如何以最少的手动实现来完成这一任务。在深入细节之前,让我们仔细看看 libpg_query 的parse API。对于上述示例语句,它返回(为便于阅读进行了简化):

有一些限制:
1. 一些节点确实有一个location属性,指示节点在源代码中的起始位置,但并不是所有节点都有。
2. 没有关于节点在源代码中的范围信息。
3. 一些位置并不是你所期望的。例如,表达式节点的位置是操作符的位置,而不是左侧表达式的起始位置。
总结一下:我们需要每个节点的范围,但我们只有起始位置,而且并不总是有,有时还不正确。
我们最初的几次迭代是比较天真的。我们探索了可以从scan和parse提取的信息,看看是否有任何东西可以帮助逆向工程 CST。
事实证明,确定节点范围的最可靠方法是了解该节点的所有属性及其在树中的位置。
属性是指在源代码中可以找到Token的任何文本。例如,SelectStmt 节点有 select 关键字作为属性,如果有 from_clause,则有 from 关键字。对于上述示例语句,属性是:

请注意,我们没有额外的 String 节点,而是将其属性添加到父节点 AConst 中。原因是 String 节点对 CST 没有任何价值,因为我们已经从相应的 Token 类型中知道 '1' 是一个字符串。对于只包含类型信息的所有节点,如 Integer、Boolean 和 Float,情况也是如此。任何节点的位置在 AST 和 CST 中都是相同的,因此可以从中反映出来。
Implementation
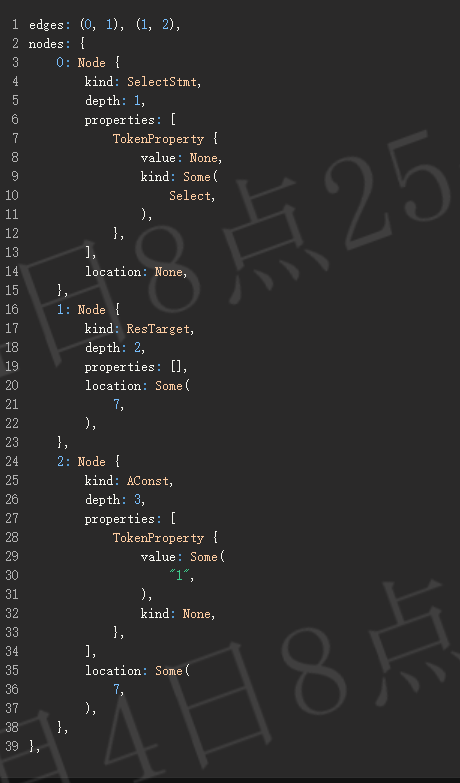
在实际解析开始之前,解析返回的 AST 被转换为一种统一的树结构,其中每个节点包含节点的类型、属性列表、深度以及(如果有的话)位置。
举例,对于 select '1'; :
要实现这样的转换,我们需要一种方法来:
- 获取每种节点类型的位置(如果有的话),返回一个 Option<usize>。
2.编译一个包含节点所有属性的列表。
3.遍历AST 直到到达叶子节点。
由于 Rust 的严格类型系统,手动实现将是一项重大且重复的工作。对于像 JavaScript 这样的语言,获取节点的位置就像 node?.location 那样简单。在 Rust 中,需要一个覆盖所有可能节点的大型 match 语句才能实现相同的功能。幸运的是,libpg_query 导出了一个包含所有 AST 节点及其字段的 protobuf 定义。例如,AExpr 节点被定义为:

我们对该定义进行反射,以便在构建时使用过程宏生成代码(procedural macros)。
利用 quote crate 强大的重复特性,get_location 函数的 match 语句可以用仅仅几行代码实现。
Parsing a Statement
在树生成后,解析器会遍历标记,并找到当前标记可以在其属性中找到的节点。但并不是每个节点都是可能的后继节点。让我们从高层次上看一下解析器如何为语句 select '1' from contact 构建 CST。
我们从完整的树和所有标记开始:
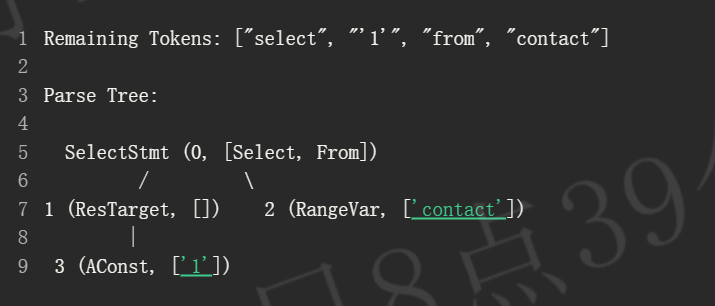
从根节点开始,解析器首先在当前节点中搜索该标记。在这种情况下,成功找到了。Select 从 SelectStmt 中移除。
在下一次迭代中,我们搜索 '1'。由于它不在当前节点中,因此使用广度优先搜索在子节点中查找属性。我们到达 AConst,打开沿途遇到的所有节点,并继续前进。
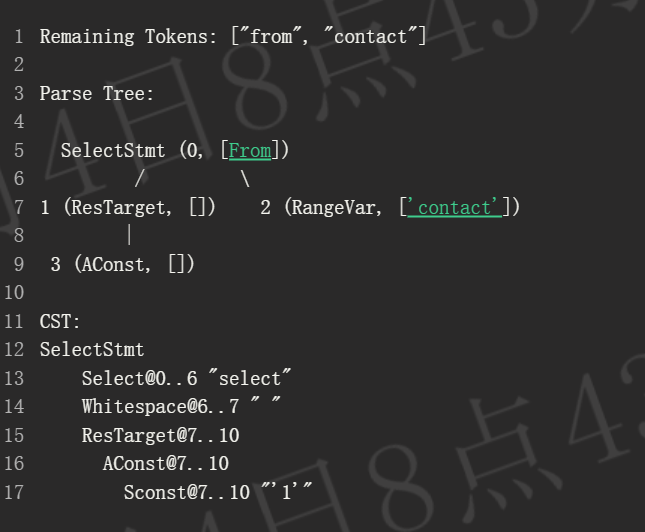
由于我们到达了一个没有剩余属性的叶子节点,下一个标记不能是该节点或任何子节点的一部分。在推进标记后,可以立即关闭该节点。我们将其从树中移除,并将当前节点设置为其父节点。现在同样适用于 ResTarget,因此我们回到了 SelectStmt:
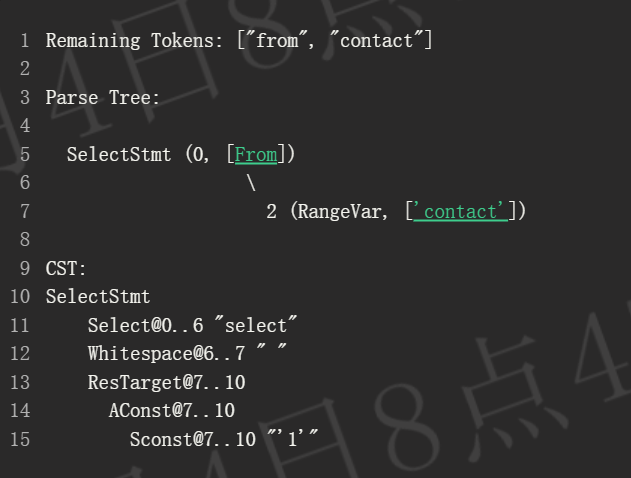
from 标记再次可以在当前节点中找到,我们只需推进解析器。由于 SelectStmt 不是叶子节点,我们保持当前位置。
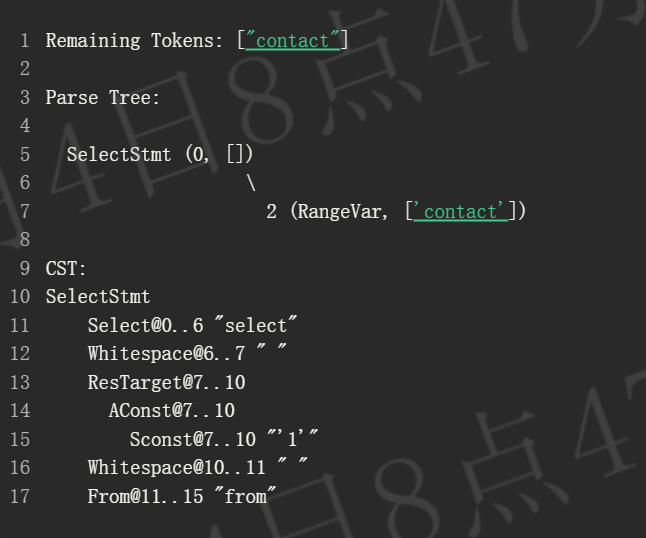
从这里开始,过程会重复:contact 在 RangeVar 中通过广度优先搜索找到。它成为一个叶子节点,在应用标记后关闭。由于没有剩余的标记,我们通过关闭 SelectStmt 完成解析,结果如下:
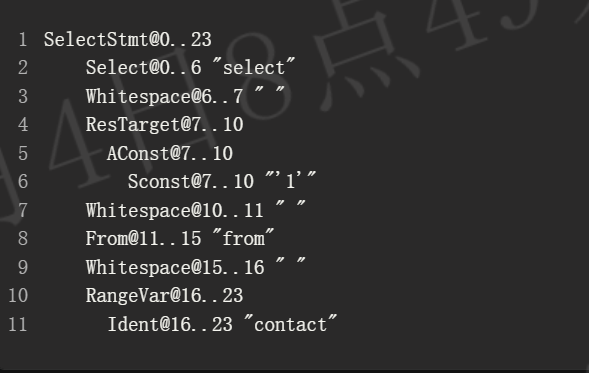
请记住,这个示例仅展示了过程的概述。如果您对细节感兴趣,可以在这里查看源代码。
您可能注意到没有提到位置或深度。这两者仅用于提高性能和安全性。其他方面,解析器会跳过当前解析器位置后面的节点的分支。此外,当打开一个节点且其位置或深度与解析器的当前状态不匹配时,解析器会发生恐慌。这意味着返回的 CST 是保证正确的。
