一.概述
Rancher 是为使用容器的公司打造的容器管理平台。Rancher 简化了使用Kubernetes 的流程,开发者可以随处运行 Kubernetes(Run Kubernetes Everywhere),满足 IT 需求规范,赋能 DevOps 团队。Rancher 1.x 最初是为了支持多种容器编排引擎而构建的,其中包括自己的容器编排引擎 Cattle。但随着 Kubernetes 在市场上的兴起,Rancher 2.x 已经完全转向了 Kubernetes。Rancher 2.x 可以部署和管理在任何地方运行的 Kubernetes 集群。
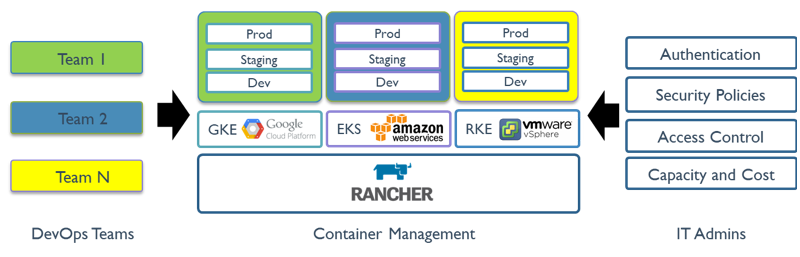
二.架构
Rancher Server 由认证代理(Authentication Proxy)、Rancher API Server、集群控制器(Cluster Controller)、etcd 节点和集群 Agent(Cluster Agent) 组成。除了集群 Agent 以外,其他组件都部署在 Rancher Server 中。
简单的理解就是rancher分为server端和agent端。
三.基础概念
Docker 是容器打包和运行时系统的标准,主要用于管理各个节点上的容器。开发者在 Dockerfiles 中构建容器镜像,上传到镜像仓库中,用户只需从镜像仓库下载该镜像文件,就可以开始使用。
Kubernetes 是容器和集群管理的标准。YAML 文件规定了组成一个应用所需的容器和其他资源。Kubernetes 提供了调度、伸缩、服务发现、健康检查、密文管理和配置管理等功能
Kubernetes 集群 是由多个计算机(可以是物理机、云主机或虚拟机)组成的一个独立系统,通过 Kubernetes 容器管理系统,实现部署、运维和伸缩 Docker 容器等功能,它允许您的组织对应用进行自动化运维。
etcd 节点 的主要功能是数据存储,它负责存储 Rancher Server 的数据和集群状态。Kubernetes 集群的状态保存在etcd 节点 中,etcd 节点运行 etcd 数据库。etcd 数据库组件是一个分布式的键值对存储系统,用于存储 Kubernetes 的集群数据,例如集群协作相关和集群状态相关的数据。建议在多个节点上运行 etcd,保证在节点失效的情况下,可以获取到备份的集群数据
Controlplane 节点上运行的工作负载包括:Kubernetes API server、scheduler 和 controller mananger。这些节点负载执行日常任务,从而确保您的集群状态和您的集群配置相匹配。因为 etcd 节点保存了集群的全部数据,所以 Controlplane 节点是无状态的。虽然您可以在单个节点上运行 Controlplane,但是我们建议在两个或以上的节点上运行 Controlplane,以保证冗余性。另外,因为 Kubernetes 只要求每个节点至少要分配一个角色,所以一个节点可以既是 Controlplane 节点,又是 etcd 节点。
worker 节点运行以下应用:
Kubelet: 监控节点状态的 Agent,确保您的容器处于健康状态。
工作负载: 承载您的应用和其他类型的部署的容器和 Pod。
Worker 节点也运行存储和网络驱动;有必要时也会运行应用路由控制器(Ingress Controller)。Rancher 对 Worker 节点的数量没有限制,您可以按照实际需要创建多个 Worker 节点。
Helm 是 Kubernetes 的软件包管理工具。Helm chart 为 Kubernetes YAML manifest 文件提供了模板语法。通过 Helm,可以创建可配置的 Deployment YAML,而不是只能用静态的 YAML。
四.Rancher的安装与应用
以下是以RKE(Rancher Kubernetes Engine)方式部署k8s集群,当然rancher也可以接管其他已经存在的k8s集群。部署之前需要提前安装docker环境。
运行rancher
# docker run -d --restart=unless-stopped -p 80:80 -p 443:443 rancher/rancher

访问rancher
创建集群
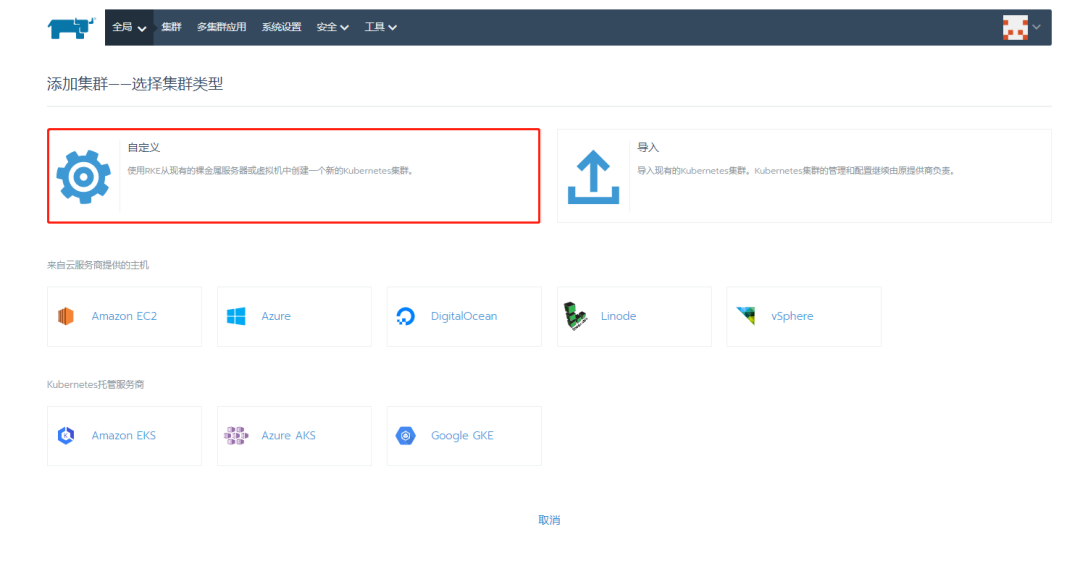
Custom方式安装k8s(这里用的就是RKE,RKE也可以通过配置文件的方安装k8s)
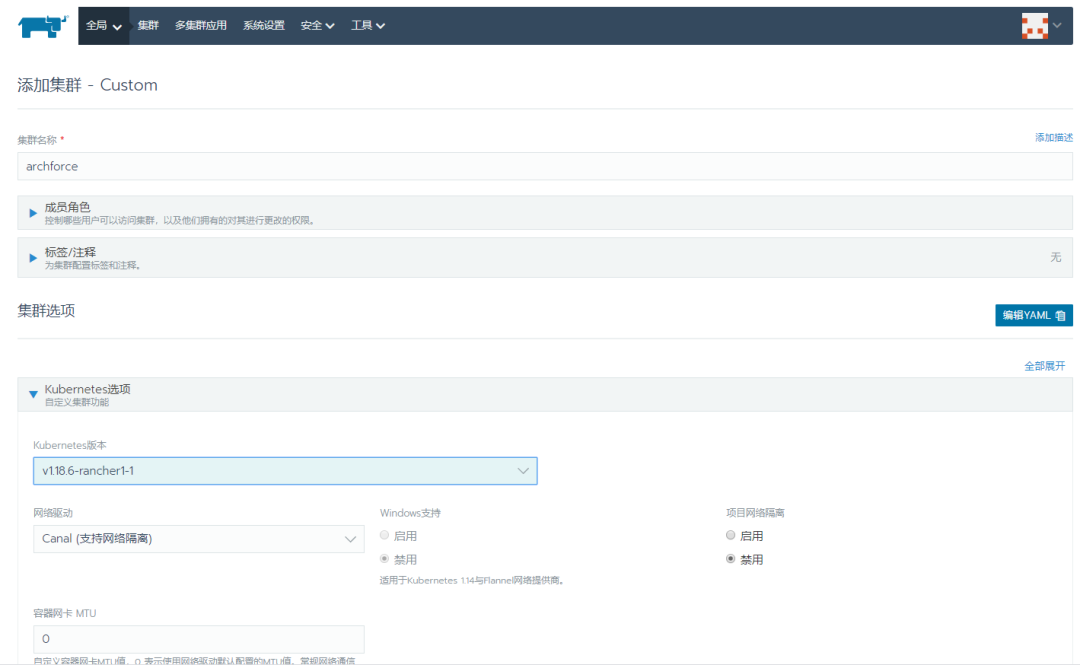
以下为集群选项yaml配置文件,只要用于一些特殊需求场景,简单部署无需理会即可。
#
# Cluster Config
#
docker_root_dir: /var/lib/docker
enable_cluster_alerting: false
enable_cluster_monitoring: false
enable_network_policy: false
local_cluster_auth_endpoint:
enabled: true
name: archforce
#
# Rancher Config
#
rancher_kubernetes_engine_config:
addon_job_timeout: 30
authentication:
strategy: x509
dns:
nodelocal:
ip_address: ''
node_selector: null
update_strategy: {}
ignore_docker_version: true
#
# # 当前仅支持nginx的ingress
# # 设置`provider: none`禁用ingress控制器
# # 通过node_selector可以指定在某些节点上运行ingress控制器,例如:
# provider: nginx
# node_selector:
# app: ingress
#
ingress:
provider: nginx
kubernetes_version: v1.18.6-rancher1-1
monitoring:
provider: metrics-server
replicas: 1
#
# # 如果您在AWS上使用calico
#
# network:
# plugin: calico
# calico_network_provider:
# cloud_provider: aws
#
# # 指定flannel网络接口
#
# network:
# plugin: flannel
# flannel_network_provider:
# iface: eth1
#
# # 指定canal网络插件的flannel网络接口
#
# network:
# plugin: canal
# canal_network_provider:
# iface: eth1
#
network:
mtu: 0
options:
flannel_backend_type: vxlan
plugin: canal
#
# # 自定义服务参数,仅适用于Linux环境
# services:
# kube-api:
# service_cluster_ip_range: 10.43.0.0/16
# extra_args:
# watch-cache: true
# kube-controller:
# cluster_cidr: 10.42.0.0/16
# service_cluster_ip_range: 10.43.0.0/16
# extra_args:
# # 修改每个节点子网大小(cidr掩码长度),默认为24,可用IP为254个;23,可用IP为510个;22,可用IP为1022个;
# node-cidr-mask-size: 24
# # 控制器定时与节点通信以检查通信是否正常,周期默认5s
# node-monitor-period: '5s'
# # 当节点通信失败后,再等一段时间kubernetes判定节点为notready状态。这个时间段必须是kubelet的nodeStatusUpdateFrequency(默认10s)的N倍,其中N表示允许kubelet同步节点状态的重试次数,默认40s。
# node-monitor-grace-period: '20s'
# # 再持续通信失败一段时间后,kubernetes判定节点为unhealthy状态,默认1m0s。
# node-startup-grace-period: '30s'
# # 再持续失联一段时间,kubernetes开始迁移失联节点的Pod,默认5m0s。
# pod-eviction-timeout: '1m'
# kubelet:
# cluster_domain: cluster.local
# cluster_dns_server: 10.43.0.10
# # 扩展变量
# extra_args:
# # 与apiserver会话时的并发数,默认是10
# kube-api-burst: '30'
# # 与apiserver会话时的 QPS,默认是5
# kube-api-qps: '15'
# # 修改节点最大Pod数量
# max-pods: '250'
# # secrets和configmaps同步到Pod需要的时间,默认一分钟
# sync-frequency: '3s'
# # kubelet默认一次拉取一个镜像,设置为false可以同时拉取多个镜像,前提是存储驱动要为overlay2,对应的Docker也需要增加下载并发数
# serialize-image-pulls: false
# # 拉取镜像的最大并发数,registry-burst不能超过registry-qps ,仅当registry-qps大于0(零)时生效,(默认10)。如果registry-qps为0则不限制(默认5)。
# registry-burst: '10'
# registry-qps: '0'
# # 以下配置用于配置节点资源预留和限制
# cgroups-per-qos: 'true'
# cgroup-driver: cgroupfs
# # 以下两个参数指明为相关服务预留多少资源,仅用于调度,不做实际限制
# system-reserved: 'memory=300Mi'
# kube-reserved: 'memory=2Gi'
# enforce-node-allocatable: 'pods'
# # 硬驱逐阈值,当节点上的可用资源少于这个值时,就会触发强制驱逐。强制驱逐会强制kill掉POD,不会等POD自动退出。
# eviction-hard: 'memory.available<300mi,nodefs.available<10%,imagefs.available<15%,nodefs.inodesfree<5%'
# # 软驱逐阈值
# ## 以下四个参数配套使用,当节点上的可用资源少于这个值时但大于硬驱逐阈值时候,会等待eviction-soft-grace-period设置的时长;
# ## 等待中每10s检查一次,当最后一次检查还触发了软驱逐阈值就会开始驱逐,驱逐不会直接Kill POD,先发送停止信号给POD,然后等待eviction-max-pod-grace-period设置的时长;
# ## 在eviction-max-pod-grace-period时长之后,如果POD还未退出则发送强制kill POD
# eviction-soft: 'memory.available<500mi,nodefs.available<50%,imagefs.available<50%,nodefs.inodesfree<10%'
# eviction-soft-grace-period: 'memory.available=1m30s'
# eviction-max-pod-grace-period: '30'
# ## 当处于驱逐状态的节点不可调度,当节点恢复正常状态后
# eviction-pressure-transition-period: '5m0s'
# extra_binds:
# - "/usr/libexec/kubernetes/kubelet-plugins:/usr/libexec/kubernetes/kubelet-plugins"
# - "/etc/iscsi:/etc/iscsi"
# - "/sbin/iscsiadm:/sbin/iscsiadm"
# etcd:
# # 修改空间配额为$((4*1024*1024*1024)),默认2G,最大8G
# extra_args:
# quota-backend-bytes: '4294967296'
# auto-compaction-retention: 240 #(单位小时)
# kubeproxy:
# extra_args:
# # 默认使用iptables进行数据转发
# proxy-mode: "" # 如果要启用ipvs,则此处设置为`ipvs`
#
services:
etcd:
backup_config:
enabled: true
interval_hours: 12
retention: 6
safe_timestamp: false
creation: 12h
extra_args:
election-timeout: 5000
heartbeat-interval: 500
gid: 0
retention: 72h
snapshot: false
uid: 0
kube_api:
always_pull_images: false
pod_security_policy: false
service_node_port_range: 30000-32767
ssh_agent_auth: false
upgrade_strategy:
drain: false
max_unavailable_controlplane: '1'
max_unavailable_worker: 10%
node_drain_input:
delete_local_data: false
force: false
grace_period: -1
ignore_daemon_sets: true
timeout: 120
windows_prefered_cluster: false
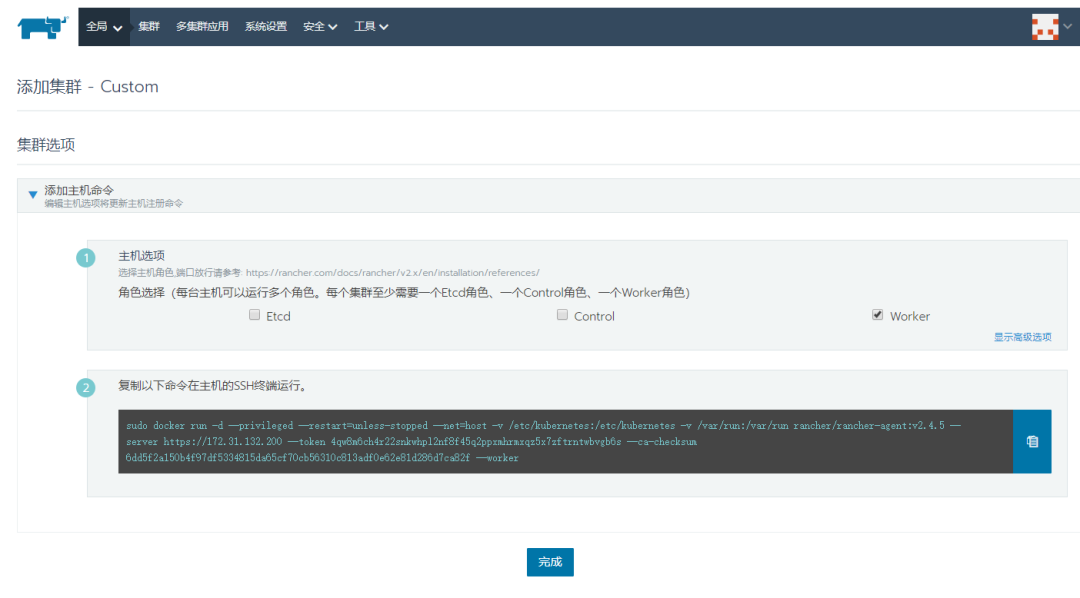
(把这段命令复制到虚拟机或者物理机节点上即可,它会实现自动安装k8s集群,注意勾选不同的角色)
sudo docker run -d --privileged --restart=unless-stopped --net=host -v /etc/kubernetes:/etc/kubernetes -v /var/run:/var/run rancher/rancher-agent:v2.4.5 --server https://172.31.132.200 --token 4qw8m6ch4r22snkwhpl2nf8f45q2ppxmhrmxqz5x7zftrntwbvgb6s --ca-checksum 6dd5f2a150b4f97df5334815da65cf70cb56310c813adf0e62e81d286d7ca82f --etcd --controlplane --worker
这里k8s集群已经部署完毕,通过图形化界面也可以部署应用,用户也可以直接控制k8s集群。如果节点网络状态很好的话,安装一个k8s集群只要几分钟即可,极大地简化了部署过程。
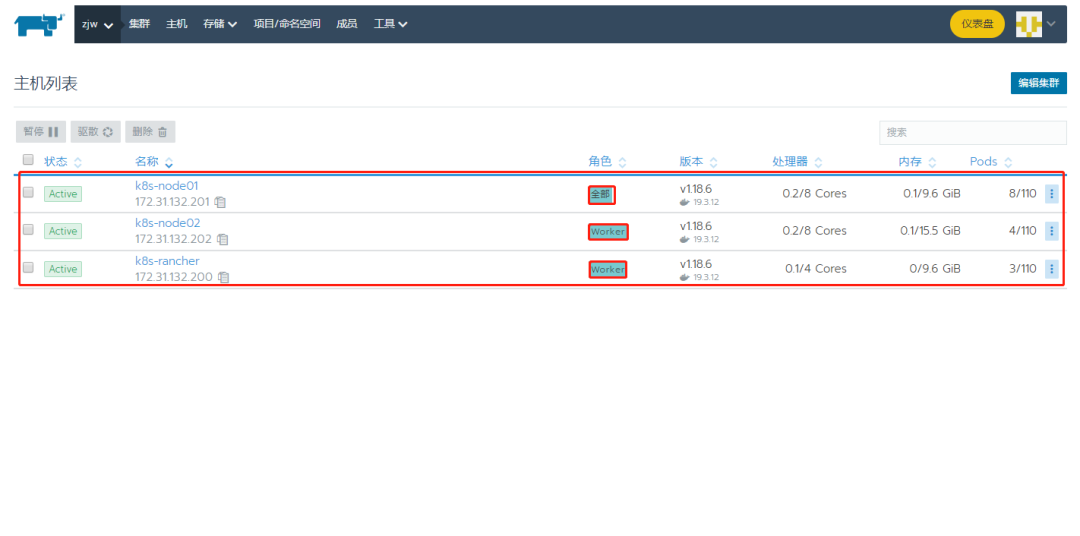
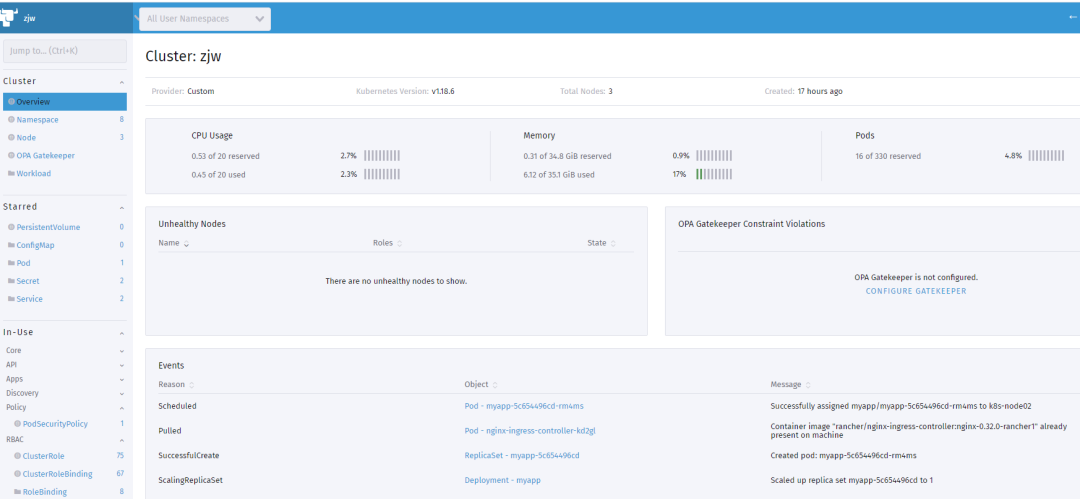
自带的仪表盘: