




在第一篇文章中,笔者概括了TiDB这款数据库的设计初衷、HTAP主要解决的问题以及TiDB实现这样一款HTAP系统的精髓。本节我们进一步认识TiDB的整体架构,了解具体实现细节。
TiDB的整体架构可以划分为四大模块:客户端、计算引擎层、分布式存储层、Placement Driver(PD)。我们依次了解这几大模块的关键特性,
图-TiDB的架构 |
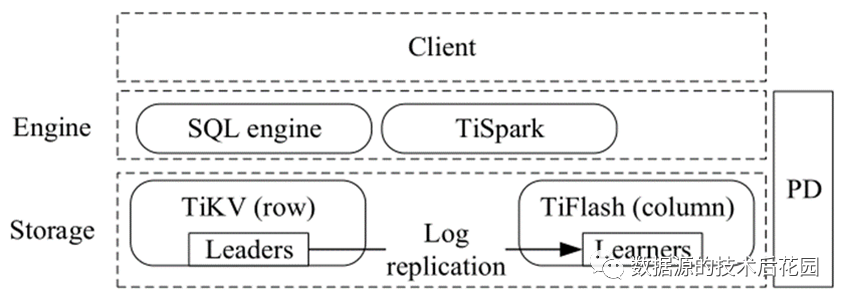
(1)客户端:TiDB兼容MySQL协议,可以被MySQL兼容的客户端访问。世面上有不少国产数据库也是以兼容MySQL为主,比如OceanBase、GBase 8a、Doris、Clickhouse等。
(2)计算引擎层:也称为TiDB,它是无状态的,可方便扩展。其主要工作就是将接收的客户端SQL请求进行查询解析并生成执行计划。在事务处理上,主要实现基于Percolator的两阶段提交协议(2PC)。内置的查询优化器可以自动选择从底层的TiKV存储还是TiFlash存储中获取数据以达到性能最优。为了集成Hadoop,还增加了TiSpark,它是一个优化的Spark组件。
(3)分布式存储层:包括行存储(TiKV)和列存储(TiFlash)两部分。TiKV中的数据是一个有序的键值映射,每条记录映射为一个键值对。键由表ID和行ID组成,值是实际的行数据,如下图所示:
Key:{table{tableID} record{rowID}} Value: {col0, col1, col2, col3} |
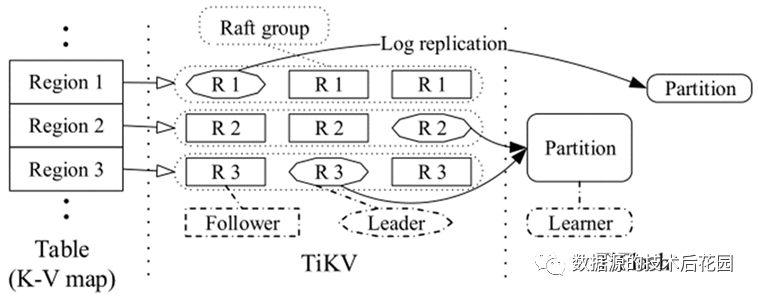
为了向外扩展,默认采用范围分区策略,将大的键值映射拆分为多个连续的范围(Region),每个Region有多个副本用于实现高可用性。每个Region及其副本组成一个Raft组。TiFlash的数据是异步复制于TiKV,并转储为列式存储。由于多个Raft组在分布式存储层中管理数据,因此我们称之为multi-Raft存储。
图-multi-Raft存储架构 |
(4)Placement Driver(PD):PD可以认为是集群的大脑,它的主要作用包括:管理Regions(提供Key所在的Region以及地理位置,对Region进行负载均衡等);提供全局时间戳(TSO)。为了实现高可用,PD包含多个PD成员。
实际上,TiDB的每个组件都设计为具有高可用性和可伸缩性。存储层,使用Raft算法来实现数据副本之间的一致性,TiKV和TiFlash之间的低延迟复制使分析查询可以获得新数据。查询优化器以及TiKV和TiFlash之间的强一致性数据提供了快速的分析查询处理,对事务处理影响较小。
