




上一篇文章介绍了TiKV的具体细节及几种优化机制,了解到TiKV对读和写均做了相关的优化,TiKV中的Regions借助PD可以实现动态负载均衡、拆分与合并,从而实现更高的性能。本文重点介绍一下TiFlash。
前面的介绍中,我们已经学习到TiFlash是由Learner节点组成,Learner节点异步的接收Raft组的日志,并将行格式的元组转换为列数据。它们不参与Leader选举和仲裁,因此对TiKV的开销影响很小。在TiDB中,可以使用一条SQL命令为表增加列格式的副本(其中n代表副本的数量,缺省为1):
ALTER TABLE x SET TiFLASH REPLICA n; |
给表增加列副本就像增加异步列索引一样,TiFlash中的每个表被划分为多个分区,每个分区覆盖连续的行范围。在TiFlash实例初始化时,需要从相关的Leader复制数据到Learners,如果要快速同步大量数据,则Leader通过发送数据快照的方式到Learner。初始化完成后,TiFlash则实时监听Raft组的更新,并将日志应用到本地状态机。
一.日志重放
日志重放的目的就是TiFlash在接收到Raft组发送的日志后将日志进行相关的操作,最终变为列格式的数据存储在磁盘上。具体分为以下几个步骤:
(1)压缩日志。事务的日志分为预写、提交或回滚三种状态。回滚日志中的数据不需要写入磁盘,因此压缩进程会根据回滚日志删除无效的预写日志,将有效的日志放入缓冲区。
(2)解码元组。缓冲区中的日志被解码为行格式的元组,删除有关事务的冗余信息。然后将解码的元组放入行缓冲区中。
(3)转换数据格式。当行缓冲区中的数据超过大小限制或持续时间超过时间间隔限制,将这些行格式元组转换为列数据并写入本地分区数据池。转换引用本地缓存的模式,这些模式定期与TiKV同步。
日志重放及解码过程如下表所示:原始日志包含8个条目,它们试图插入两个元组、更新一个元组和删除一个元组。但插入k1会回滚,因此只保留8个日志项中的6个,从中解码三个元组。最后,将三个解码元组转换为5列:操作类型、提交时间戳、键和两列数据。列数据被追加到Delta Tree中。
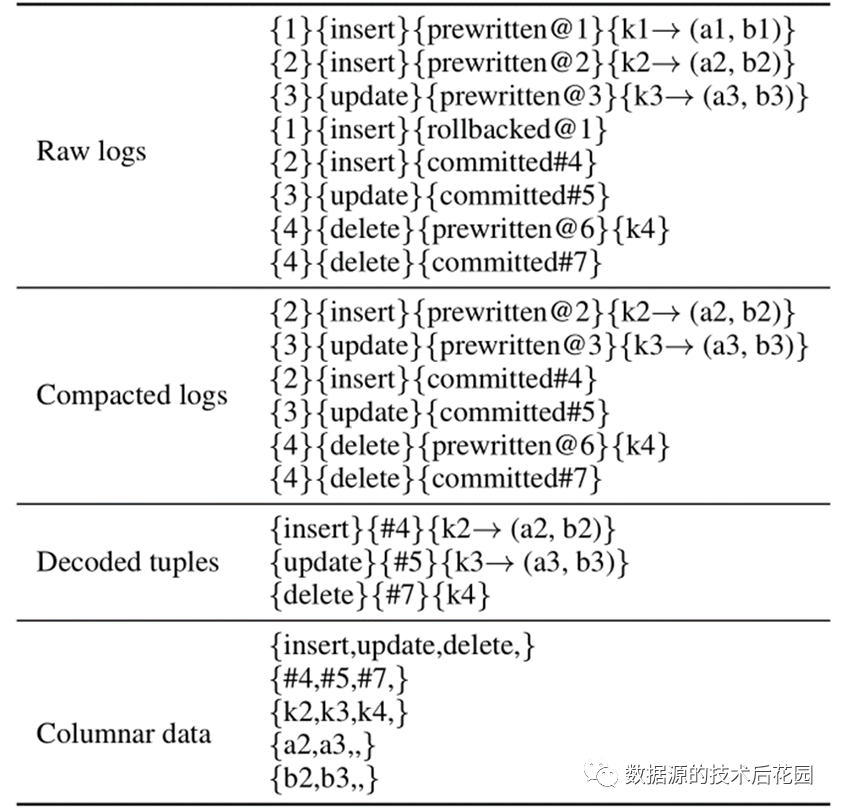 |
二.Delta
Tree
Delta Tree是一个列式存储引擎,它可以立即追加增量更新,然后将它们与每个分区之前的稳定版本合并。Delta Tree存储引擎主要有两部分空间:增量空间(Delta space)及稳定空间(Stable space)。在稳定空间中,分区数据以块(Chunk)的形式存储,每个块覆盖一个范围的数据,数据按列存储。相反,增量则按照TiKV生成它们的顺序直接追加到增量空间。TiFlash中的列存数据存储格式类似于Parquet,使用常见的LZ4压缩数据文件,以节省磁盘大小。
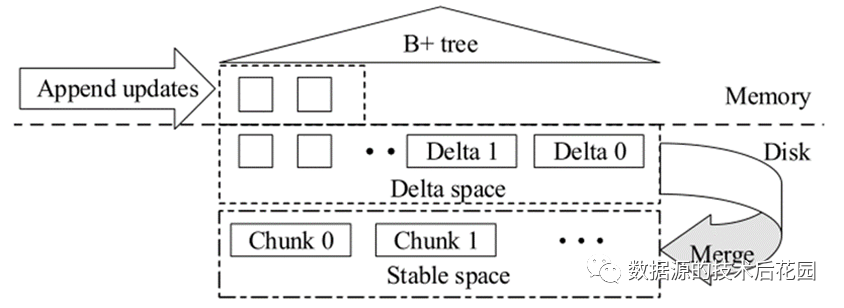 |
新写入的增量数据是插入或删除范围的原子批处理。这些增量缓存在内存中并物化到磁盘。增量按写入顺序存储,实现了WAL的功能。增量数据一般存储在许多小文件中,为了降低读取的IO成本,定期合并多个小的增量到一个较大增量并刷新到磁盘,然后删除之前小的增量。
读取数据时,可能需要将增量空间中的增量文件以及稳定空间中的稳定元组合并读取(即读放大)。此外,许多增量文件可能包含无用的数据(即空间放大),会浪费存储空间并降低与稳定元组的合并效率。
由于相关的键在增量空间中是无序的,合并增量代价较大,这种无序也减慢了增量与稳定块的合并读取。因此,在增量空间的顶部建立一个B+树索引,每个增量按键和时间戳顺序插入到B+树中,帮助读取时更快速查找到键,也使得增量与稳定块的合并更高效。
