




前言
本篇介绍下HaloDB中的ORALCE模式下如何自定义存储过程。
广告时间:
杭州易景数通科技联合创始人章晨曦先生近日接受了中央电视台的采访(没错,有实力就是要炫耀^_^)
如果有对我们的产品感兴趣的朋友可以通过主页的联系方式与我取得联系,获取license来安装体验,目前已经开通HaloDB吐槽群,欢迎来喷,进群请私聊我获取。

一、简单聊聊自定义存储过程
自定义存储过程在数据库应用中具有多个显著的优点,这些优点主要体现在性能、安全性、可维护性、代码重用性等方面。以下是自定义存储过程的一些主要优点:
提高安全性:
- 限制直接数据访问:通过存储过程封装数据库操作,可以控制哪些用户能够执行哪些操作,限制对基础数据的直接访问。这有助于防止未经授权的数据修改和泄露。
- 输入验证:在存储过程内部可以实施严格的输入验证,确保传入的数据符合预期的格式和范围,从而防止SQL注入等安全漏洞。
代码重用性:
- 存储过程可以被多个应用程序或用户共享和重用。一旦编写并测试了存储过程,它就可以被多个地方调用,而无需在每个地方都编写相同的逻辑。这不仅减少了代码重复,还提高了代码的一致性和可维护性。
业务逻辑封装:
- 存储过程可以封装复杂的业务逻辑,使得数据库操作更加模块化和易于管理。应用程序只需调用相应的存储过程,而无需关心其背后的复杂逻辑。
支持事务处理:
- 存储过程内部可以包含完整的事务处理逻辑,包括事务的开始、提交和回滚。这有助于确保数据的一致性和完整性,特别是在执行涉及多个表和步骤的复杂操作时。
提高开发效率:
- 存储过程的编写和调试通常在数据库层面进行,这有助于数据库管理员和开发人员更好地协作。同时,由于存储过程减少了应用程序层面的代码量,因此可以缩短开发周期并降低开发成本。
易于维护和升级:
- 当业务逻辑发生变化时,只需修改存储过程即可,而无需修改多个应用程序中的代码。这简化了维护过程,并降低了升级过程中的风险。
二、HaloDB中创建与使用自定义存储过程
前提条件:
- 数据库参数database_compat_mode已设置为oracle
- 数据库参数standard_parserengine_auxiliary已设置为on
- aux_oracle扩展已安装
- 数据库服务已重新启动
测试用例:
CREATE OR REPLACE PROCEDURE Discount AS CURSOR c_group_discount IS SELECT s.course_no, c.description FROM section s JOIN enrollment e ON s.section_id = e.section_id JOIN course c ON c.course_no = s.course_no GROUP BY s.course_no, c.description HAVING COUNT(DISTINCT e.student_id) >= 8; -- 假设使用student_id来确保学生不重复计数 BEGIN FOR r_group_discount IN c_group_discount LOOP UPDATE course SET cost = cost * 0.95 WHERE course_no = r_group_discount.course_no; DBMS_OUTPUT.PUT_LINE('A 5% discount has been given to ' || r_group_discount.course_no || ' ' || r_group_discount.description); END LOOP; COMMIT; -- 添加COMMIT来确保更改被提交到数据库 END; /复制
执行结果如下: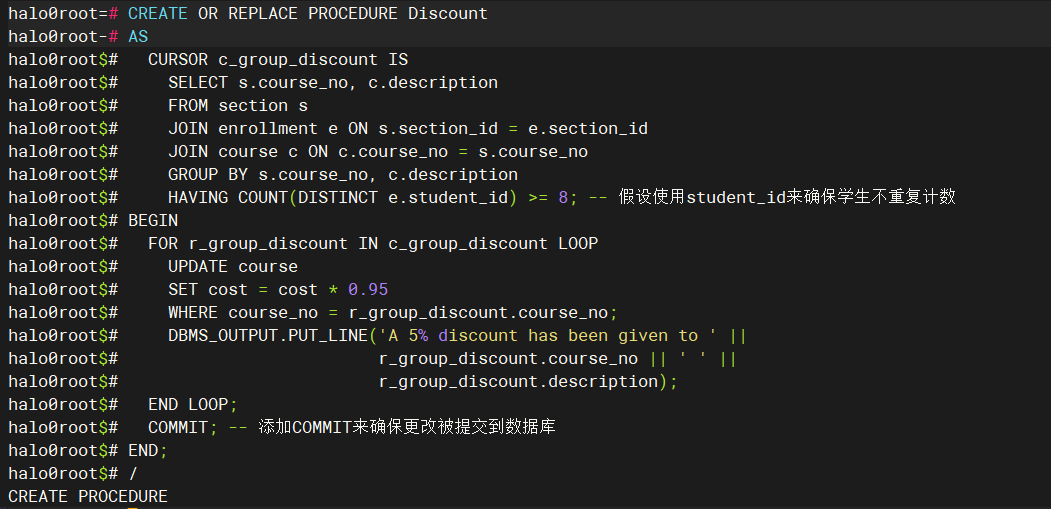
上面的这个测试用例其实就是定义了一个名为Discount的存储过程,这个存储过程的作用是自动查找那些至少有8个不同学生报名的课程,并将这些课程的费用降低5%,同时输出已经打折的课程信息。游标的部分,使用For LOOP来遍历游标c_group_discount返回的结果集。对于结果集中的每一行,都会执行循环体内的代码。这样做的好处就是可以自动化一些常见的业务逻辑,减少人工干预,并可能提高数据处理的效率和准确性。
我们再看一个例子:
CREATE OR REPLACE PROCEDURE find_sname (i_student_id IN NUMBER, o_first_name OUT VARCHAR2, o_last_name OUT VARCHAR2 ) AS BEGIN SELECT first_name, last_name INTO o_first_name, o_last_name FROM student WHERE student_id = i_student_id; EXCEPTION WHEN OTHERS THEN DBMS_OUTPUT.PUT_LINE('Error in finding student_id: '||i_student_id); END find_sname; / DECLARE v_local_first_name student.first_name%TYPE; v_local_last_name student.last_name%TYPE; BEGIN find_sname (145, v_local_first_name, v_local_last_name); DBMS_OUTPUT.PUT_LINE ('Student 145 is: '||v_local_first_name|| ' '|| v_local_last_name||'.' ); END; /复制
HaloDB中执行结果如下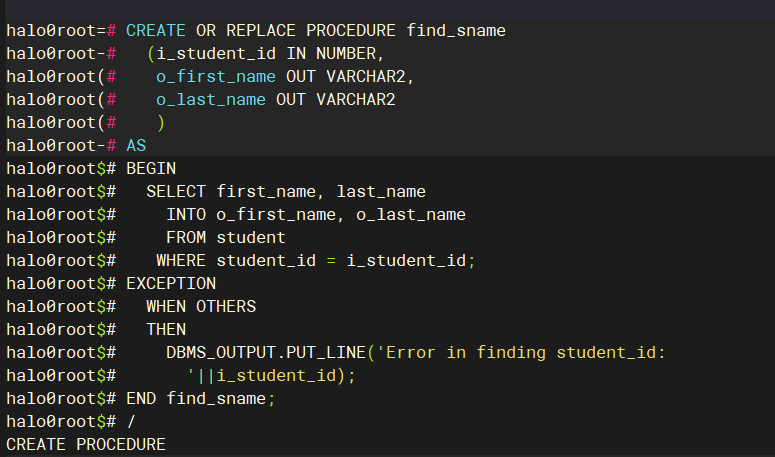
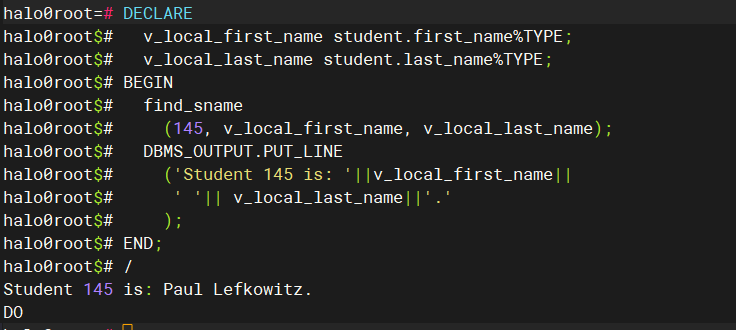
上面的这个例子,我定义了一个名为find_sname的存储过程,用于根据学生ID查询并返回学生名字和姓氏。接收一个学生ID作为输入,执行数据库查询以获取对应学生的名字和姓氏,并通过输出参数返回这些信息。如果查询未找到匹配的学生,则捕获异常并通知调用者,同时将输出参数设置为空值或默认值。
二、HaloDB中的游标
什么是游标:
数据库游标(Cursor)是数据库系统中用于处理查询结果集的一种重要机制。它允许应用程序对查询结果集中的行进行逐行处理。游标提供了对查询结果集进行遍历的能力,使得开发者可以在存储过程、触发器或者其他数据库编程环境中,对结果集中的每一行数据进行读取、修改或删除操作。
游标的工作原理类似于编程中的迭代器或指针,但它专门用于数据库操作。当执行一个SQL查询时,数据库管理系统(DBMS)会返回一个结果集,这个结果集包含了查询所匹配的所有行。游标被用来遍历这个结果集,每次处理一行数据。
游标的主要特点:
- 逐行处理 :游标允许开发者编写能够逐行处理查询结果的代码,这在处理大量数据时特别有用,因为它可以减少内存的使用,避免一次性加载整个结果集。
- 灵活性:游标提供了灵活的数据处理机制,可以在存储过程或触发器中根据业务逻辑对每一行数据进行复杂的操作。
- 状态控制:游标具有状态属性,如%FOUND、%NOTFOUND和%ROWCOUNT,这些属性可以帮助开发者控制遍历过程,例如检查是否还有更多行可以处理。
- 资源消耗:然而,游标的使用也会带来一定的资源消耗,因为DBMS需要为游标分配内存和管理上下文切换。因此,在不需要逐行处理结果集的情况下,应避免使用游标。
游标的使用场景:
- 当需要对查询结果集中的每一行数据进行复杂处理时。
- 当需要基于当前行的数据来决定如何处理下一行时。
- 当需要逐行更新或删除查询结果集中的行时。
游标的基本操作:
- 声明游标:指定游标将要执行的SQL查询。
- 打开游标:执行SQL查询,并准备结果集供后续操作。
- 提取数据:使用FETCH语句逐行从结果集中提取数据。
- 关闭游标:完成数据操作后,关闭游标以释放数据库资源。
隐式游标在HaloDB中的使用:
DECLARE v_first_name VARCHAR2(35); v_last_name VARCHAR2(35); BEGIN SELECT first_name, last_name INTO v_first_name, v_last_name FROM student WHERE student_id = 392; DBMS_OUTPUT.PUT_LINE ('Student name: '|| v_first_name||' '||v_last_name); EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE ('There is no student with student ID 392'); END; /复制
执行结果如下: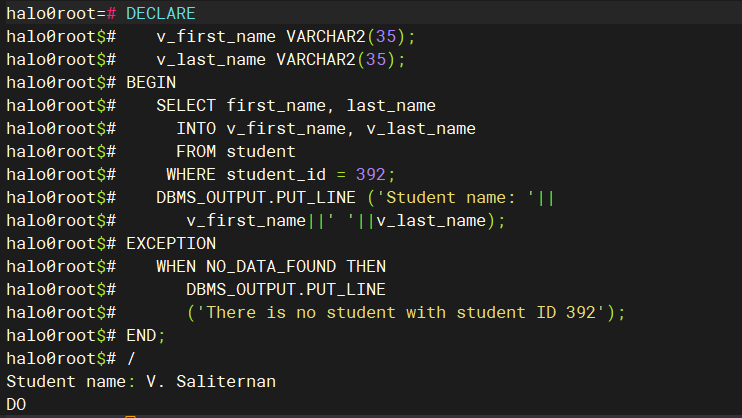
上面的PL/SQL表达的是在student表中检索学生ID为392的学生的名字和姓氏,并将这些信息输出到DBMS_OUTPUT中。如果在student表中找不到具有该ID的学生,就将捕获NO_DATA_FOUND异常并输出相应的消息。
显式游标在HaloDB中的使用::
DECLARE CURSOR c_zip IS SELECT * FROM zipcode; vr_zip c_zip%ROWTYPE; BEGIN OPEN c_zip; LOOP FETCH c_zip INTO vr_zip; EXIT WHEN c_zip%NOTFOUND; -- 退出循环,如果没有更多行 -- 如果找到了数据,则输出 DBMS_OUTPUT.PUT_LINE(vr_zip.zip || ' ' || vr_zip.city || ' ' || vr_zip.state); END LOOP; CLOSE c_zip; -- 显式关闭游标以释放资源 END; /复制
执行结果如下:
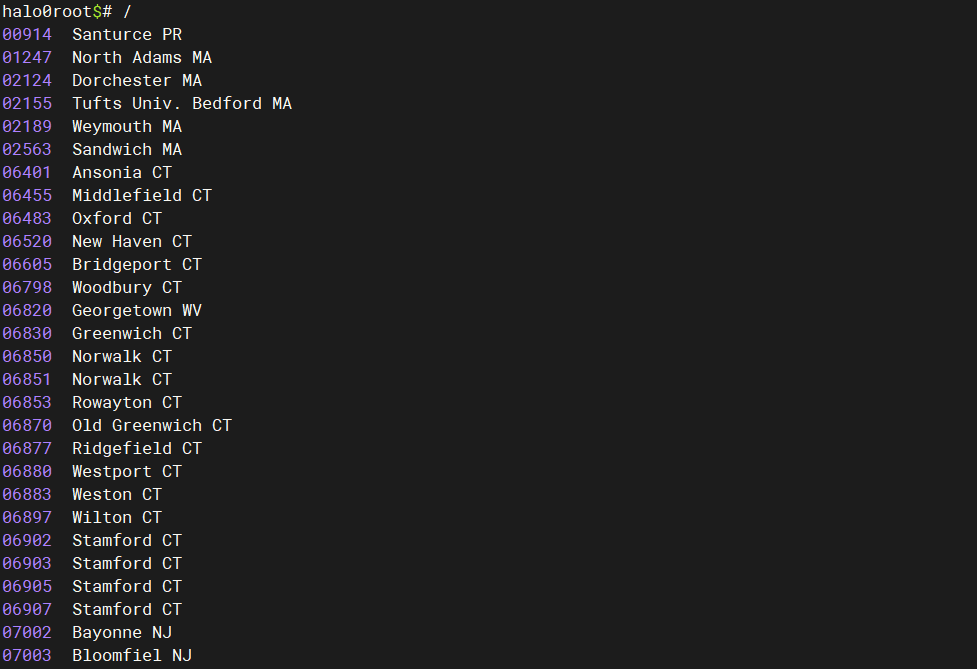
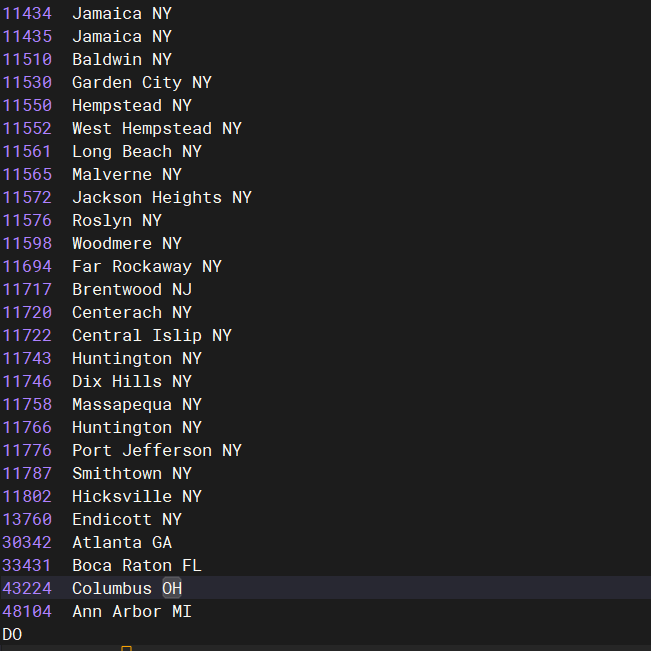
上面的PL/SQL首先遍历zipcode表中的所有记录,对于表中的每一行(或称为每一条记录),它都会提取出该行的邮政编码(zip)、城市名(city)和州名(state),并将这些信息输出到DBMS_OUTPUT中。当表中的所有记录都被遍历并输出后,游标c_zip关闭,释放数据库资源。



