




Tips:一些记录,一些笔记

2024/2/15
THURSDAY
Only endowed me with talents for eventual use.
天生我才必有用。

01
AnimateDiff
AnimateDiff的官方网站:https://animatediff.github.io/
AnimateDiff的官方代码库:https://github.com/guoyww/AnimateDiff
AnimateDiff的WebUI插件的官方代码库:https://github.com/continue-revolution/sd-webui-animatediff
通过AnimateDiff以及一些控制插件,我们可以创作出类似如下视频这样的画面稳定,且一致性不错的作品:
本文会详细拆解如何通过「Stable Diffusion」生成这样的视频的细节。
本文会介绍以下几种增加动效的方式:
AnimateDiff + Prompt Travel
AnimateDiff + ControlNet
02
「AnimateDiff」插件的安装
如果你和我一样,使用的事「秋叶」大佬的启动器,那么就可以按照下图所示的位置,在启动器的扩展管理的「安装新扩展」中,直接搜索并安装「AnimateDiff」:

然后,启动WebUI:
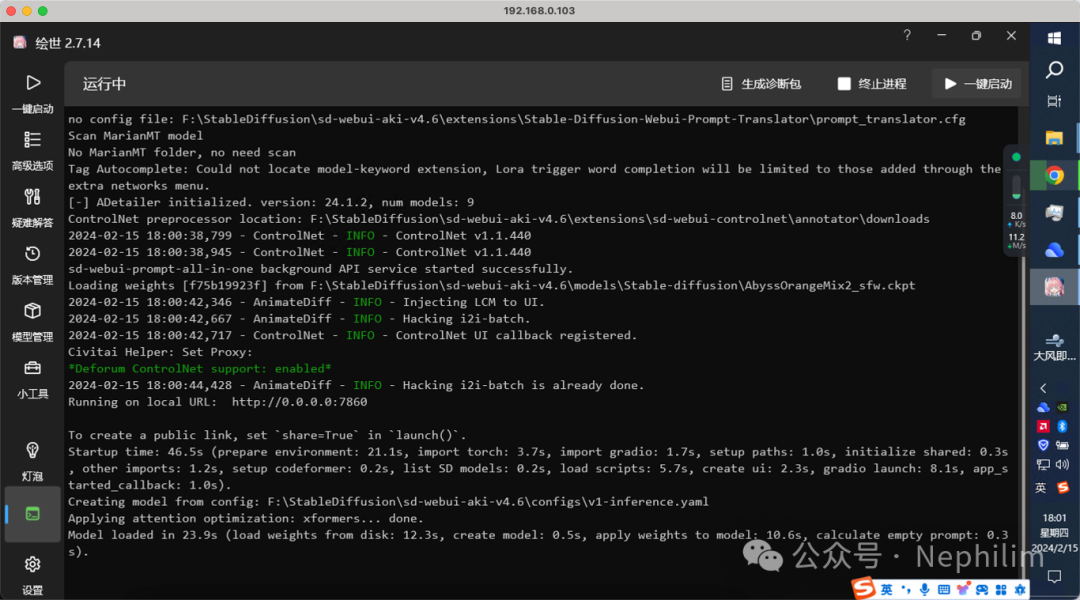
然后,就可以在「文生图 图生图」中找到「AnimateDiff」的对应操作面板:
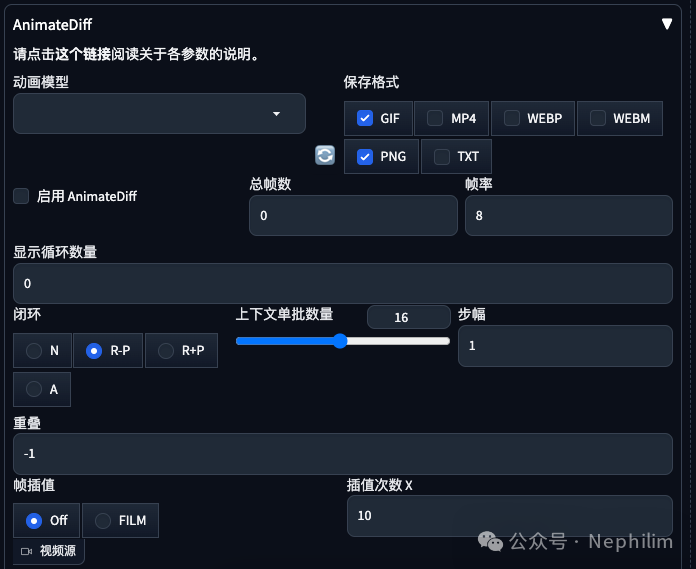
03
Prompt Travel
从官方代码库的介绍中可以看到,目前AnimateDiff已经集成了Prompt Travel,不需要再手动安装该插件就可以直接使用了,使用方式「只需要正确书写提示词的格式,即可触发」:
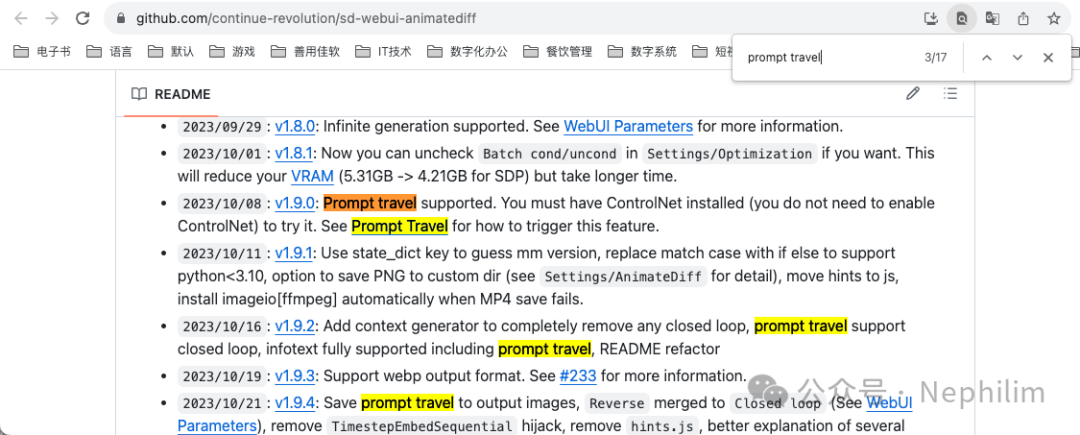
04
Motion Modules(运动模型)
AnimateDiff的运动模型需要到「Hugging Face」上下载;
它的官方项目地址是:https://huggingface.co/conrevo/AnimateDiff-A1111/tree/main
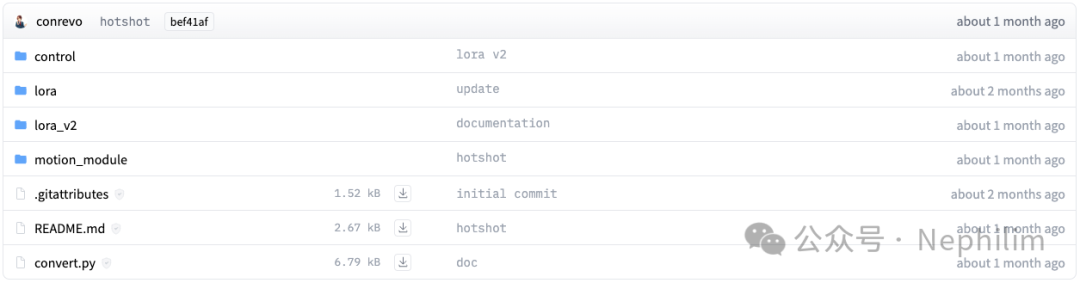
运动模型(Motion Modules):https://huggingface.co/conrevo/AnimateDiff-A1111/tree/main/motion_module
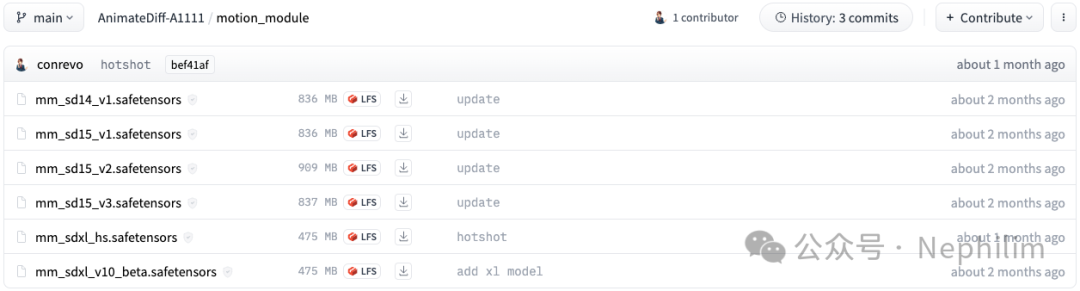
这里,建议下载「v2 v3」的模型,并且需要注意,不同的模型训练出来的底模(Base Module)是不一样的:
Stable Diffusion 1.4
Stable Diffusion 1.5
Stable Diffusion XL
如果要跑SDXL,对于机器的硬件性能要求会很高,根据自身情况,酌情选择;
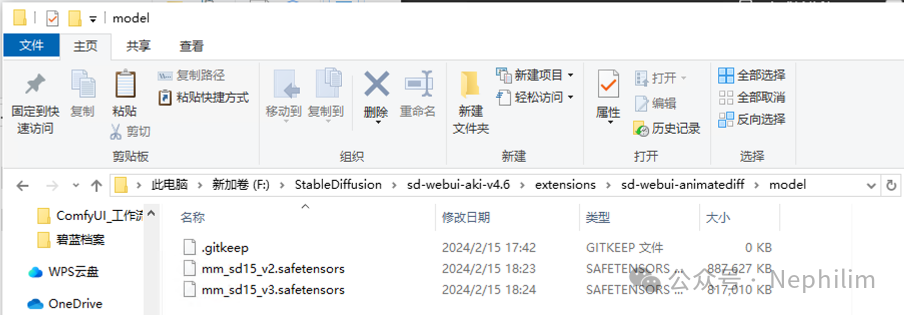
将它们下载好了以后,放在一下目录中:
<stable-diffusion-webui>/extensions/sd-webui-animatediff/model复制
如下所示:
05
镜头运动模型(LoRA)
官方仅提供八种运动方式:
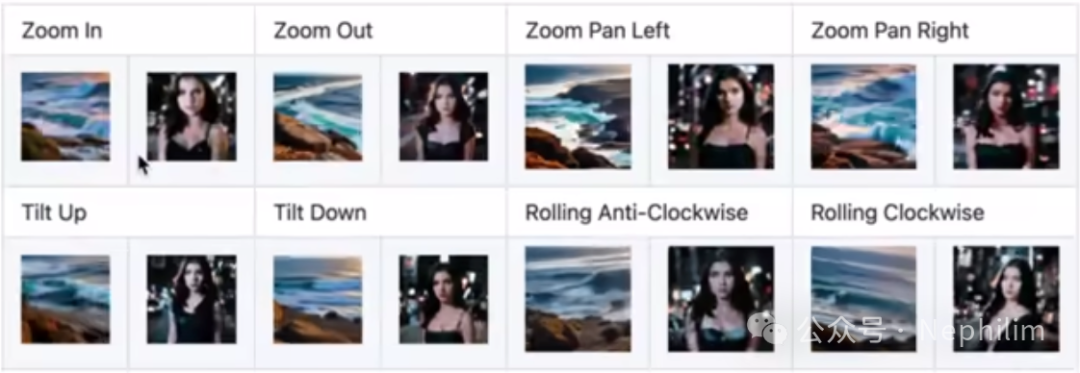
地址:
https://huggingface.co/conrevo/AnimateDiff-A1111/tree/main/lora_v2
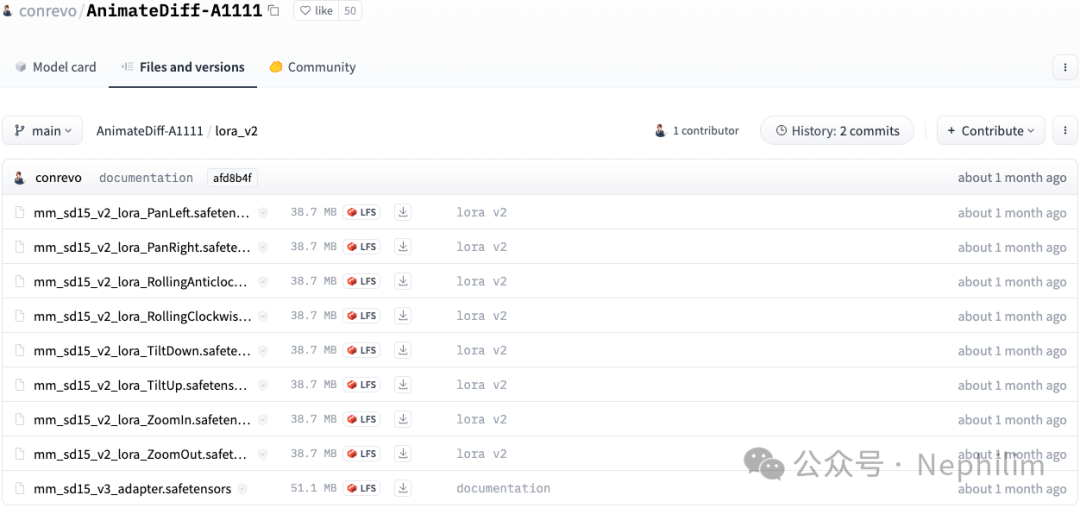
将它们下载后,存放在以下目录中:
<stable-diffusion-webui>/models/Lora复制
如下所示:
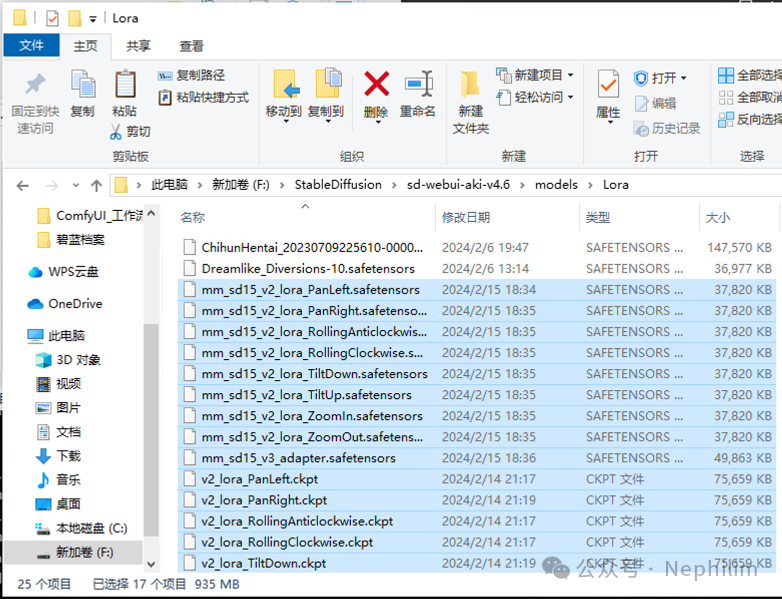
这些LoRA和普通的LoRA的使用方法一样,在提示词中调用即可。
06
WebUI与ControlNet「版本」
官方文档中对于版本的要求:

可以看到:
WebUI 1.6.0
ControlNet 1.1.410
WebUI的版本信息,可以在页面的最底下看到:

ControlNet的版本信息:方法一
在「文生图 图生图」面板上可以看到ControlNet的版本信息:

ControlNet的版本信息:方法二
在运行WebUI的命令行窗口中查看:
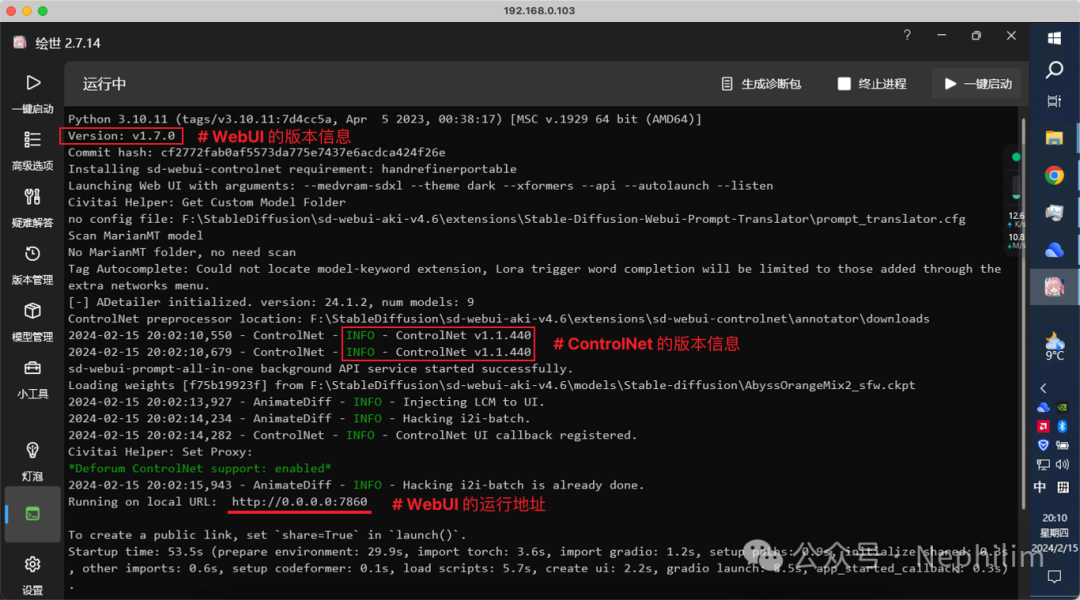
ControlNet的版本信息:方法三
进入「扩展 已安装」
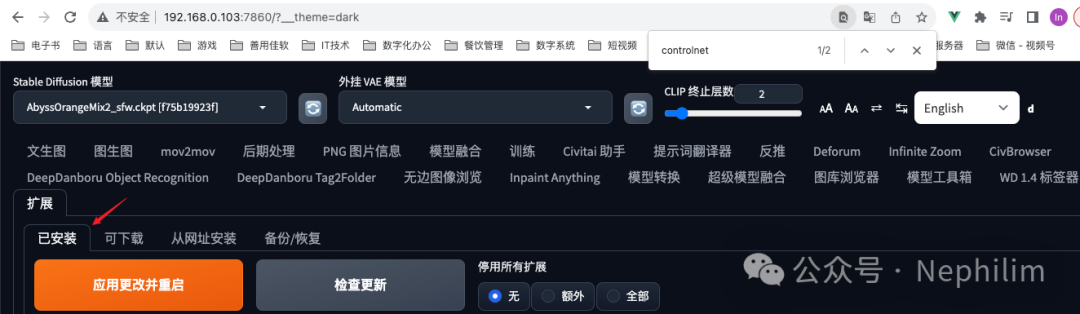
找到安装的「sd-webui-controlnet」
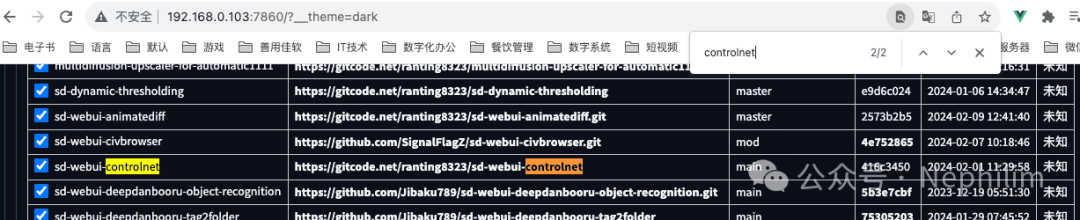
可以看到后面的版本信息是「416c3450」
点击进去,可以访问到它的代码托管网站:https://gitcode.net/ranting8323/sd-webui-controlnet
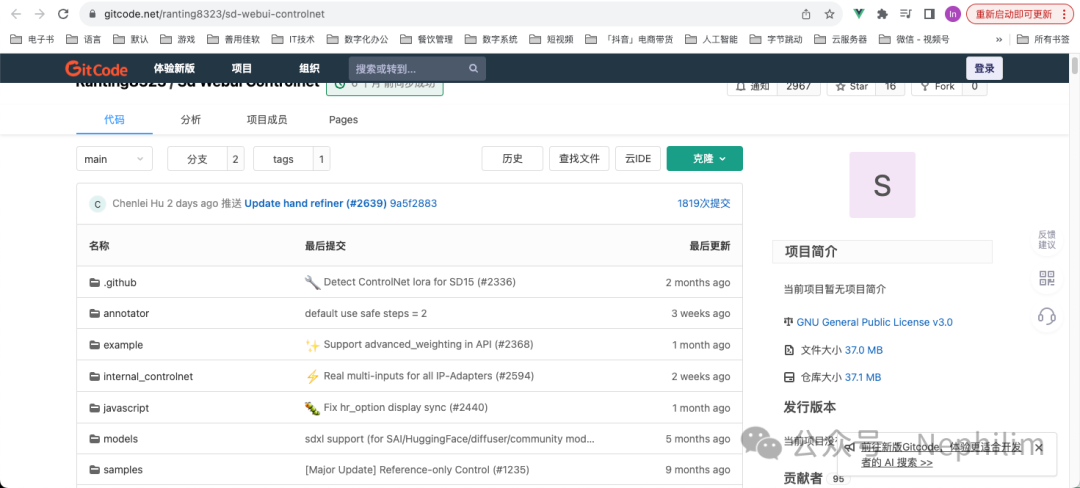
检索版本信息的代号:
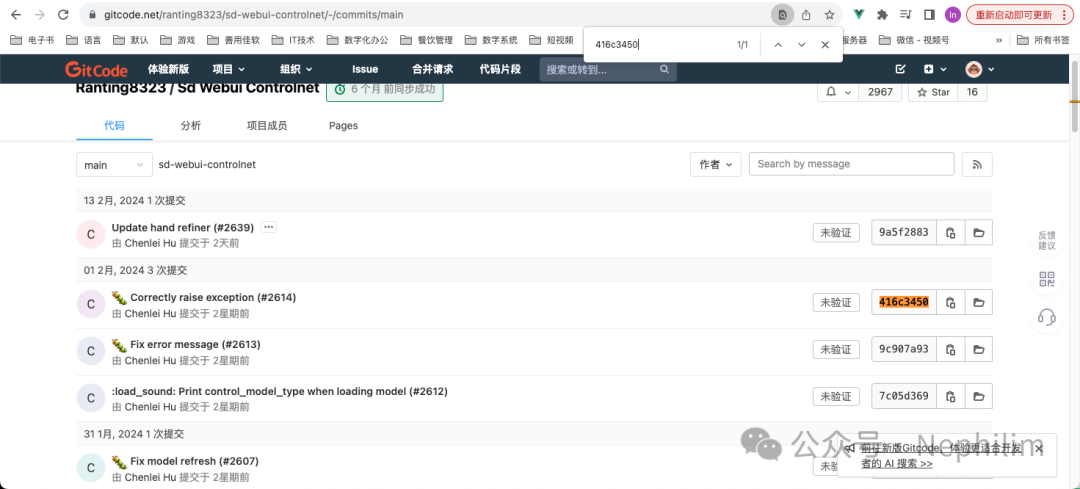
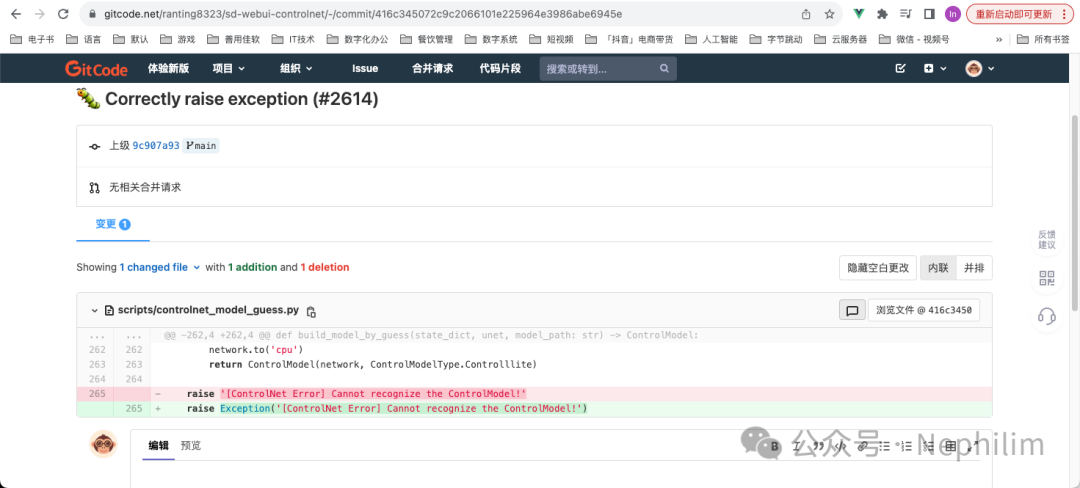
07
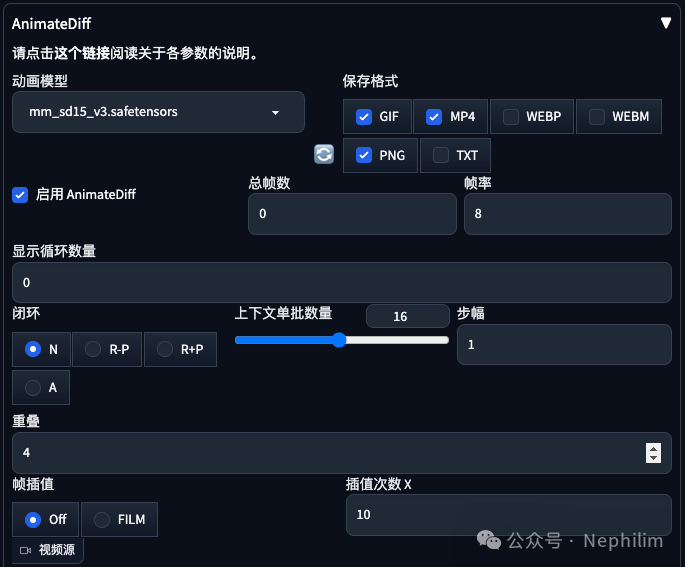
AnimateDiff「参数详解」
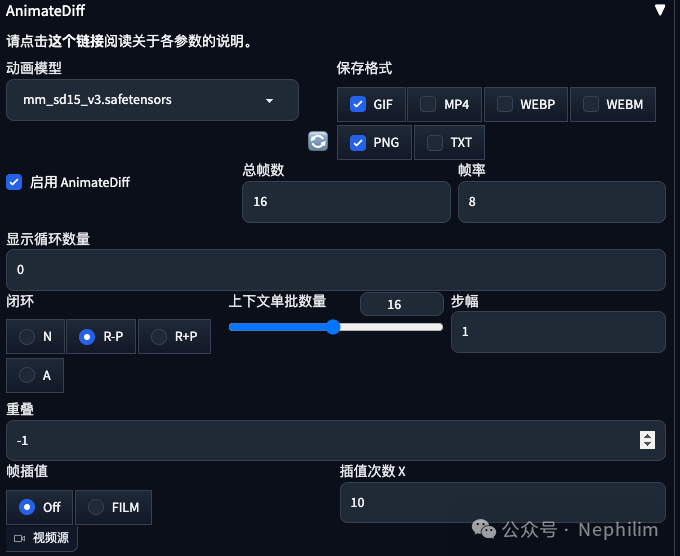
一、动画模型的选择
前面的安装步骤中,我们将下载的「运动模型」存放到了对应「扩展」的子目录「model」中,这部分,在前端WebUI的页面中就可以看到:
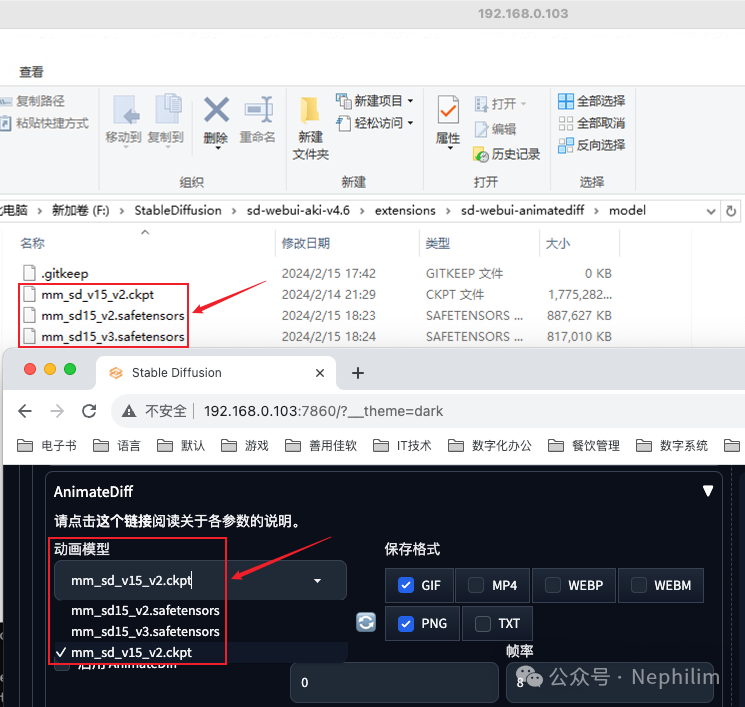
大多数情况下,相同的设置,V2最终的效果要好于V3,因此,我们选择V3版本的动画模型。
但是,如果要搭配镜头运动的LoRA的时候,只能使用V2模型。
二、保存格式

保存格式有六个选项:
效果输出预览:GIF、MP4
精度更好、无压缩的成品动画:PNG
三、总帧数(Number of frames)与帧率(FPS)

总帧数:动画长度
帧率:播放速率
最终的动画播放时间 = 总帧数 帧率
四、显示循环数量(Display loop number)
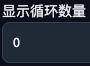
默认为「0」,表示生成完成后,会一直重复播放动画
五、上下文单批数量(Content batch size)

每次传入运动模块的帧数
「Stable Diffusion 1.5」运动模块使用「16帧」进行训练;
因此,当这里的帧数设置为「16」时,它将提供最佳效果;
数值越大,统一性与稳定性就越好,但对显存的要求也相应的更高;
数值越小,视频变化越大,统一性更差;
因此,通常保持在「16」就可以了,但需要注意的是:「总帧数」的设置要大于这里的数值。
六、闭环(Close loop)
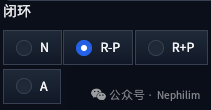
开启闭环,意味着该扩展会尝试「最后一帧」与「第一帧」相同;
可以选择不同的闭环选项来确定如何实现闭环:
N:不使用闭环,不产生前后循环的动画;如果帧数小于「上下文批处理」大小,而且不是「0」,那么,这是唯一可用的选项
A:扩展将积极尝试使最后一帧与第一帧相同,即时行程将被插值为一个闭环
R-P:扩展将试图减少闭环上下文的数量,即时行程不会被插值为闭环
R+P:扩展将试图减少闭环上下文的数量,即时行程将被插值为一个闭环;如果将帧数设置为大于或等于上下文批量大小的两倍,如果「上下文批量 = 16」而「帧数 = 32」,则R+P的效果最好
七、步幅(Stride)
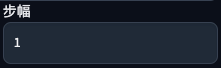
最大的运动步幅,默认值为「1」,以「2」的幂表示(2的平方,2的三次方,.. 等)
由于「无限上下文生成器」的限制,此参数仅仅在「帧数」大于「上下文批处理」大小的时候才有效。
八、重叠(Overlap)

上下文中重叠的帧数
如果重叠设置为默认值「-1」,重叠帧数将为「上下文批处理」大小的四分之一;
由于「无限上下文生成器」的限制,此参数仅在帧数大于「上下文批处理」大小的时候才有效。
九、帧差值(Frame Interpolation)与插值次数(Interp X)

使用Deforum的FILM实现在「帧」之间进行「插值」的时候用到的参数;
不使用Deforum的时候,保持关闭即可;
帧插值是通过增加每秒的帧数,使视频看起来更流畅。
插值次数X:
是用X个插值输出帧,替换每个输入帧;
十、视频源(Video source)
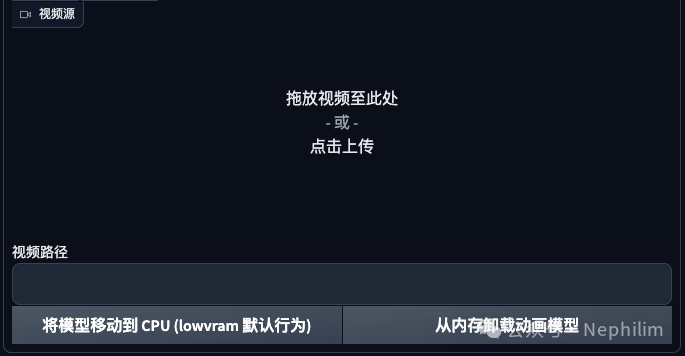
可选项。
使用ControlNet进行「视频生成视频」的源文件。
视频路径(Video path):可选项
使用ControlNet进行「视频生成视频」的源文件夹。
优先级低于「视频源」
08
画面动效的控制
AI动画中最难的就是「画面动效的控制」
可以通过下面几种方式去实现对画面动效的控制:
提示词(Prompt)
镜头运动(LoRA)
提示词游历(Prompt Travel)
09
「提示词」
使用AnimateDiff的时候,尽量将提示词控制在「75 Token」以内;
超过的话,会造成动作不统一;
这是因为,AI在理解文字的时候,是以「75 Token」为一组去划分的;
并且负面提示词也应该尽可能的简短一些;
在提示词的书写上,使用动词,可以驱动动画的产生,例如:
行走:walking
跑:running
跳舞:dancing
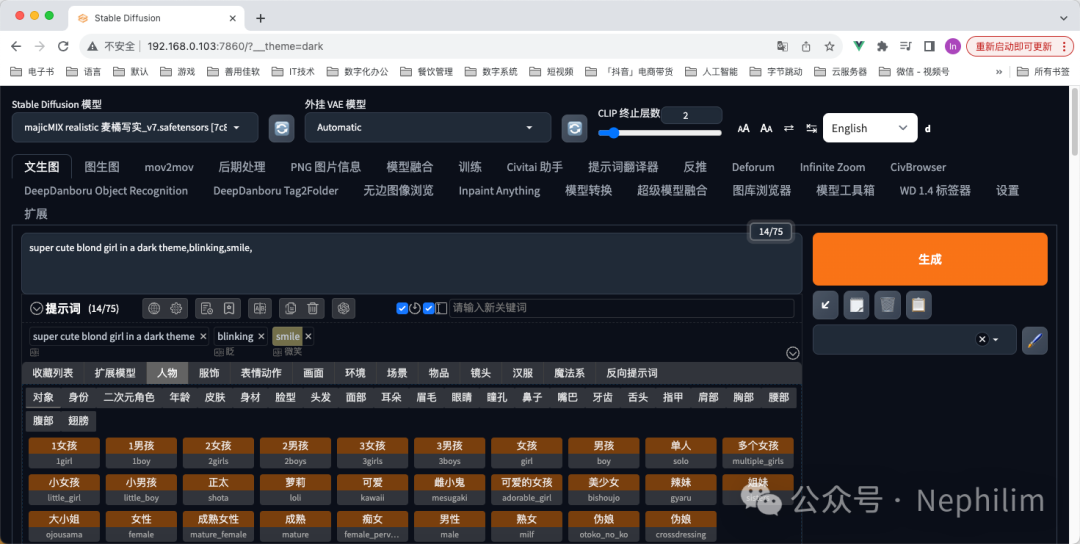
正向提示词:
super cute blond girl in a dark theme,blinking,smile,复制
反向提示词:
EasyNegative,BadDream,BadNegAnatomyV1-neg,复制
10
配置「AnimateDiff」的参数
参数:
11
生成
点击「生成」:

生成中:
生成的效果:

12
「Prompt Travel」游历提示词
在书写正向提示词的时候,加入帧数,就是「Prompt Travel」的语法,可以控制AI动画生成的时候,在哪一帧,做出什么动作:
super cute blond girl in a dark theme,blinking,(teasing_smile:0.2),0: close eyes,10: open eyes,14: smile,复制
再看看效果:

可以看到,生成的动画确实按照我们提示词中定义的那样:
Close Eyes
Open Eyes
Smile
当你使用游历提示词(Prompt Travel)去生成图片的时候,也可以在后台的命令行中看到对应的提示消息:

如上图所示:「INFO - You are using prompt travel」
还可以继续增加「Prompt Travel」:
super cute blond girl in a dark theme,blinking,(teasing_smile:0.2),0: close eyes,10: open eyes,14: smile,25: naughty face,calm face,复制
可以看到,最后表情会回归「平和」
再看看效果:

13
可能的错误
如果你还安装了「Dynamic Prompt」这个插件,那么使用「Prompt Travel」的时候可能会遇到如下的错误,导致「Prompt Travel」不起作用:

这个时候,解决的方法是:
禁用「Dynamic Prompt」
卸载「Dynamic Prompt」
14
AnimateDiff + ControlNet
ControlNet的官方代码仓库是:
https://github.com/lllyasviel/ControlNet
WebUI的ControlNet的官方代码仓库是:
https://github.com/Mikubill/sd-webui-controlnet
先下载ControlNet的模型,一共14个文件,后缀「pth」的模型文件;
下载地址:
https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main
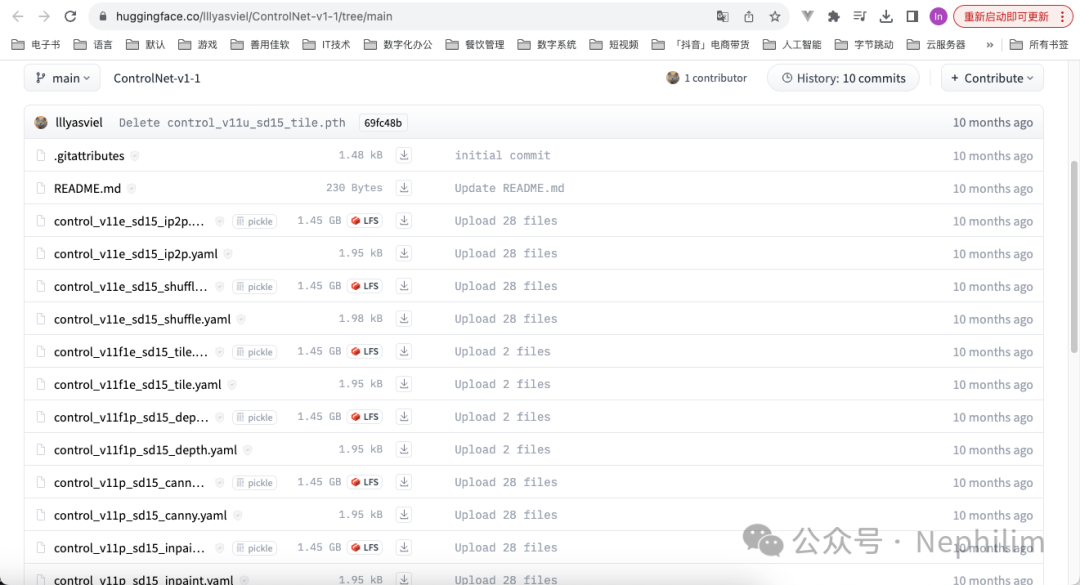
然后,将下载好的文件放置到如下的目录中:
<stable-diffusion-webui>\extensions\sd-webui-controlnet\models复制
像这样:
下面,开始配置并使用「ControlNet」
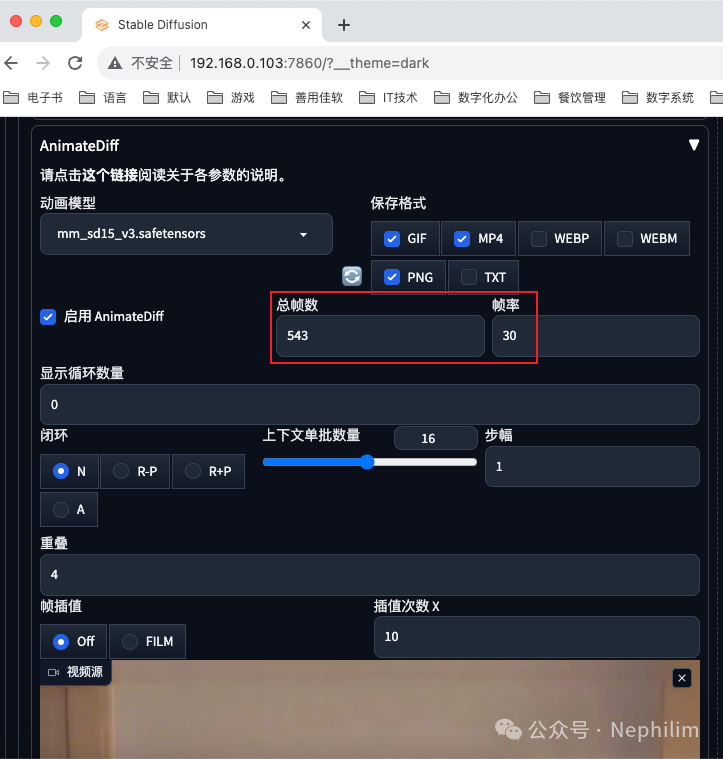
设置「AnimateDiff」的参数:
如上,先不填写「总帧数」与「帧率」。
在抖音上找一段好看的跳舞视频:来自抖音主播「糖醋里脊」的一段跳舞视频
可以看到,上传完成后,AnimateDiff插件,自动解析出了「总帧数」与「帧率」:
然后,设置ControlNet:
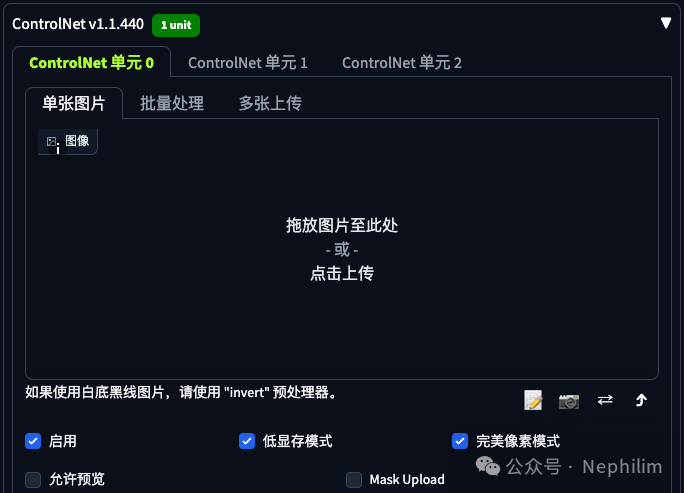
ControlNet会使用上面的AnimateDiff的参考视频。
然后选择「控制类型」与「预处理器」
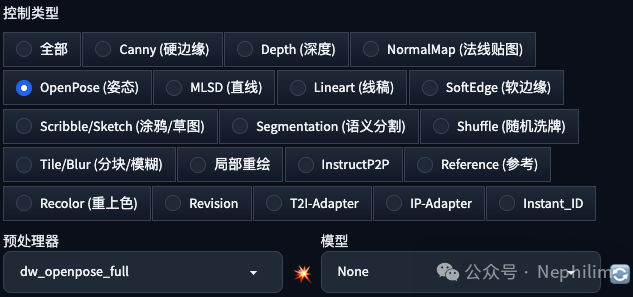
然后,修改提示词
正向提示词:
super cute blond girl in a dark theme,blinking,full body,dancing,0: close eyes,10: open eyes,14: smile,25: naughty face,calm face,复制
反向提示词:
EasyNegative,BadDream,BadNegAnatomyV1-neg,复制
直接生成:
大模型:「majicMIX realistic 麦橘写实 v7」
VAE模型:「Automatic」
生成中:
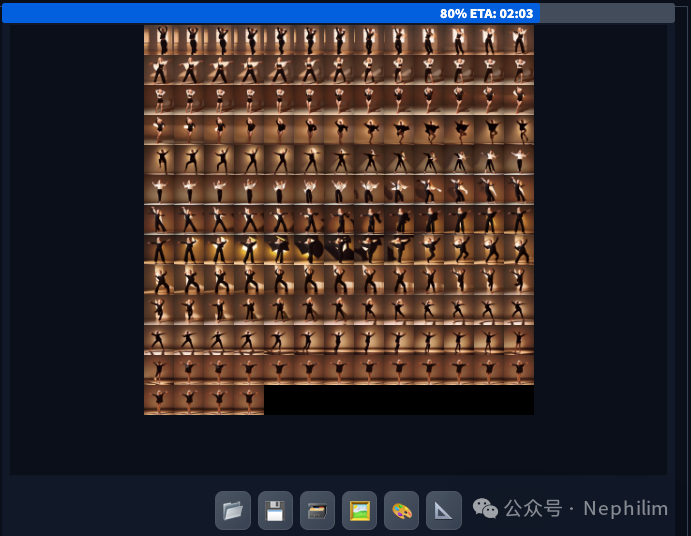
看看成片:
画面不稳定,人物的表情、肢体等动作不清晰,... 这些都是需要慢慢调试的;
毕竟基于的「模型」的质量不是最好的。
ED
『SD』对于画面的控制还有更多技巧
END
温馨提示
如果你喜欢本文,请分享到朋友圈,想要获得更多信息,请关注我。
