




导言
网络拓扑结构,熟悉Hadoop HDFS 的朋友对此一定都不陌生,它代表着集群中节点物理上的位置和分布信息。HDFS中数据保存在集群中成百上千的datanode上,上层的计算任务调度时,调度器会想方设法将任务调度到离数据最近的节点上,这叫做“数据的局部性”,因为移动计算的代价比移动数据要小。
那随着计算存储分离趋势的流行,“数据的局部性”已经可以不予考虑,分布式存储集群还有必要保留和了解节点的网络拓扑结构吗?答案是“需要”。因为网络拓扑结构的了解关乎集群的写入性能,故障容错能力和高可用性。
网络拓扑结构
下图是一个典型的物理网络拓扑结构图,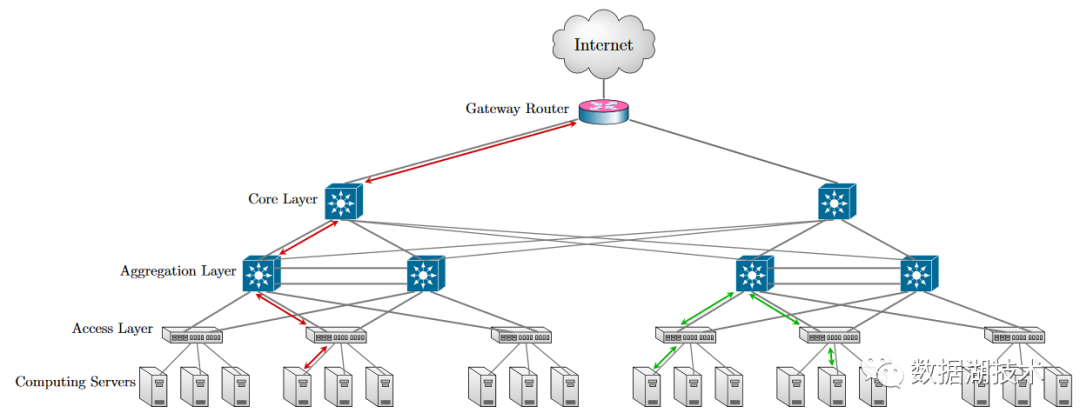
从上到下,每层的网络带宽总和依次变小。同时网络包经过的层级越多,端到端的时延越长。在Hadoop中,为了模拟真实的网络关系,用树来表示网络拓扑结构。下图是一个四层的网络结构,
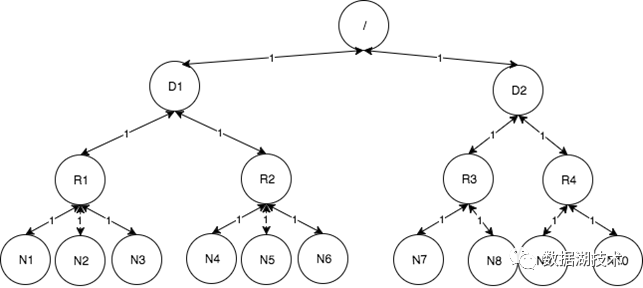
由虚拟的ROOT节点开始,中间节点是逻辑节点,可以代表机架,核心路由器,房间,甚至数据中心。最下层的叶子节点代表一个datanode。两个datanode之间的距离等于它们到最接近的共同祖先的距离之和。
Ozone的每份数据需要在3个数据节点上,每个写1个副本。数据节点间网络距离的远近带来时延的不同。从写入性能的角度考虑,下面的排列时延依次增加,性能依次递减,
节点(VM或者Contaner)在同一物理节点上 节点在同一机架上不同物理节点上 节点在同一数据中心不同机架上 节点在不同数据中心机架上
而从集群故障容错能力和高可用性角度考虑,上面的排列容错性和可靠性又是依次增加的。所以在实际中,通常会兼顾考虑这2个需求,达到性能和可靠性的一个平衡。
HDFS默认的选择策略是,3个副本中其中2个写入同一个机架的不同节点,第3个副本写入不同机架的节点。当前Ozone默认也是采用的该方式。
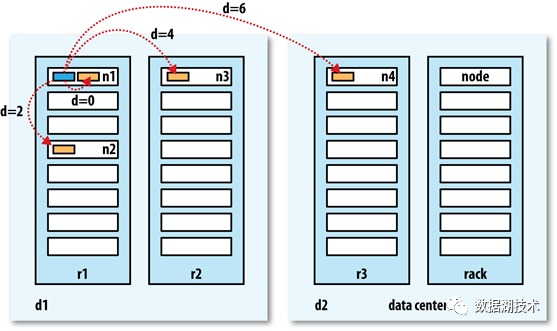
但是随着多数据中心的流行,以及用户对于数据不再满足于机架级别故障的容错能力,希望能保证数据中心级别故障的容错性,一些存储系统开始将3副本中的2个副本写入同一个数据中心的同一个机架不同物理节点上,第3个副本写入不同数据中心的节点上,来满足数据中心级别的故障容错需求。
也有一些存储系统部署在虚拟机上,或者Kubernetes集群中,数据节点不再一一对应物理节点,而是很多数据节点对应一个物理节点。在这种情况下,为了保证数据的安全可靠性,需要考虑的因素就更多了。
定制化的网络拓扑结构
HDFS支持三层和四层网络拓扑结构,副本的选择策略可通过Property来配置。Ozone的网络拓扑结构和副本选择策略都可以通过Property来配置。默认支持三层拓扑结构,和HDFS兼容,同时通过可配置的网路拓扑结构,满足不同用户不同的实际需求。
Ozone通过XML配置文件来定义新的网络拓扑结构。在安装好的一个Ozone集群中,etc/hadoop/目录下有2个相关的配置文件,network-topology-default.xml 和 network-topology-nodegroup.xml, 分别定义了和HDFS兼容的三层和四层网络构架。下图是network-topology-default.xml,
<configuration>
<!-- The version of network topology configuration file format, it must be an integer -->
<layoutversion>1</layoutversion>
<layers>
<layer id="datacenter">
<prefix></prefix>
<cost>1</cost>
<type>Root</type>
</layer>
<!-- layer id is only used as the reference internally in this document -->
<layer id="rack">
<!-- prefix of the name of this layer. For example, if the prefix is "dc", then every
name in this layer should start with "dc", such as "dc1", "dc2", otherwise NetworkTopology
class should report error when add a node path which does't follow this rule. This field
is case insensitive. It is optional and can have empty or "" value, in all these cases
prefix check will not be enforced.
-->
<prefix>rack</prefix>
<!-- The default cost of this layer, an positive integer or 0. Can be override by the
"${cost}" value in specific path. This field is also optional. When it's not defined,
it's value is default "1".
-->
<cost>1</cost>
<!-- Layer type, optional field, case insensitive, default value InnerNode.
Current value range : {Root, InnerNode, Leaf}
Leaf node can only appear in the end of the "path" field of the "topology" section.
Root node is a special node. It doesn't have name. It's represented by "/" at the beginning of the path.
-->
<type>InnerNode</type>
<!-- default name if this layer is missed. Only apply to InnerNode. Ignored for Leaf node and Root. -->
<default>/default-rack</default>
</layer>
<layer id="node">
<prefix></prefix>
<cost>0</cost>
<type>Leaf</type>
</layer>
</layer>
</layers>
<topology>
<path>/datacenter/rack/node</path>
<!-- When this field is true, each InnerNode layer should has its prefix defined with not empty value,
otherwise the content is not valid. Default value is false.
-->
<enforceprefix>false</enforceprefix>
</topology>
</configuration>
在这个XML配置文件中,定义了网络拓扑结构的总层数,每层的信息,包括类型,网络默认COST,缺省名字,是否有强制的Prefix等。
如果用户想要启用一个新的网络拓扑结构,准备好一个对应的XML配置文件,放置在etc/hadoop目录下,然后修改“ozone.scm.network.topology.schema.file” 配置项,指向该XML文件。当然新的网络拓扑结构,必然需要配套新的备份选择策略,这个由“ozone.scm.container.placement.impl” 配置项来控制。
结束语
虽然在计算存储分离的构架下,大家已经不再强调网络拓扑结构带来的“数据本地性”读的优势。但是其实,网路拓扑结构最首要的功能是保证数据的可靠性,使得数据能够承受不同级别的硬件故障后,仍然是完整可靠的,同时通过网络拓扑的信息,兼顾优化数据的写入性能。所以网络拓扑结构信息,仍然还是分布式存储系统一个不可或缺的重要部分。
欢迎阅读其他Ozone系列文章

腾讯大数据诚招计算、存储、消息中间件、调度、中台等各方向的大数据研发工程师,请私信或联系jerryshao@tencent.com。
