




一、背景说明
在特定的业务场景,需要推送特定的购买了产品 A 和产品 B 却没有购买产品 C 的顾客。需要编写一个解决方案,找出符合条件的所有人员。以任意的顺序返回结果表。 在实现的过程中,会发现很多效率问题,通过本案例,也进行在梧桐数据库下两种查询方式效率的分析说明。
二、表结构说明
数据库建表语句
1.简单的Customers表:
CREATE TABLE Customers (
customer_id INT NOT NULL,
customer_name VARCHAR(255) NOT NULL,
PRIMARY KEY (customer_id)
);
customer_id 是这张表中具有唯一值的列。 customer_name 是顾客的名称。
2.简单的orders表:
CREATE TABLE Orders (
order_id INT NOT NULL,
customer_id INT NOT NULL,
product_name VARCHAR(255) NOT NULL,
PRIMARY KEY (order_id),
FOREIGN KEY (customer_id) REFERENCES Customers(customer_id)
);
order_id 是这张表中具有唯一值的列。 customer_id 是购买了名为 "product_name" 产品顾客的id。
三、表数据插入
Customers 表插入语句
INSERT INTO Customers (customer_id, customer_name) VALUES
(1, 'Daniel'),
(2, 'Diana'),
(3, 'Elizabeth'),
(4, 'Jhon');
Orders 表插入语句
INSERT INTO Orders (order_id, customer_id, product_name) VALUES
(10, 1, 'A'),
(20, 1, 'B'),
(30, 1, 'D'),
(40, 1, 'C'),
(50, 2, 'A'),
(60, 3, 'A'),
(70, 3, 'B'),
(80, 3, 'D'),
(90, 4, 'C');
四、sql实现的两种方式
1.理解简单的方法
SELECT
customer_id,
customer_name
FROM
customers
WHERE
customer_id IN (
SELECT
customer_id
FROM
orders
WHERE
product_name = 'A')
AND customer_id IN (
SELECT
customer_id
FROM
orders
WHERE
product_name = 'B')
AND customer_id NOT IN (
SELECT
customer_id
FROM
orders
WHERE
product_name = 'C')
ORDER BY
customer_id;
结果截图:
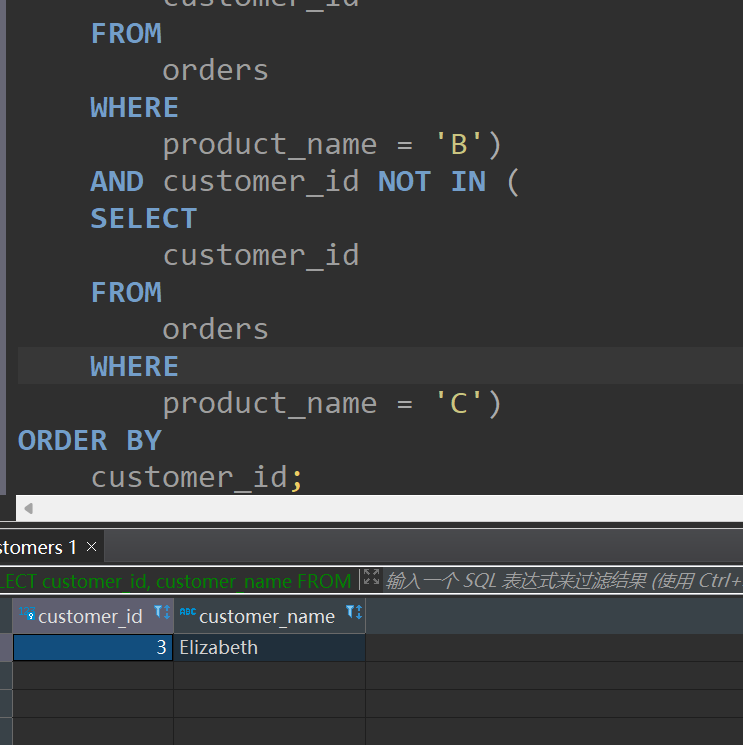
2.having 判断
SELECT
a.customer_id,
b.customer_name
FROM
orders a
LEFT JOIN customers b ON
a.customer_id = b.customer_id
GROUP BY
a.customer_id, b.customer_name
HAVING
SUM(CASE WHEN product_name = 'A' THEN 1 ELSE 0 END) *
SUM(CASE WHEN product_name = 'B' THEN 1 ELSE 0 END) > 0
AND SUM(CASE WHEN product_name = 'C' THEN 1 ELSE 0 END) = 0;
结果截图:
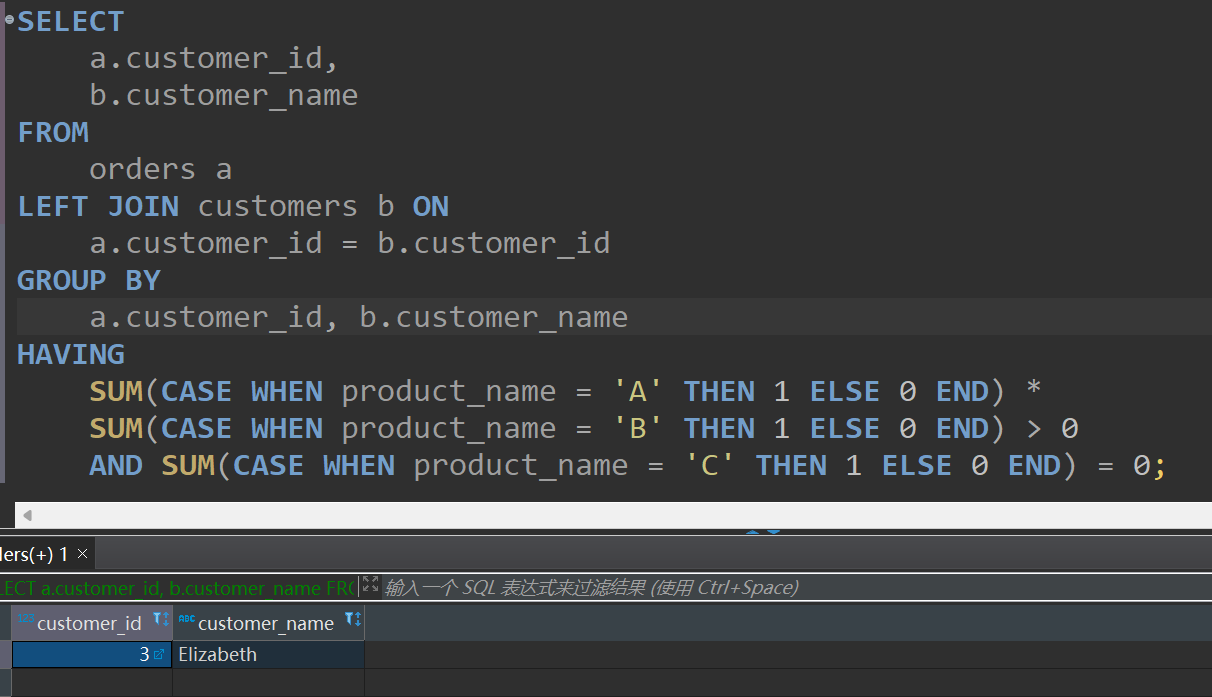
五、查询效率分析
在比较这两个SQL查询的效率时,需要考虑几个关键因素,包括数据库的大小、索引的使用、以及查询优化器的行为。然而,一般来说,对于大多数数据库管理系统(包括PostgreSQL),第二个查询(使用LEFT JOIN和GROUP BY的查询)在性能上可能不如第一个查询,尤其是在处理大量数据时。
第一个查询的效率:
第一个查询使用了子查询和IN操作符来筛选同时购买了产品A和B但没有购买产品C的顾客。这个查询的优点是它可以非常直接地利用索引(如果customer_id和product_name上有索引的话),因为它是在较小的结果集上独立地进行过滤。此外,数据库优化器可能能够更有效地处理这种类型的查询,因为它不需要对整个订单表进行分组和聚合操作。
第二个查询的效率:
第二个查询使用了LEFT JOIN来连接customers和orders表,并通过GROUP BY和HAVING子句来过滤结果。这个查询的优点是它在单个查询中完成了所有工作,但缺点也很明显:
- 全表扫描或大量分组:如果orders表很大,那么LEFT JOIN可能会导致对整个表进行扫描,并且GROUP BY子句可能会产生大量的分组(每个顾客一个分组),这会增加处理时间。
- 索引利用不足:虽然customer_id和product_name上的索引可能对JOIN操作有所帮助,但GROUP BY和HAVING子句中的条件可能无法像WHERE子句中的条件那样有效地利用索引。
- 计算开销:SUM(CASE ...)表达式在每组中都需要计算,这也会增加处理时间。
六、结论
在大多数情况下,特别是当orders表很大时,第一个查询(使用子查询和IN操作符)可能会更高效。然而,实际的性能差异将取决于多个因素,包括数据库的具体实现、索引的配置、以及查询优化器的行为。因此,最好的做法是在您自己的数据库环境中对这两个查询进行测试,以查看哪个查询在实际应用中表现更好。
另外,值得注意的是,随着数据库技术的不断发展,数据库优化器的能力也在不断提高。在某些情况下,数据库优化器可能会将第二个查询重写为类似于第一个查询的形式,或者通过其他方式优化查询计划以提高性能。但是,这并不能保证在所有情况下都会发生,因此始终建议进行实际的性能测试。
