




测试环境:
-
Vertica:Vertica Analytic Database v11.1.1-22
-
WutongDB:V5.4.10.0
1. match_columns
-
功能说明:
match_columns(pattern)函数用于在表中搜索列名,返回与指定模式(pattern)匹配的列名列表。这个函数特别适用于在大型表中查找特定的列。 -
测试语句:
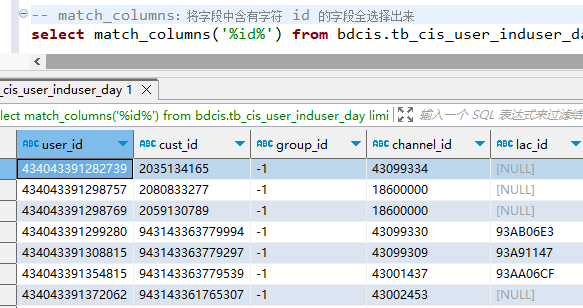
select match_columns('%id%') from bdcis.tb_cis_user_induser_day limit 10; -
Vertica 输出结果:
vertica 可以直接使用该函数,输出结果如下图所示:
-
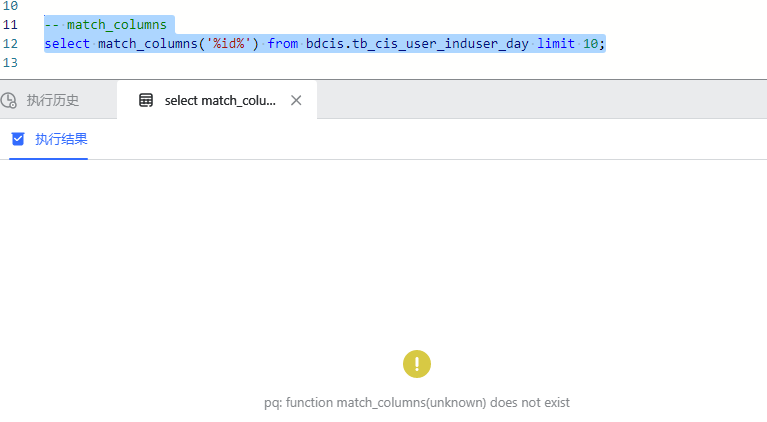
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
-
Wutong DB 5.4 替代方案:
-
在 Wutong DB 5.4 中没有直接等效的
match_columns函数,可以通过元数据表information_schema.columns和模式匹配来实现类似功能:sql复制代码SELECT column_name FROM information_schema.columns WHERE table_name = 'tb_cis_user_induser_day' AND column_name LIKE '%id%'; -
函数说明:
information_schema.columns:存储数据库中所有表和列的元数据信息。LIKE '%id%':用于进行模式匹配,查找列名中包含 “id” 的列。
-
-
Wutong DB 6 替代方案:
-
在 Wutong DB 6 中,同样可以使用
information_schema.columns结合LIKE实现列名匹配:sql复制代码SELECT column_name FROM information_schema.columns WHERE table_name = 'tb_cis_user_induser_day' AND column_name LIKE '%id%';
-
2. regexp_count
-
功能说明:
regexp_count(expression, pattern)函数用于计算表达式中与指定正则表达式模式匹配的子字符串的数量。这个函数常用于统计文本中特定模式出现的次数。 -
测试语句:
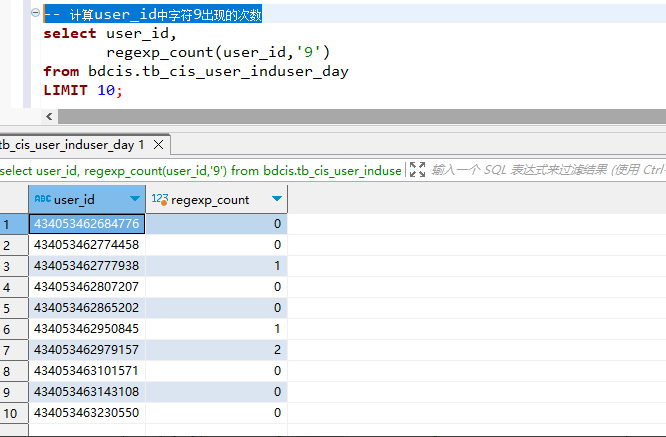
select user_id, regexp_count(user_id, '9') from bdcis.tb_cis_user_induser_day limit 10; -
Vertica 输出结果:
vertica 可以直接使用该函数,输出结果如下图所示:
-
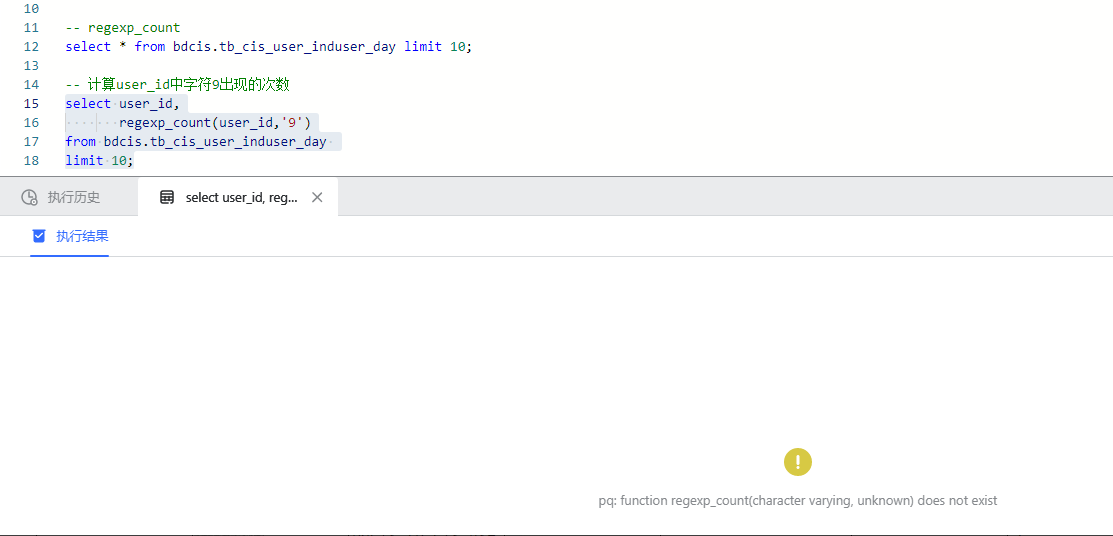
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
-
Wutong DB 5.4 替代方案:
-
在 Wutong DB 5.4 中没有
regexp_count函数,但可以通过regexp_matches函数结合数组长度计算来模拟实现:SELECT array_length(regexp_matches(expression, pattern, 'g'), 1) AS match_count; -
函数说明:
regexp_matches(expression, pattern, 'g'):返回所有匹配模式的子字符串,使用 ‘g’ 选项表示全局匹配。array_length(array, 1):返回数组的长度,表示匹配项的数量。
-
-
Wutong DB 6 替代方案:
-
在 Wutong DB 6 中,也没有直接的
regexp_count函数,可以继续使用上述方法:SELECT array_length(regexp_matches(expression, pattern, 'g'), 1) AS match_count;
-
3. regexp_ilike
-
功能说明:
regexp_ilike(expression, pattern)函数用于判断表达式是否与指定的正则表达式模式不区分大小写匹配。这个函数类似于ILIKE,但支持正则表达式。 -
测试语句:
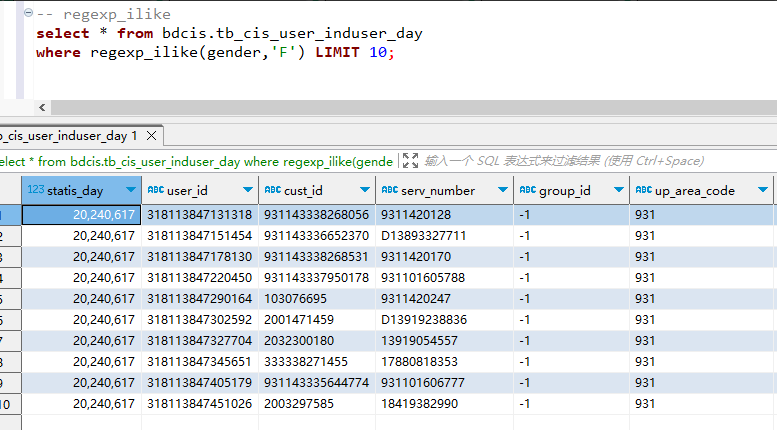
select * from bdcis.tb_cis_user_induser_day where regexp_ilike(gender, 'F') LIMIT 10; -
Vertica 输出结果:
vertica 可以直接使用该函数,输出结果如下图所示:
-
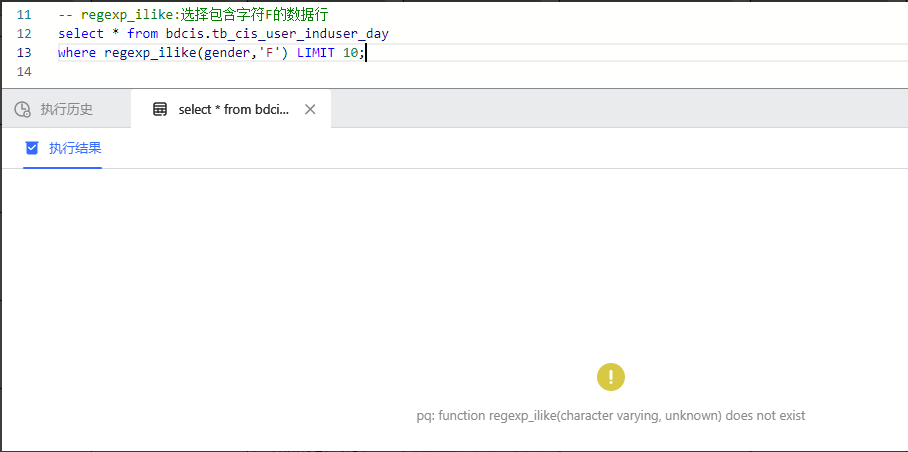
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
-
Wutong DB 5.4 替代方案:
- 在 Wutong DB 5.4 中,可以通过
LOWER()函数和正则表达式结合实现不区分大小写的匹配。
SELECT * FROM table_name WHERE LOWER(expression) ~ LOWER(pattern); - 在 Wutong DB 5.4 中,可以通过
-
Wutong DB 6 替代方案:
- 在 Wutong DB 6 中,可以使用
~*操作符,该操作符用于不区分大小写的正则表达式匹配。
SELECT * FROM table_name WHERE expression ~* pattern;- 函数说明:
~*:用于不区分大小写的正则表达式匹配。
- 在 Wutong DB 6 中,可以使用
4. regexp_instr
-
功能说明:
regexp_instr(expression, pattern)函数返回表达式中首次匹配正则表达式模式的位置。这个函数在需要定位某个模式在字符串中的位置时非常有用。 -
测试语句:
select a.upp_area_code , --地市 a.user_id , --用户编码 a.join_date , --入网时间 a.photo_stall , --拍照用户档位 a.user_flag_1 , --是否保提转(1是0否) a.plan_id_new , --新办理的plan_id a.plan_name_new , --新办理的plan_name a.plan_stall_new , --营销案档位 a.user_flag_2 , --是否变更档位(1是0否) a.plan_id_old , --旧的plan_id c.offer_name , --旧的plan_name to_number(to_char(case when translate(c.offer_name,repeat('0', 10), '0123456789') like '%0元%' and regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0元')+1-regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0')<=3 then substr(c.offer_name,regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0'),regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0元')+1-regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0')) when translate(c.offer_name,repeat('0', 10), '0123456789') like '%0套餐%' and regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0套餐')+1-regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0')<=3 then substr(c.offer_name,regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0'),regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0套餐')+1-regexp_instr(translate(c.offer_name,repeat('0', 10), '0123456789'),'0')) else '0' end)) --旧的档位 from gs_test.ceshi_regexp_instr a left join gs_test.ceshi_regexp_instr2 c --bdbds.tb_bds_prod_plans_message_day on a.plan_id_old=c.offer_id; -
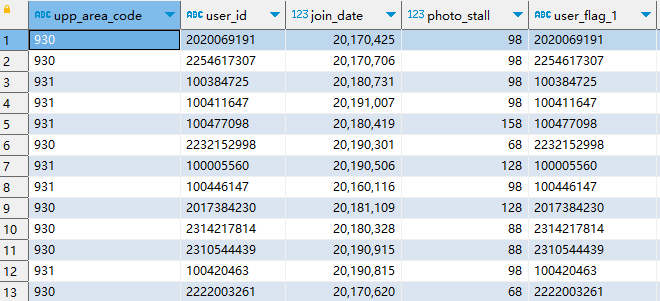
Vertica 输出结果:
输出结果如下图所示:
-
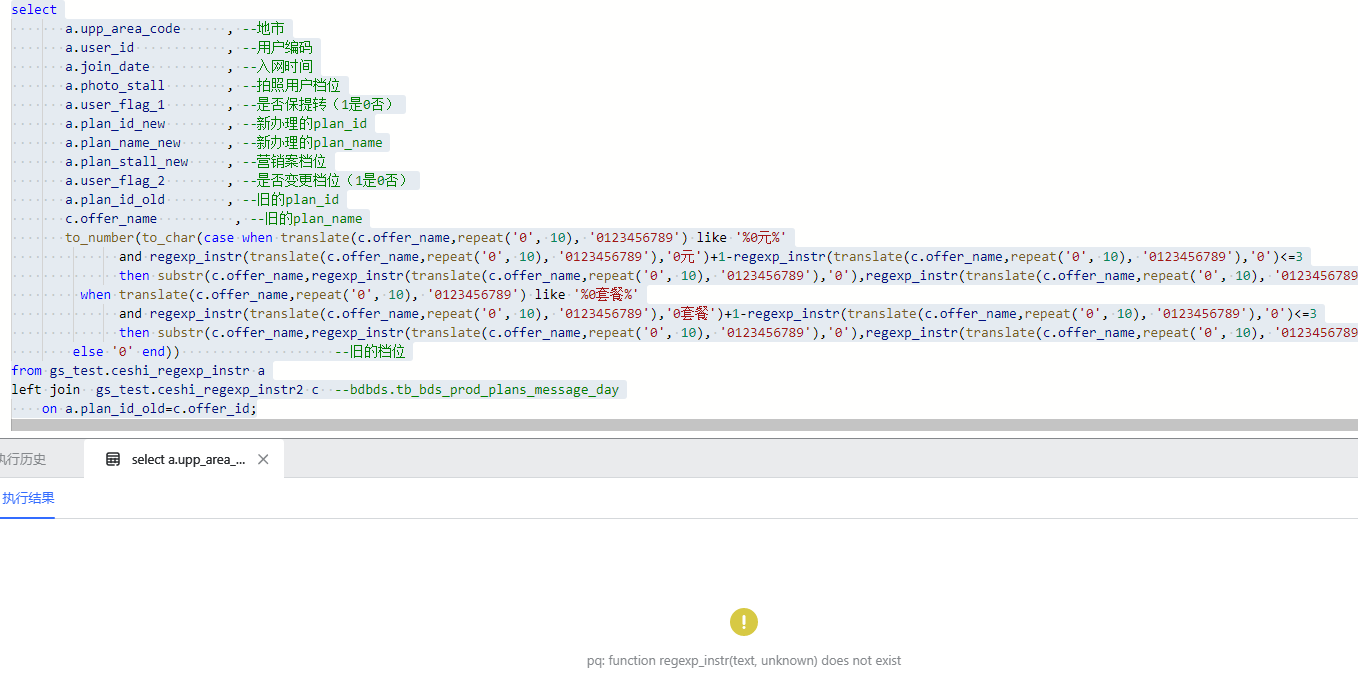
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
-
Wutong DB 5.4 替代方案:
-
在 Wutong DB 5.4 中没有
regexp_instr函数,可以使用POSITION()和regexp_replace()组合来模拟:SELECT POSITION(pattern IN regexp_replace(expression, '^.*(' || pattern || ').*$', '\1')); -
函数说明:
regexp_replace(expression, pattern, replacement):使用正则表达式进行替换。POSITION(substring IN string):返回子字符串在字符串中首次出现的位置。
-
-
Wutong DB 6 替代方案:
-
在 Wutong DB 6 中,可以使用
regexp_replace()和POSITION()的组合来模拟regexp_instr的功能:SELECT POSITION(pattern IN regexp_replace(expression, '^.*(' || pattern || ').*$', '\1'));
-
5. regexp_not_ilike
-
功能说明:
regexp_not_ilike(expression, pattern)函数用于判断表达式是否不与指定的正则表达式模式(不区分大小写)匹配。这个函数与regexp_ilike相反。 -
测试语句:
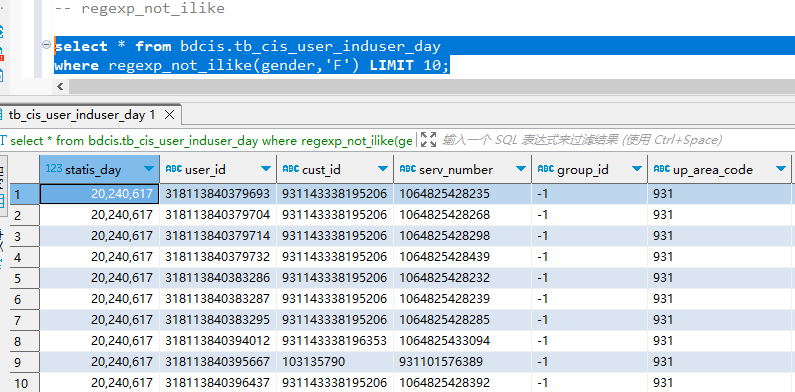
select * from bdcis.tb_cis_user_induser_day where regexp_not_ilike(gender, 'F') LIMIT 10; -
Vertica 输出结果:
在 vertica 中可以执行,如下图所示:
-
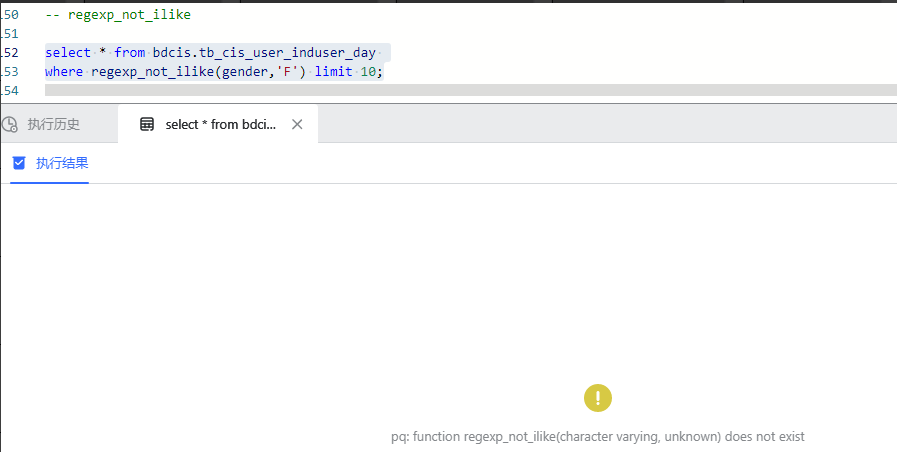
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
-
Wutong DB 5.4 替代方案:
-
在 Wutong DB 5.4 中没有直接的
regexp_not_ilike函数,但可以通过将表达式和模式都转换为小写,并结合regexp_matches函数和逻辑否定来模拟这种不区分大小写的非匹配操作。SELECT NOT regexp_matches(LOWER(expression), LOWER(pattern)) IS NOT NULL AS not_match_result; -
函数说明:
LOWER(expression):将表达式转换为小写,以便进行不区分大小写的匹配。regexp_matches(expression, pattern):用于匹配正则表达式,返回匹配的结果。NOT ... IS NOT NULL:通过逻辑否定判断匹配是否不成功,成功时返回FALSE,不匹配时返回TRUE。
-
-
Wutong DB 6 替代方案:
-
Wutong DB 6 同样没有直接的
regexp_not_ilike,可以使用相同的方法,通过LOWER()和regexp_matches函数来模拟不区分大小写的非匹配操作:SELECT NOT regexp_matches(LOWER(expression), LOWER(pattern)) IS NOT NULL AS not_match_result;
-
6. regexp_not_like
-
功能说明:
regexp_not_like(expression, pattern)函数用于判断表达式是否不与指定的正则表达式模式(区分大小写)匹配。这个函数与regexp_like相反。 -
测试语句:
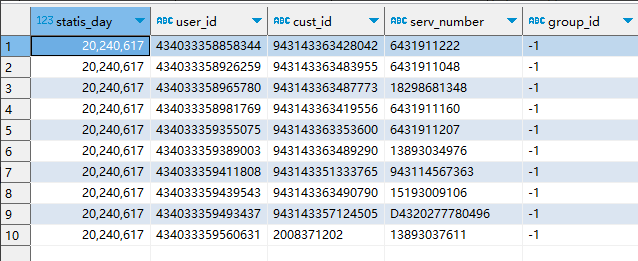
select * from bdcis.tb_cis_user_induser_day where regexp_not_like(gender, 'M') LIMIT 10; -
Vertica 输出结果:
在 vertica 中可以执行,如下图所示:
-
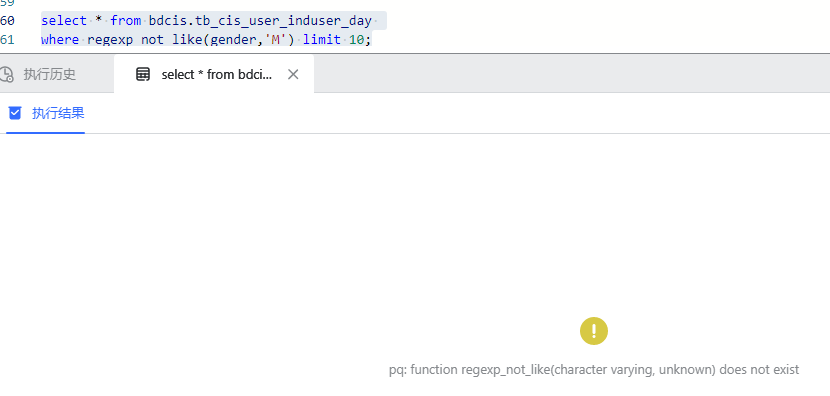
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
-
Wutong DB 5.4 和 Wutong DB 6 替代方案:
- 在 Wutong DB 中,可以使用
!~操作符来表示不匹配正则表达式的情况。
SELECT * FROM table_name WHERE expression !~ pattern;- 函数说明:
!~:用于判断表达式不符合给定的正则表达式。
- 在 Wutong DB 中,可以使用
7. regexp_replace
-
功能说明:
regexp_replace(expression, pattern, replacement)函数用于在表达式中用替换文本替换所有匹配指定正则表达式模式的子字符串。这个函数常用于数据清洗和格式化。 -
测试语句:
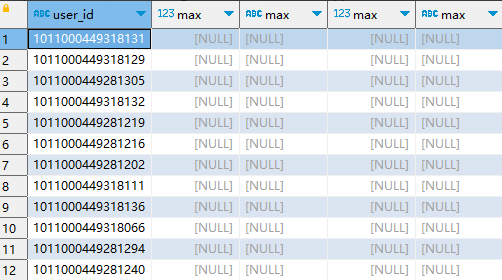
select a.user_id, max(case when attr_code='1' then length(regexp_replace(b.attr_value,'[0-9]'))+1 end ),----语音定向白名单数量 max(case when attr_code='1' then b.attr_value end), --语音定向白名单列表 max(case when attr_code='2' then length(regexp_replace(b.attr_value,'[0-9]'))+1 end) ,----短信定向数量 max(case when attr_code='2' then b.attr_value end) --短信白名单号码列表 from gs_test.ceshi_regexp_replace a, gs_test.ceshi_regexp_replace2 b where a.user_id=b.user_id group by a.user_id; -
Vertica 输出结果:
在 vertica 中可以执行,如下图所示:
-
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
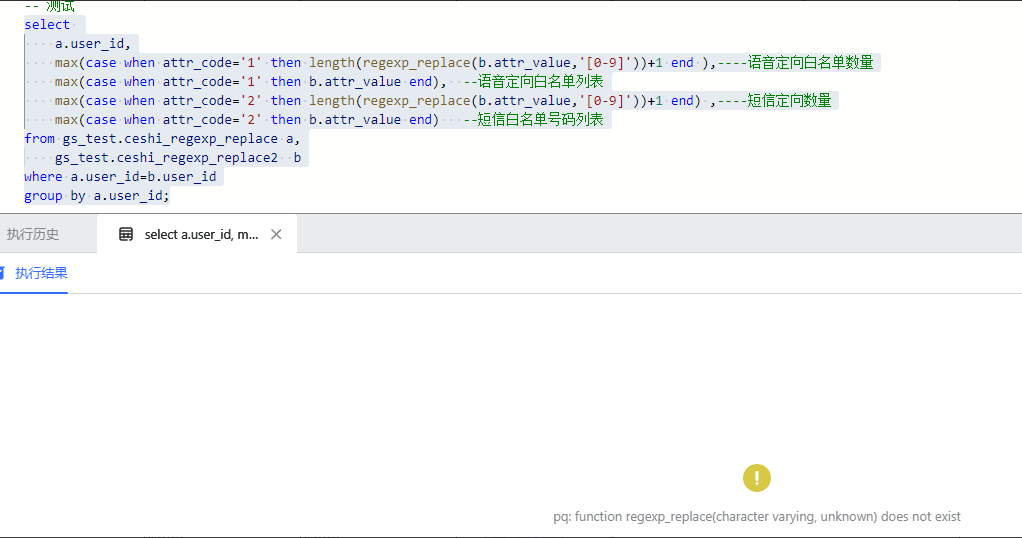
-- 在梧桐数据库中经检测,当函数里有三个参数时可以执行 select regexp_replace('healthy,wealthy,and wise','\w+thy','something'); -- 执行结果为:healthy,wealthy,and wise (结果是错的,应该是something,something,and wise,将结尾为thy的替换为something); -- 当只有两个参数时,报错显示函数不存在,语句为: select regexp_replace('healthy,wealthy,and wise','\w+thy'); -
Wutong DB 5.4 替代方案:
-
Wutong DB 5.4 已支持
regexp_replace函数,因此可以直接使用此函数:SELECT regexp_replace(expression, pattern, replacement) AS result; -
函数说明:
regexp_replace(expression, pattern, replacement):使用正则表达式进行替换操作。
-
-
Wutong DB 6 替代方案:
-
Wutong DB 6 继续支持
regexp_replace函数,语法和功能与 8.2.15 版本相同:SELECT regexp_replace(expression, pattern, replacement) AS result;
-
8. regexp_substr
-
功能说明:
regexp_substr(expression, pattern)函数用于返回表达式中与指定正则表达式模式匹配的子字符串。这个函数非常适合从文本中提取特定格式的信息。 -
测试语句:
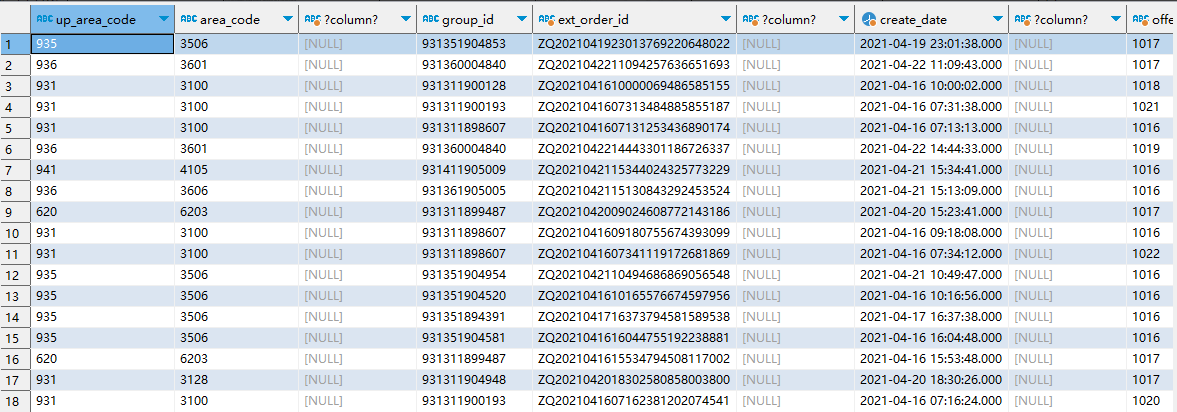
select distinct up_area_code , --地市 area_code , --县区 null , --商品订购实例标识 group_id , --集团编号 ext_order_id , --计费号码 null , --用户标识 create_date , --订购日期 null , --订购产品编号 offer_id , --订购资费编码 offer_name , --订购资费名称 create_op_id , --操作人工号 '商企通' , --产品类型 null , --资费类型 regexp_substr(substr(offer_name,instr(offer_name,'元')-5,5),'[0-9]\\d+')::integer --资费 from gs_test.ceshi_regexp_substr where offer_id between 1016 and 1022 and flow_state not in ('10', '22') and create_date >= '2021-03-23' and create_date <= '2021-12-18'; -
Vertica 输出结果:
在 vertica 中可以执行,如下图所示:
-
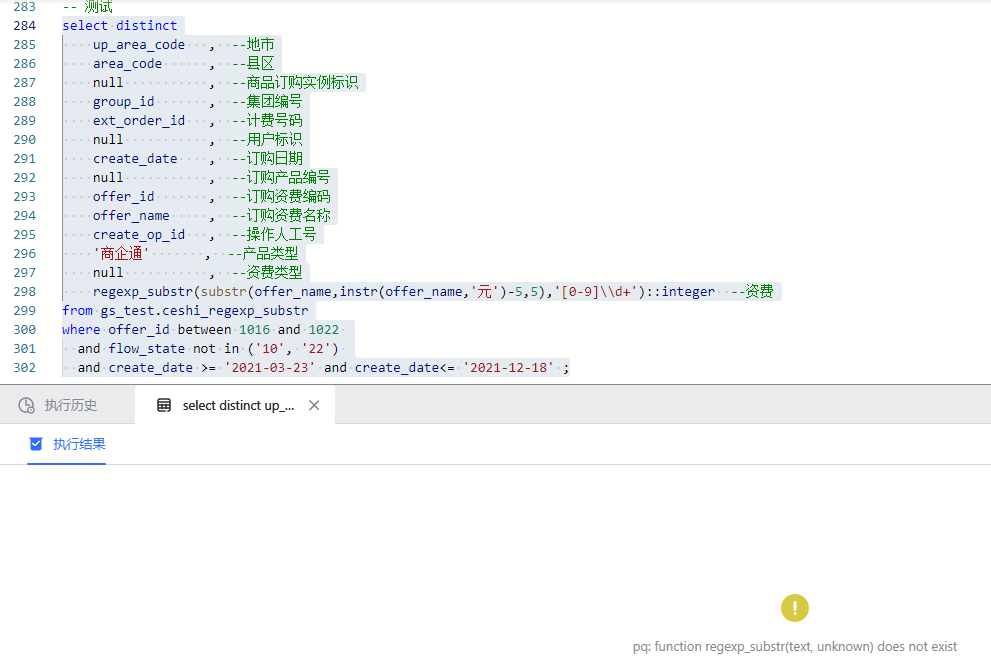
WutongDB 输出结果:
在梧桐数据库在显示无此函数,如下图所示:
-
Wutong DB 5.4 替代方案:
-
在 Wutong DB 5.4 中没有
regexp_substr函数,可以使用substring()和正则表达式组合来实现类似功能:SELECT substring(expression FROM pattern) AS match_substring; -
函数说明:
substring(string FROM pattern):返回第一个匹配模式的子字符串。
-
-
Wutong DB 6 替代方案:
-
在 Wutong DB 6 中,也可以使用
substring()函数与正则表达式组合来实现类似的regexp_substr功能:SELECT substring(expression FROM pattern) AS match_substring;
-
