




在 KingbaseES 运维中,SQL 语句可以帮助管理和优化数据库,进行性能监控、查询分析和日常操作。以下是一些 KingbaseES 数据库日常运维 SQL ,涵盖常见的运维场景:
1. 检查数据库连接数和活动会话
select datname,
numbackends as active_connections,
xact_commit as commits,
xact_rollback as rollbacks,
blks_read as blocks_read,
blks_hit as blocks_hit
from sys_stat_database;
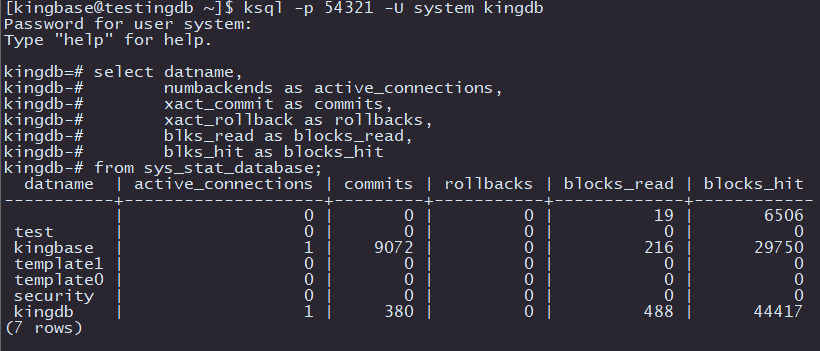
这段SQL代码通过查询sys_stat_database系统视图,获取了 kingbaseES 数据库的整体性能和连接活动的统计信息。它包含了以下几个关键指标,帮助我们对数据库的性能进行初步分析和监控:
-
datname: 数据库名称,标识各个数据库实例,便于分辨分析对象。
-
numbackends (active_connections): 当前活跃连接数,表示有多少个客户端正在与该数据库交互。这是衡量数据库负载和连接压力的关键指标。
-
xact_commit (commits): 事务提交的总数。通过查看事务的提交情况,我们可以了解数据库的工作负荷。
-
xact_rollback (rollbacks): 事务回滚的总数。回滚通常代表失败或被撤销的事务,较高的回滚数量可能预示着潜在的应用问题。
-
blks_read (blocks_read): 从磁盘读取的数据块数量,通常表示物理I/O操作的频率。
-
blks_hit (blocks_hit): 在共享内存缓存(即缓冲区缓存)中找到的数据块数量,通常反映了数据库缓存命中率的情况。
通过分析这些指标,我们可以深入了解数据库的健康状况和性能瓶颈,尤其是通过缓存命中情况(blocks_hit与blocks_read的比率)来判断数据库是否存在I/O瓶颈。
2. 查看长时间运行的查询
select pid,
age(clock_timestamp(), query_start) as runtime,
usename,
query
from sys_stat_activity
where state = 'active'
and query_start < now() - interval '5 minutes'
order by runtime desc;
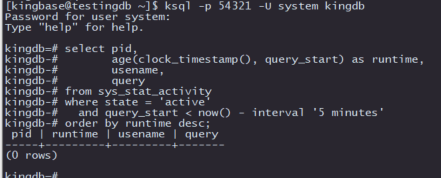
这段SQL代码通过查询 sys_stat_activity系统视图,用于监控在 kingbaseES 中运行时间超过5分钟的活动查询。以下是各个字段的作用:
-
pid: 查询的进程ID,用于唯一标识 kingbaseES 中的每个活动进程,便于后续定位或终止特定查询。
-
age(clock_timestamp(), query_start) (runtime): 查询的运行时长,计算当前时间与查询开始时间之间的差异。这个字段帮助识别长期运行的查询。
-
usename: 发起查询的用户名称,用于了解是谁在执行这些长时间运行的查询。
-
query: 实际执行的SQL查询文本,可以用来分析查询是否存在优化空间。
通过过滤条件state = ‘active’,该SQL只显示当前正在运行的查询。此外,query_start < now() - interval '5 minutes’确保只选择运行超过5分钟的查询。最终结果按运行时间从长到短排序,以便优先关注那些长时间占用资源的查询。
3. 查看索引的使用情况
SELECT relname AS table_name,
indexrelname AS index_name,
idx_scan AS index_scans,
idx_tup_read AS tuples_read,
idx_tup_fetch AS tuples_fetched
FROM sys_stat_user_indexes
JOIN sys_index
ON sys_stat_user_indexes.indexrelid = sys_index.indexrelid
WHERE idx_scan = 0;
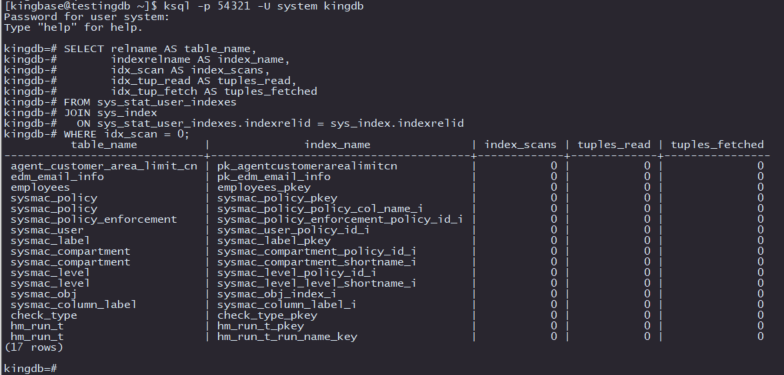
这段SQL代码通过查询sys_stat_user_indexes和sys_index系统视图,用于识别Kingbase数据库中从未被使用过的索引。虽然索引通常能够加快查询速度,但未被使用的索引不仅无法带来性能提升,反而会占用存储资源并增加写操作的负担。因此,识别并删除这些冗余索引,对于优化数据库性能至关重要。
以下是各个字段的作用:
-
relname (table_name): 包含索引的表的名称,用于确定索引所在的表。
-
indexrelname (index_name): 索引的名称,用于标识具体的索引。
-
idx_scan (index_scans): 索引被扫描的次数。过滤条件为idx_scan = 0,表示该索引自创建以来从未被使用过。
-
idx_tup_read (tuples_read): 通过该索引读取的元组数量,这一数据在分析索引是否被有效使用时提供参考。
-
idx_tup_fetch (tuples_fetched): 通过该索引实际提取的元组数量,同样是用于了解索引的使用情况。
FROM 和 JOIN 子句:
sys_stat_user_indexes: 系统视图,包含用户表上所有索引的统计信息。
sys_index: 系统表,包含索引的定义信息。
JOIN sys_index ON sys_stat_user_indexes.indexrelid = sys_index.indexrelid: 通过索引的唯一标识符indexrelid 将 sys_stat_user_indexes 和 sys_index 连接起来,以获取更多关于索引的详细信息。
WHERE idx_scan = 0: 只选择那些扫描次数为零的索引,即那些从未被使用过的索引。
通过这种方式,可以识别出那些在实际应用中没有发挥作用的索引,并对它们进行优化或删除。删除未使用的索引可以节省磁盘空间,减少数据库在执行写操作时的额外负担。
4. 查询表的大小
SELECT relname AS table_name,
sys_size_pretty(sys_total_relation_size(relid)) AS total_size,
sys_size_pretty(sys_relation_size(relid)) AS data_size,
sys_size_pretty(sys_total_relation_size(relid) - sys_relation_size(relid)) AS index_size
FROM sys_catalog.sys_statio_user_tables;

这段SQL代码用于识别Kingbase数据库中从未使用过的索引。未被使用的索引不仅不会提升性能,反而占用存储并增加写操作的负担,因此识别并删除这些冗余索引对优化数据库性能非常重要。
各字段作用如下:
- relname (table_name): 索引所属表的名称。
indexrelname (index_name): 索引名称。
idx_scan (index_scans): 索引被扫描的次数,idx_scan = 0表示索引未使用。
idx_tup_read (tuples_read): 通过该索引读取的元组数量。
idx_tup_fetch (tuples_fetched): 实际提取的元组数量。
FROM 和 JOIN 子句:
sys_stat_user_indexes: 包含用户表索引的统计信息。
sys_index: 包含索引的定义信息。
JOIN sys_index ON sys_stat_user_indexes.indexrelid = sys_index.indexrelid: 连接索引统计信息和定义信息。
WHERE idx_scan = 0: 只选择未被使用的索引。
这种方法可以识别无用索引,优化或删除它们,从而节省存储空间并减少写操作的负担
5. 查看表膨胀(bloat)情况
with table_bloat as (
select schemaname,
relname as tblname,
relpages as real_size,
(relpages - est_tblpages) as extra_size,
case when relpages = 0 then 0 else
100 * (relpages - est_tblpages)::float / relpages::float
end as extra_ratio
from (
select ceil(reltuples / floor((bs - 24) / (tuplehdr + ma))) as est_tblpages,
relpages,
reltuples,
relname,
nspname as schemaname,
bs,
tuplehdr,
ma
from (
select c.relpages,
c.relname,
n.nspname,
c.reltuples,
current_setting('block_size')::int as bs,
t.typalign,
t.typlen,
(case when typalign = 'd' then 8 else 4 end) + case when typlen = -1 then 4 else typlen end as tuplehdr,
(case when typalign = 'd' then 8 else 4 end) as ma
from sys_class c
join sys_namespace n on n.oid = c.relnamespace
join sys_attribute a on a.attrelid = c.oid
join sys_type t on a.atttypid = t.oid
where c.relkind = 'r'
and n.nspname not in ('sys_catalog', 'information_schema')
) as subquery
) as bst
)
select schemaname,
tblname,
sys_size_pretty(extra_size::bigint) as bloat_size,
extra_ratio as bloat_percentage
from table_bloat
where extra_ratio > 10
order by extra_ratio desc;
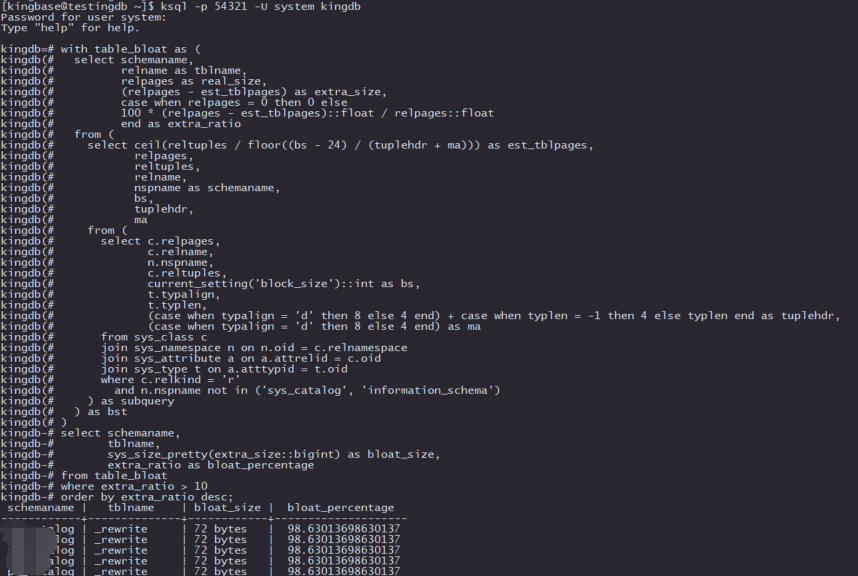
这段SQL代码用于识别Kingbase数据库中存在膨胀(bloat)的表,帮助数据库管理员优化存储使用情况。膨胀是指表中由于删除或更新操作导致的未使用空间,可能会降低性能并浪费存储资源。
该SQL使用了一个CTE(公共表表达式)table_bloat,计算每个表的实际大小与估计需要的大小之间的差异,从而评估表的膨胀程度。
各字段的作用如下:
schemaname: 表所属的模式(schema)名称。
tblname: 表的名称。
real_size (relpages): 表的实际页数,即表在存储中的大小(以数据页为单位)。
extra_size: 估计的膨胀空间,即表的实际大小与预估所需大小之间的差异。
extra_ratio: 膨胀比例,表示膨胀空间占表总大小的百分比。
通过计算extra_ratio,过滤出膨胀比例大于10%的表,以便数据库管理员可以优先考虑优化这些表。
该SQL查询的流程如下:
- 估算表的页数: 使用表的元数据(如元组数量、块大小等)来估算表的所需存储页数。
- 计算膨胀空间: 通过实际页数减去估算的页数,得到多余的页数,即膨胀空间。
- 过滤膨胀比例: 选择膨胀比例大于10%的表,按膨胀比例从大到小排序。
最终结果包括以下字段:
- schemaname: 表所在的模式名称。
- tblname: 表的名称。
- bloat_size: 格式化后的膨胀大小,以易于阅读的形式显示(如KB、MB)。
- bloat_percentage: 膨胀比例。
总结
这段SQL用于查找Kingbase数据库中膨胀比例较高的表,帮助数据库管理员识别需要优化的表,以减少存储浪费和提升性能。膨胀会导致无用空间增加,进而影响查询效率和存储利用率。因此,及时发现并处理这些表,有助于保持数据库的高效运行。
6. 查看表和索引的自动真空情况
select schemaname,
relname,
last_vacuum,
last_autovacuum,
last_analyze,
last_autoanalyze
from sys_stat_user_tables
order by last_autovacuum desc;
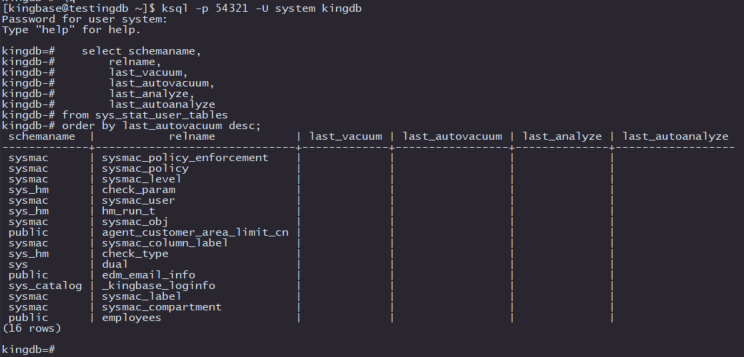
这段SQL代码用于查询 kingbaseES 数据库中用户表的自动维护操作信息,包括表的最后一次VACUUM和ANALYZE操作时间。它可以帮助数据库管理员了解表的维护状态,以确保数据库性能的持续稳定。
该SQL查询了sys_stat_user_tables系统视图,通过以下字段来提供表的维护信息:
-
schemaname: 表所属的模式(schema)名称。
-
relname: 表的名称。
-
last_vacuum: 上次手动执行VACUUM操作的时间,用于释放表中的未使用空间并减少膨胀。
-
last_autovacuum: 上次自动执行VACUUM操作的时间,通常由 kingbaseES 的autovacuum进程自动触发。
-
last_analyze: 上次手动执行ANALYZE操作的时间,用于更新表的统计信息,以便优化查询计划。
-
last_autoanalyze: 上次自动执行ANALYZE操作的时间,通常由 kingbaseES 的autovacuum进程自动触发。
-
ORDER BY last_autovacuum DESC: 按照last_autovacuum的时间降序排列,以便优先查看最近自动执行VACUUM操作的表。
总结
这段SQL用于获取 kingbaseES 数据库中各个用户表的最后一次维护操作信息,帮助数据库管理员判断哪些表需要手动进行VACUUM或ANALYZE操作,以确保数据库的高效运行。对数据库维护操作的监控和优化,通过定期执行这些维护任务,可以减少膨胀、优化查询性能,从而提高数据库的整体效率。
7. 实时监控锁的使用
select sys_stat_activity.datname,
sys_locks.pid,
sys_locks.locktype,
sys_locks.mode,
sys_locks.granted,
sys_stat_activity.query,
sys_stat_activity.query_start
from sys_stat_activity
join sys_locks
on sys_stat_activity.pid = sys_locks.pid
where sys_stat_activity.state <> 'idle';

这段SQL代码用于监控 kingbaseES 数据库中正在运行的查询和相关锁信息,帮助数据库管理员识别可能导致性能瓶颈的锁争用问题。
该SQL通过查询sys_stat_activity和sys_locks系统视图,获取与当前活动会话相关的锁信息,具体字段作用如下:
- sys_stat_activity.datname: 数据库名称,指明当前会话所属的数据库。
- sys_locks.pid: 获取持有锁的进程ID,用于唯一标识数据库中的活动进程。
- sys_locks.locktype: 锁的类型,描述了所持有的锁的具体类型,例如关系锁(relation)、页锁(page)等。
- sys_locks.mode: 锁的模式,描述了持有锁的访问级别,如共享锁(Share)、排他锁(Exclusive)等。
- sys_locks.granted: 表示该锁是否已被授予,true表示锁已授予,false表示锁正在等待。
- sys_stat_activity.query: 当前会话正在执行的SQL查询文本,便于了解锁争用发生时,具体的操作内容。
- sys_stat_activity.query_start: 查询的开始时间,用于判断查询的持续时间。
- WHERE sys_stat_activity.state <> ‘idle’: 只选择当前非空闲状态的会话,过滤掉没有活动查询的连接。
总结
这段SQL用于查看 kingbaseES 数据库中活动会话的锁情况,通过关联查询活动和锁信息,帮助数据库管理员识别和解决锁争用导致的性能问题。尤其在并发访问较高的场景下,锁争用是导致性能下降的常见原因。
8. 监控表的缓存命中率
select relname as table_name,
heap_blks_read,
heap_blks_hit,
case
when (heap_blks_hit + heap_blks_read) = 0 then 0
else heap_blks_hit * 100 / (heap_blks_hit + heap_blks_read)
end as cache_hit_ratio
from sys_statio_user_tables
order by cache_hit_ratio desc;
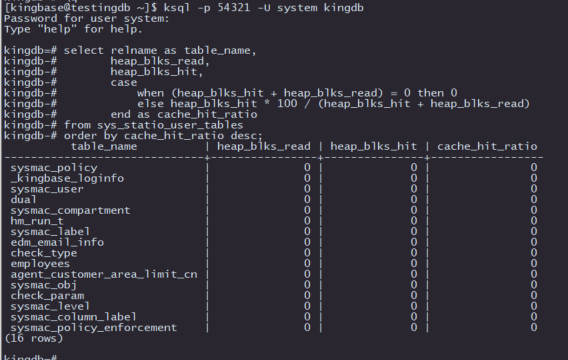
这段SQL代码用于计算 kingbaseES 数据库中用户表的缓存命中率,以帮助数据库管理员分析表的I/O性能,判断是否存在需要优化的表。
该SQL查询了sys_statio_user_tables系统视图,获取每个用户表的缓存命中情况,具体字段作用如下:
- relname (table_name): 表的名称。
- heap_blks_read: 从磁盘读取的数据块数量,表示发生物理I/O的次数。
- heap_blks_hit: 在共享缓冲区(内存)中命中的数据块数量,表示通过缓存读取的次数。
- cache_hit_ratio: 缓存命中率,表示表的数据请求中有多少是直接从内存中命中而无需访问磁盘。通过公式heap_blks_hit * 100 / (heap_blks_hit + heap_blks_read) 计算得出,避免了对无数据访问的表进行除零操作。
ORDER BY cache_hit_ratio DESC: 按照缓存命中率降序排列,以便优先查看缓存命中率较高的表。
总结
这段SQL用于计算 kingbaseES 数据库中用户表的缓存命中率,通过分析每个表的缓存使用情况,帮助数据库管理员识别出需要优化的表。例如,较低的缓存命中率可能意味着表的数据较少被缓存,从而导致更多的磁盘I/O操作。
9. 查询WAL日志生成量
select date_trunc('hour', now()) as hour,
count(*) as wal_count
from sys_ls_waldir()
where modification > now() - interval '1 day'
group by 1
order by 1 desc;
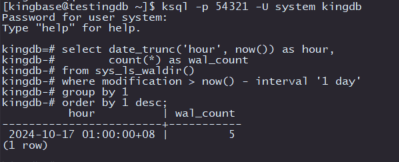
这段SQL代码用于计算 kingbaseES 数据库中最近一天内每小时生成的WAL(Write-Ahead Logging)文件数量,以帮助数据库管理员了解WAL的生成频率,从而评估系统的写入活动。
- 该SQL查询了sys_ls_waldir()函数,获取WAL目录中的文件修改情况,具体字段作用如下:
- date_trunc(‘hour’, now()) as hour: 截断当前时间到小时级别,用于按小时进行统计。
- count(*) as wal_count: 统计在最近一天内WAL目录中修改的文件数量。
- modification > now() - interval ‘1 day’: 过滤条件,选择最近一天内发生修改的WAL文件。
- GROUP BY 1: 按照小时分组,以计算每小时的WAL文件数量。
- ORDER BY 1 DESC: 按照时间降序排列,以便优先查看最近的WAL生成情况。
总结
这段SQL用于获取 kingbaseES 数据库中每小时生成的WAL文件数量,通过分析每小时的WAL生成情况,帮助数据库管理员识别写入负载的变化趋势。例如,WAL生成频繁可能意味着大量写操作,数据库管理员可以根据这些信息调整系统的写入策略。
