




人到中年,越来越发现一个道理,那就是人要不断的学习、不停的卷自己,才不至于被落后。35岁开始,加强两件事:读书和锻炼。读书可以丰富知识,锻炼可以强身健体。身体和灵魂,总有一个在路上!
最近在学习国产数据库TiDB,找到论文《TiDB:A
Raft-based HTAP Database》,通读了一遍,也算是对TiDB有了初步的了解。本篇就根据阅读理解谈谈自己的认知。
一.TiDB的设计初衷是什么?
换句话说,TiDB这款数据库主要是解决什么问题。简单理解TiDB是为了解决“one size fill all”这个问题。
最初的关系型数据库系统RDBMS因其关系模型、强大的事务保证和SQL接口而流行,它们在传统的业务系统中被广泛应用,但传统RDBMS无法提供可伸缩性和高可用性。21世纪初,互联网应用更喜欢NoSQL系统,如Google BigTable和DynamoDB等,NoSQL放宽了一致性要求,提供了高可伸缩性和可替代的数据模型,如键值对、图和文档。然而,许多应用程序还是需要强大的事务、数据一致性和SQL接口,因此又出现了NewSQL系统,比如CockroachDB和Google Spanner等。除此之外,联机分析处理(OLAP)也在迅速发展,比如诸多SQL-on-Hadoop系统如Hive、Impala或一些MPP数据库如Greenplum、Teradata等。
那么有没有一款数据库产品可以同时兼容NewSQL的特性,同时又能满足OLAP的需求呢?这就是TiDB的由来,其设计初衷是要做一款NewSQL+OLAP结合起来的HTAP数据库,产品理念是来自于NewSQL数据库。
二.HTAP系统需要解决什么问题?
为了更好的同时满足OLTP和OLAP业务,HTAP系统设计需要考虑两个重要的特性:新鲜度和隔离性。
新鲜度:通常是针对OLAP来说的,即怎么保证OLAP业务处理的数据是最新的。如今,实时分析最新数据会产生巨大的商业价值。以前我们通过提取-转换-加载(ETL)工具如Kettle、DataX等将OLTP中的数据定期刷新到OLAP系统的方案,存在较大的延迟,通常耗时数小时或数天。后来有了流式传输方案如Flink、Kafka,减少了同步时间,但这种方案仍然缺乏全局的数据治理模型,与多个系统接口带来额外的开销。
隔离性:指为单独的OLTP和OLAP查询保证隔离的性能。虽然业内也有一些HTAP的数据库,比如SAP HANA、Greenplum等,数据都是部署在相同的服务器上的(可能是不同的存储引擎,比如Greenplum中使用heap表来满足OLTP,使用AO表来满足OLAP),尽管能提供最新的数据,但是不能同时实现OLTP和OLAP的高性能。如果能在不同的硬件资源上分别运行OLTP和OLAP,就能很好的隔离开两种业务的相互影响。
三.TiDB是怎么解决上述问题的?
从论文的标题我们也可以看出,TiDB实现HTAP能力的根基在于Raft。大家知道,Paxos和Raft是两种最有名的共识算法,Raft算法易于理解和工程实现,因此TiDB选择了Raft。关于Raft本身的概念和原理,笔者在此不做过多说明(分享一张之前整理的PPT)。
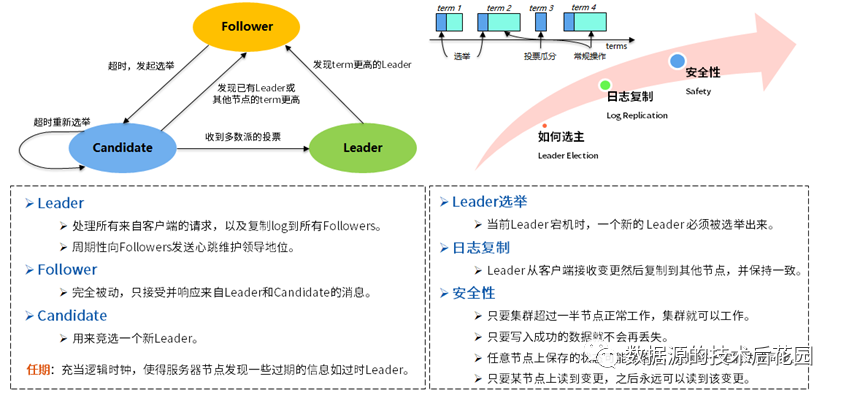 |
那么TiDB到底在Raft上面做了什么,使得它可以满足HTAP能力呢?简单理解就是:增加Learner角色,Learner异步从Leader同步日志,不参与选举,Learner采用列式存储。
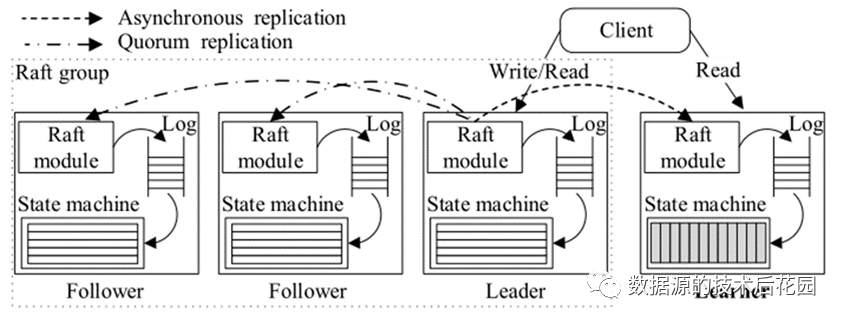 |
显而易见,这种实现方式有多方面好处。首先,Learner是从Leader异步同步日志,这种方法开销低,并且保持数据一致性。其次,复制到Learner的数据被转换为列式存储,列式存储可以更高效的处理OLAP(OLTP业务仍然采用行式存储)。通过把Learner部署在单独的硬件资源上,就能很好的隔离OLTP和OLAP业务了。除此之外,TiDB还实现了多项优化,比如如何在行存和列存中自动选择一个最优的执行计划等。后续,我们再深入探讨TiDB的具体架构及实现细节~
