




在关系型数据库中,用户查找数据与行的物理位置无关。为了能够找到数据,表中的每一行均用一个ROWID来标识,ROWID能够标识数据库中某一行的具体位置。当Oracle数据库中存储海量的记录时,就意味着有大量的ROWID标识,那么Oracle如何能够快速找到指定的ROWID呢?这时就需要使用索引对象,它可以提供服务器在表中快速查找记录的功能。
1. 索引概述
如果一个数据表中存有海量的数据记录,当对表执行指定条件的查询时,常规的查询方法会先将所有的记录都读取出来,然后把读取的每一条记录与查询条件进行对比,最后返回满足条件的记录。这样进行操作的时间开销和I/O开销都十分巨大。针对这种情况,可以考虑通过建立索引来减小系统开销。
如果要在表中查询指定的记录,在没有索引的情况下,则必须遍历整张表,而有了索引之后,只需要在索引中找到符合查询条件的索引字段值,就可以通过保存在索引中的ROWID快速找到表中对应的记录。举个例子来说,如果将表看作一本书,那么索引的作用就类似于书中的目录。在没有目录的情况下,要在书中查找指定的内容必须阅读全书,而有了目录之后,只需要通过目录就可以快速找到包含所需内容的页码(相当于ROWID)。
Oracle系统对索引与表的管理有很多相同的地方,不仅需要在数据字典中保存索引的定义,还需要在表空间中为它分配实际的存储空间。创建索引时,Oracle会自动在用户的默认表空间或指定的表空间中创建一个索引段,为索引数据提供空间。
将索引和对应的表分别放在不同硬盘的不同表空间中能够提高查询的速度,因为Oracle能够并行读取不同硬盘的数据,这样的查询可以避免产生I/O冲突。
按照索引数据的存储方式可以将索引分为B树索引、位图索引、反向键索引和基于函数的索引;按照索引列的唯一性又可以将索引分为唯一索引和非唯一索引;按照索引列的个数又可以将索引分为单列索引和复合索引。
建立和规划索引时,必须选择合适的表和列,如果选择的表和列不合适,那么不仅无法提高查询速度,反而会极大地降低DML操作的速度,所以建立索引必须要注意以下几点:
索引应该建立在WHERE子句频繁引用表列上,如果在大表上频繁使用某列或某几个列作为条件执行索引操作,并且检索行数低于总行数的15%,那么应该考虑在这些列上建立索引。 如果经常需要基于某列或某几个列执行排序操作,那么在这些列上建立索引可以加快数据排序速度。 限制表的索引个数。索引主要用于加快查询速度,但会降低DML操作的速度。索引越多,DML操作速度越慢,尤其会极大地影响INSERT和DELETE操作的速度。因此,规划索引时,必须仔细权衡查询和DML的需求。 指定索引块空间的使用参数。基于表建立索引时,Oracle会将相应表列数据添加到索引块中。为索引块添加数据时,Oracle会按照PCTFREE参数在索引块中预留部分空间,该预留空间是为将来的INSERT操作准备的。如果将来在表上执行大量INSERT操作,那么应该在建立索引时设置较大的PCTFREE。 将表和索引部署到相同的表空间中,可以简化表空间的管理;将表和索引部署到不同的表空间中,可以提高访问性能。 当在大表上建立索引时,使用NOLOGGING选项可以最小化重做记录。使用NOLOGGING选项可以节省重做日志空间、减少索引建立时间、提高索引并行建立的性能。 不要在小表上建立索引。 为了提高多表连接的性能,应该在连接列上建立索引。
2. 创建索引
在创建索引时,Oracle首先对将要建立索引的字段进行排序,然后将排序后的字段值和对应记录的ROWID存储在索引段中。建立索引可以使用CREATE INDEX语句,通常由表的所有者来建立索引。如果要以其他用户身份建立索引,则要求用户必须具有CREATE ANY INDEX系统权限或者相应表的INDEX对象权限。
2.1. 建立B树索引
B树索引是Oracle数据库最常用的索引类型(也是默认类型),它以B树结构组织并存储索引数据。默认情况下,B树索引中的数据是以升序方式排列的。如果表包含的数据非常多,并且经常在WHERE子句中引用某列或某几个列,则应该基于该列或这几个列建立B树索引。B树索引由根块、分支块和叶块组成,其中主要数据都集中在叶子节点上。
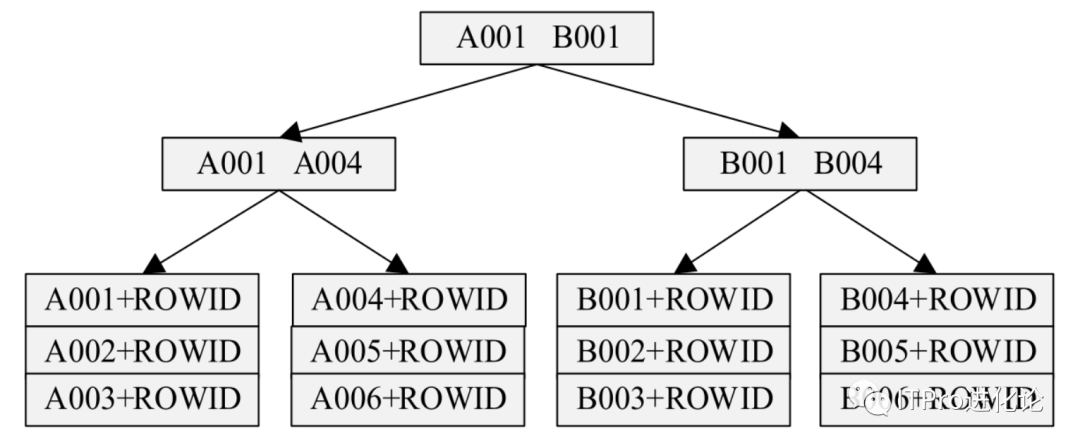
根块:索引顶级块,它包含指向下一级节点的信息。 分支块:它包含指向下一级节点(分支块或叶块)的信息。 叶块:通常也称叶子,它包含索引入口数据,索引入口包含索引列的值和记录行对应的物理地址ROWID。
在B树索引中无论用户要搜索哪个分支的叶块,都可以保证所经过的索引层次是相同的。Oracle采用这种方式的索引,可以确保无论索引条目位于何处,都只需要花费相同的I/O即可获取它,这就是为什么称为B树索引(B是英文BALANCED的缩写)。
例如上图,使用这个B树索引搜索编号为A006的节点时,首先访问根节点,值A006小于值B001,所以应该从左边的分支搜索,从左边的分支节点可以判断出,要搜索的索引条目位于右侧的叶子节点中,在那里可以很快找到要查询的索引条目,并根据索引条目中的ROWID进而找到所有要查询的记录。
--为emp表的deptno列创建索引
create index emp_deptno_index on emp(deptno) pctfree 25 tablespace TBS_TEST_1;
上述代码,子句PCTFREE指定为将来INSERT操作所预留的空闲空间,子句TABLESPACE用于指定索引段所在的表空间。假设表已经包含了大量数据,那么在建立索引时应该仔细规划PCTFREE的值,以便为以后的INSERT操作预留空间。
2.2. 建立位图索引
索引的作用简单地说就是能够通过给定的索引列值,快速地找到对应的记录。在B树索引中,通过在索引中保存排序的索引列的值以及记录的物理地址ROWID来实现快速查找。但是对于一些特殊的表,B树索引的效率可能会很低。例如,在某个具有性别列的表中,该列的所有取值只能是女或男。如果在性别列上创建B树索引,那么创建的B树只有两个分支,如下图所示。那么使用该索引对该表进行检索时,将返回接近一半的记录,这样也就失去了索引的基本作用。
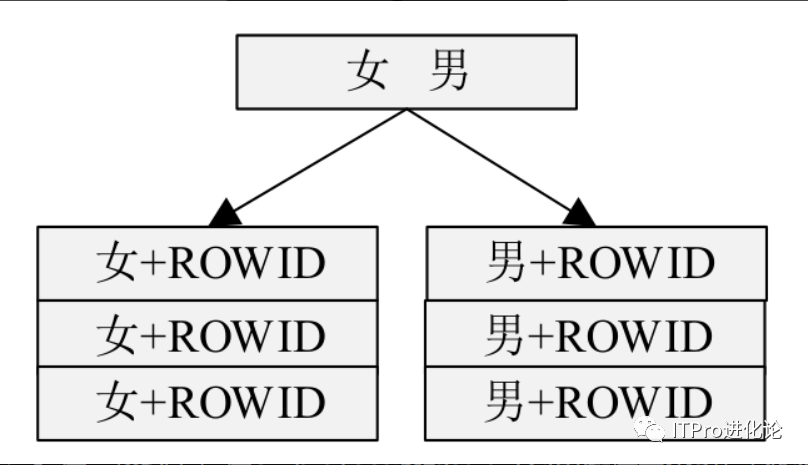
对于这种列的基数很低的情况,为其建立B树索引显然不合适。“基数低”表示在索引列中,所有取值的数量比表中行的数量少。如“性别”列只有两个取值;又如某个拥有10000行的表,它的一个列包含100个不同的取值,则该列仍然满足低基数的要求,因为该列与行数的比例为1%。Oracle推荐当一个列的基数小于1%时,这些列不再适合建立B树索引,而适用于位图索引。
当在表中低基数的列上建立位图索引时,系统将对表进行一次全面扫描,为遇到的各个取值构建“图表”。
--在students表的sex列创建位图索引
create bitmap index stu_sex_bmp on students(sex) tablespace TBS_TEST_1;
初始化参数CREATE_BITMAP_AREA_SIZE用于指定建立位图索引时分配的位图区大小,默认值为8 MB,该参数值越大,建立位图索引的速度就越快。为了加快创建位图索引的速度,应将该参数设置为更大的值。因为该参数是静态参数,所以修改后必须重新启动数据库才能生效。
--修改建立位图索引时分配的位图区大小
alter system set create_bitmap_area_size = 8388608 scope = spfile;
2.3. 建立反向键索引
在Oracle中,系统会自动为表的主键列建立索引,这个默认索引是普通的B树索引。通常,用户会希望表的主键是一个自动增长的序列编号,这样的列就是所谓的单调递增序列编号列。当在这种顺序递增的列上建立普通的B树索引时,如果表的数据量非常庞大,将导致索引数据分布不均。
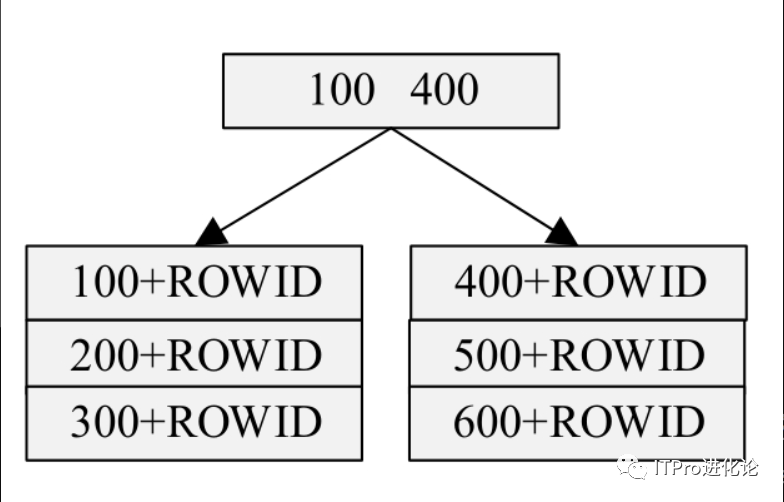
上图可以看到,这是一个典型的常规B树索引。如果现在要为其添加新的数据,由于主键列的单调递增性,很明显不需要重新访问早先的叶子节点。接下来的数据获得的主键为700,下一组数据的主键为800,以此类推。
这种方法在某些方面是具有优势的,由于它无须在已有表项之间嵌入新的表项,因此不会发生叶子节点的数据块分割。这意味着,单调递增序列上的索引能够完全利用它的叶子节点非常紧密地存储数据块,以实现有效利用存储空间。然而,这种优势是需要付出代价的,每条记录都会占据最后的叶子节点,即使删除了先前的节点,也会导致同样的问题。这最终会导致对某一边的叶子节点的大量争用。
所以就需要设计一个规则,阻止用户在单调递增序列上建立索引后使用叶子节点偏向某一个方向。遗憾的是,序列编号通常是用来做表的主键的,每个主键都需要建立索引,即使用户没有建立索引,Oracle也会自动建立。但是,Oracle提供另一种索引机制,即反向键索引,它可以将添加的数据随机分散到索引中。
反向键索引是一种特殊类型的B树索引,在顺序递增列上建立索引时非常有用。反向键索引的工作原理非常简单,在存储结构方面它与常规的B树索引相同。然而,如果用户使用序列在表中输入记录,则反向键索引首先指向每个列键值的字节,然后在反向后的新数据上进行索引。例如,如果用户输入的索引列为2023,则反向转换后为3202;9567反向转换后为7659。需要注意的是,刚才提及的两个序列编号是递增的,但是当进行反向键索引时却是非递增的。这意味着,如果将其添加到子叶节点中,则可能会在任意的子叶节点中进行。这样就使得新数据在值的范围上的分布通常比原来的有序数更均匀。
对于emp表中的empno列而言,由于该列是顺序递增的,因此为了均衡索引数据分布,应在该列上建立反向键索引。创建反向键索引时,只需要在CREATE INDEX语句中指定关键字REVERSE即可。
--为表emp中的job列创建反向键索引
create index emp_job_reverse on emp(job) reverse tablespace TBS_TEST_1;
如果在该列上已经建立了普通的B树索引,那么可以使用ALTER INDEX…REBUILD语句将其重新建立为反向键索引。
--为emp表中的deptno列创建反向键索引(其B树索引为emp_deptno_index)
alter index emp_deptno_index rebuild reverse;
2.4. 基于函数的索引
在使用Oracle数据库时,最常遇到的问题之一就是它对字符大小写敏感。例如,在emp表中存有职位(job)为MANAGER的记录,当使用小写搜索时,将无法找到该行记录。另外,如果不能确定输入数据的格式,甚至会产生一个严重的错误。
对于上面出现的情况,可以使用Oracle字符串函数对其进行转换,然后使用转换后的数据进行检查。
查询emp表中职位是manager的记录,并使用UPPER函数把manager字符串转换成大写格式,代码如下:
select empno,ename,sal from emp where job=upper('manager')
使用UPPER函数进行字符串转换后,所使用的字符的大小写无论如何组合,都可以使用该语句检索到数据。但是,使用这样的查询时,不是基于表中存储的记录进行搜索的,即如果搜索的值不存在于表中,那么它就一定也不会在索引中,所以即使在job列上建立索引,Oracle也会被迫执行全表搜索,并为所遇到的各个行计算UPPER函数。
为了解决这个问题,Oracle提供了一种新的索引类型——基于函数的索引。基于函数的索引只是常规B树索引,但它存储的数据是由表中的数据应用函数后所得到的,而不是直接存储表中的数据本身。
由于在SQL语句中经常使用小写字符串,因此为了加快数据访问速度,应基于LOWER函数建立函数索引。
--为emp表中的job列创建函数索引
create index emp_job_fun on emp(lower(job));
在创建这个函数索引之后,如果在查询条件中包含相同的函数,则系统会利用它来提高查询的执行效率。
如果用户在自己的模式中创建基于函数的索引,则必须具有QUERY PEWRITE系统权限。如果用户要在其他模式中创建索引,则必须具有CREATE ANY INDEX和GLOBAL QUERY REWRITE权限。
3. 修改索引
修改索引通常是使用ALTER INDEX语句完成的。一般情况下,修改索引是由索引的所有者完成的,如果要以其他用户身份修改索引,则要求该用户必须具有ALTER ANY INDEX系统权限或在相应表上的INDEX对象权限。
为表建立索引后,随着对表不断进行更新、插入和删除操作,索引中会产生越来越多的存储碎片,这对索引的工作效率会产生负面影响。这时可以采取两种方式来清除碎片——重建索引或合并索引。合并索引只是将B树中叶子节点的存储碎片合并在一起,并不会改变索引的物理组织结构。
--对索引emp_deptno_index执行合并操作
alter index emp_deptno_index coalesce deallocate unused;
下图显示了对索引执行合并操作后的效果。假设在执行该操作之前,B树索引的前两个叶块分别有70%和30%的空闲空间。合并索引后,可以将它们的数据合并到一个索引叶子块中。
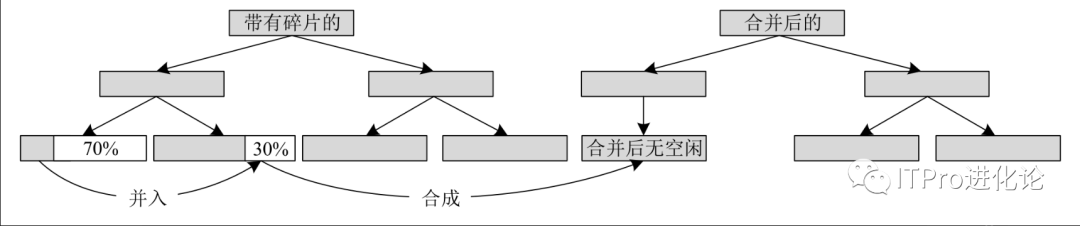
消除索引碎片的另一个方法是重建索引,重建索引可以使用ALTER INDEX…REBUILD语句。重建操作不仅可以消除存储碎片,还可以改变索引的全部存储参数设置,以及改变索引的存储表空间。重建索引实际上是在指定的表空间中重新建立一个新的索引,然后删除原来的索引。
--对索引emp_deptno_index执行重建操作
alter index emp_deptno_index rebuild;
在使用ALTER INDEX…REBUILD语句重建索引时,可以在其中使用REVERSE子句将一个反向键索引更改为普通索引,反之也可以将一个普通的B树索引转换为反向键索引。另外,还可以使用TABLESPACE子句指定重建索引的存储位置。
--对索引emp_deptno_index执行重建操作,并重新指定该索引对象的表空间
alter index emp_deptno_index rebuild tablespace example;
4. 删除索引
在使用ALTER INDEX…REBUILD语句重建索引时,可以在其中使用REVERSE子句将一个反向键索引更改为普通索引,反之也可以将一个普通的B树索引转换为反向键索引。另外,还可以使用TABLESPACE子句指定重建索引的存储位置:
如果移动表中的数据,导致索引中包含过多的存储碎片,此时需要删除并重建索引。 通过一段时间的监视,发现很少有查询会使用到该索引。 当该索引不再被需要时应该删除该索引,以释放其所占用的空间。
索引被删除后,它所占用的所有盘区都将返回给包含它的表空间,并可以被表空间中的其他对象使用。索引的删除方式与索引被创建时所采用的方式有关,如果使用CREATE INDEX语句显式地创建该索引,则可以用DROP INDEX语句删除该索引。
--删除函数索引emp_job_fun
drop index emp_job_fun;
如果索引是在定义约束时由Oracle系统自动建立的,则必须禁用或删除该约束本身。另外,在删除一个表时,Oracle也会删除所有与该表有关的索引。
关于索引最后需要注意一点,虽然一个表可以拥有任意数目的索引,但是表中的索引数据越多,维护索引所需要的开销也就越大。每当向表中插入、删除或更新一条记录时,Oracle都必须对该表中的所有索引进行更新。因此,用户还需要在表的查询速度和更新速度之间找到一个平衡点。也就是说,应该根据表的实际情况限制在表中创建的索引数量。
5. 显示索引信息
为了显示Oracle索引的信息,Oracle提供了一系列的数据字典视图。通过查询这些数据字典视图,用户可以了解索引的各方面信息。
5.1. 显示表的所有索引
索引是用于加速数据存储的数据库对象。查询如下数据字典视图可以获得索引信息:
dba_indexes,可以显示数据库中的所有索引; all_indexes,可以显示当前用户可访问的所有索引; user_indexes,可以显示当前用户的索引信息。
--在数据字典dba_indexes中查询所有者是SCOTT的全部索引对象
select index_name,index_type,owner from dba_indexes where owner = 'SCOTT';
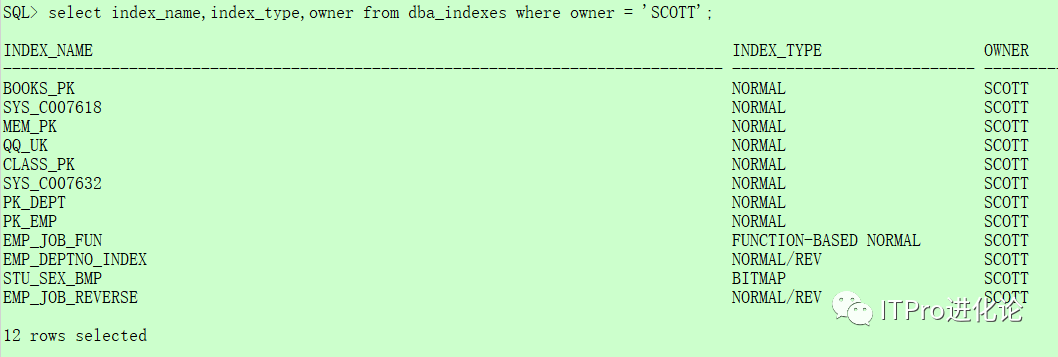
上图中,INDEX_NAME用于标识索引名,INDEX_TYPE用于标识索引类型,NORMAL表示普通B树索引,REV表示反向键索引,BITMAP表示位图索引,FUNCTION表示基于函数的索引,UNIQUENESS用于标识索引的唯一性,OWNER用于标识对象的所有者。
5.2. 显示索引列
创建索引时,需要提供相应的表列。查询如下数据字典视图可以获得索引列信息:
dba_ind_columns,可以显示所有索引的表列信息; all_ind_columns,可以显示当前用户可访问的所有索引的表列信息; user_ind_columns,可以显示当前用户索引的表列信息。
--查询scott用户的EMP_DEPTNO_INDEX索引的列信息
select column_name ,column_length from user_ind_columns where index_name = 'EMP_DEPTNO_INDEX';

5.3. 显示索引段位置及其大小
建立索引时,Oracle会为索引分配相应的索引字段,索引数据被存储在索引段中,并且段名与索引名完全相同。通过查询索引段视图user_segments,可以显示当前用户所拥有的段分配的信息。
--查询索引段EMP_DEPTNO_INDEX的位置、段类型和段大小
select tablespace_name,segment_type,bytes from user_segments where segment_name='EMP_DEPTNO_INDEX';

5.4. 显示函数索引
通过查询数据字典视图dba_ind_expressions,可以显示数据库中所有函数索引所对应的函数或表达式;通过查询数据字典user_ind_expressions,可以显示当前用户的所有函数索引所对应的函数或表达式。
--查询函数索引EMP_JOB_FUN的表达式信息
select column_expression from user_ind_expressions where index_name='EMP_JOB_FUN';

今天的文章就到这里,如果对你有用,记得点个【赞】和【在看】,感谢阅读~
