




前不久,某国产数据库发布了一款《分布式事务型数据库金融应用指南》,该文档详细的描述了此数据库产品应用于金融业务领域在资源规划、应用开发、数据迁移、日常运维、数据库安全及性能调优等方面的注意事项。在阅读关于“如何进行数据均衡设计”章节时,我似乎终于明白分库分表数据库为什么使用起来如此复杂,以及我们到底需要一款什么样的分布式数据库产品。
一.某国产数据库如何进行数据均衡设计
以下内容均摘自《XX分布式事务型数据库金融应用指南》
数据均衡手段
业务大表建议采用分片表、分片+分区、多级分片的方式实现数据的均衡分布,分片策略支持:哈希、范围、列表,各分片上的数据量均衡,业务增长过程中数据变化也保持相对均衡,其中
1) 面向用户的主档表(客户、账号、用户)优先考虑用 HASH分发策略。分片键字段少的大表,采用 RANGE/LIST 分片策略,例如面向机构编码或
地市字段大表采用 LIST 分片策略。
2) 对包含日期的流水表,采用先分片再分区。
3) 每个分片的数据总量不超过 2~3TB,推荐不超过 2TB。
4) 单台服务器的数据总量不超过 6~9TB,推荐不超过 6TB。
5) 单个分片的表记录行总数不超过 1 亿条。
6) 单个分区的表记录行总数不超过 2 千万条。
7) 关联性强的表(比如 JOIN、批量迁移等)尽量采用相同的分片策略,例如客户的主档表和流水表,使用相同的分片策略,使得相同客户的多个表数据落在相同的分片上,减少跨分片关联。
8) 避免热点数据的过分集中,如果因为分发策略的原因导致热点数据,可通过增加分发字段的方式,使数据分布进一步细化,热点的判断可通过各个分片的各项指标综合判断。
9) 多级分片,实际使用中出于某些考虑,需要对数据进行复杂的分片。比如集团客户分在某个分片,非集团客户按照客户号 HASH 分片。
10)先分片再分区,对包含历史表等有日期字段的表,采用先分片再分区的策略。使用年份、月份等字段进行分区设计,将相同分片上的大表
按日期将数据分散到多个分区。
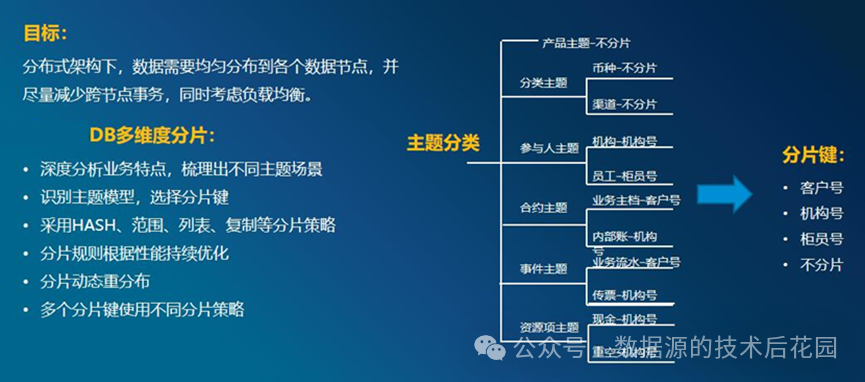
选择恰当的分片主题
为了快速和合理进行表分片设计,在启动分片设计之前,理清各实体之间的关系至关重要。从实体关系中提炼业务的分片主题,比如分为围绕用户(客户、账号、用户)、机构等相同分片主题的表,使用相同的分片策略,以及相同的分片字段作为分片键。将整个工程中分片主题控制在围绕其中一个主题为主,少量主题为辅助(3~5 个)的规模。
1) 分类主题,不分片。
2) 参与人主题,机构按照机构编号进行RANGE 分片,考虑到机构的规模进行合理的设计,保证各分片数据的均衡。员工按柜员号进行 HASH 或者 RANGE 分片。
3) 客户、账号、用户相关的表,可按照客户编号进行 HASH 或者 RANGE 分片。
4) 合约主题,业务主档按客户号进行HASH 或者 RANGE 分片。机构按照机构编号进行RANGE 分片。
5) 事件主题,业务流水按客户号进行HASH 或者 RANGE 分片。机构按照机构编号进行RANGE 分片。在分片基础上,可对事件发生的时间字段再进行分区。
6) 资源项主题,按按照机构编号进行RANGE 分片。
通过上述描述可以看出,在这样一个分布式数据库里面要想实现数据均衡设计是非常极其无比复杂的事情,而且是需要对业务模型非常极其无比熟悉才能完成的事情。这似乎已经完全颠覆我们对传统数据库的认知,难道数据库不是加点主键加点索引就搞定的事儿么?
二.我们需要什么样的分布式数据库
经常听到很多分布式数据库宣称自己是大号Oracle或大号MySQL,使用起来跟单机数据库没有区别,看完上面产品在数据均衡设计上的考虑后,恐怕我们要对这种宣传打一个大大的折扣。笔者个人的理解是,分布式数据库要真正使用起来像大号Oracle或大号MySQL的话,不单单要兼容Oracle或MySQL的语法,更重要的是让数据库自己完成 “分布式”
隐含的所有工作,比如分布式事务、分布式计算、分布式存储、计算及存储的自动均衡等。
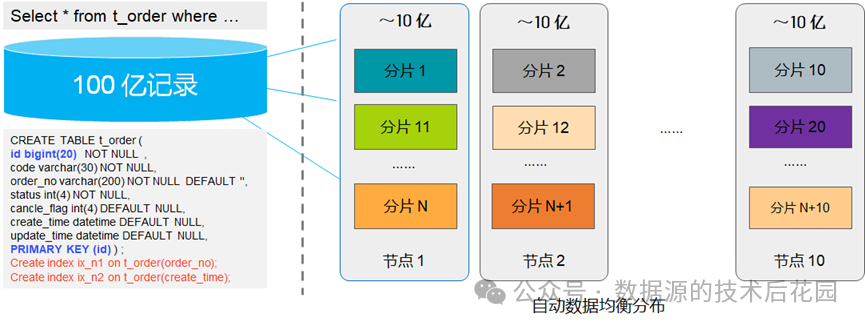
当数据库自己完成所有“分布式”工作后,我们就可以如上图所示一样使用单机库的语法创建表结构及索引(无须考虑分片键的设计)。当表的数据量超过一定大小后,数据库内部会将表自动切分成多个逻辑的数据分片,这些数据分片会进一步由数据库均匀打散到不同的数据节点。可以看出,在这样的分布式数据库中无论是数据的切分还是均衡分布,都由数据库内部的机制去完成,从根本上避免了上述分库分表数据库各种复杂的分片设计问题!
