




背景概述
我们都知道计算机是不能直接存储字母,数字,图片,符号等,计算机能处理和工作的唯一单位是“比特位(bytes)”,一个比特位通常只有0和1,是(yes)和否(no),真(true)或者假(false)等等我们喜欢的称呼。利用比特位序列来代表字母,数字,图片,符号等,我们就需要一个存储规则,不同的比特序列代表不同的字符,这就是所谓的“编码”。反之,将存储在计算机中的比特位序列(或者叫二进制序列)解析显示出来成对应的字母,数字,图片和符号,称为"解码"。提到编码不得不说到字符集,因为任何一种编码方式都会有一个字符集与之对应。
然而计算机领域通常所讲的字符集实际上是指字符编码集,而不是传统意义上的字符库,除了包括一个系统支持的所有抽象字符(如国家文字、标点符号、图形符号、数字等)外,还包括字符所对应的一个数值,所以通常是一个二维表,下文提到的字符集都是指字符编码集。常见字符集如ASCII字符集、ISO-8859-X、GB2312字符集(简中)、BIG5字符集(繁中)、GB18030字符集、Shift-JIS等等。之前的很长一段时间内,字符集和字符编码区分不是很严格,因为一般一种字符集只对应一种编码方式,但是这些编码方式存在下面的问题:
没有一种编码可以覆盖全世界所有国家的字符;
各种编码之间也会存在冲突的现象,两种不同编码方式可能使用同一个编码代表不同的字符,亦或用不同的编码代表同一个字符;
一个指定的机器(比如我们的服务器)将需要支持许多不同的编码方式,当数据在不同的机器之间传输或者在不同的编码之间转换时,很容易产生乱码问题。
多语言软件制造商组成的统一码联盟(The Unicode Consortium)于1991年发布的统一码标准(The Unicode Standard),定义了一个全球统一的通用字符集即Unicode字符集解决了上述的问题。统一码标准为每个字符提供一个唯一的编号,旨在支持世界各地的交流,处理和显示现代世界各种语言和技术学科的书面文本。此外,它支持许多书面语言的古典和历史文本,不管是什么平台,设备,应用程序或语言,都不会造成乱码问题, 它已被所有现代软件供应商采用,是目前所有主流操作系统,搜索引擎,浏览器,笔记本电脑和智能手机以及互联网和万维网(URL,HTML,XML,CSS,JSON等)中表示语言和符号的基础。统一码标准的一个版本由核心规范、Unicode标准、代码图、Unicode标准附件以及Unicode字符数据库(Unicode Character Database 简写成UCD)组成,同时也是开发的字符集,在不断的更加和增加新的字符,最新的版本为Unicode 10.0.0。
在Unicode字符集发布的第三年,ISO/IEC联合发布了通用多八位编码字符集简称为UCS(Universal Character Set通用字符集),也旨在使用全球统一的通用字符集。两套通用字符集使用起来又存在麻烦,后来统一码联盟与ISO/IEC经过协商,到到Unicode 2.0时,Unicode字符集和UCS字符集基本保持了一致。现在虽然双方都发布各自的版本,但两套字符集是相互兼容的,Unicode字符集使用比UCS字符集更加广泛。
Unicode介绍
世界经济日益全球化的同时,一个应用程序需要在全球范围内使用势在必然,基于Unicode的应用程序能够很好地处理来自世界各地的用户文本,并适应其文化习俗。它通过消除每种语言的构建,安装和维护更新来最大限度地降低成本。Unicode(与其并行ISO 10646标准)标准除了覆盖全球所有地区国家使用的字符外,它还定义了一系列文本处理的数据和算法,极大简化了Unicode的应用,并确保所有遵守其标准的软件产生相同的结果。在过去十年的广泛应用中,Unicode成为互联网的基石。
Unicode编码字符集旨在收集全球所有的字符,为每个字符分配唯一的字符编号即代码点(Code Point),用U+紧跟着十六进制数表示。所有字符按照使用上的频繁度划分为17个平面(编号为0-16),即基本的多语言平面和增补平面。基本的多语言平面(英文为Basic Multilingual Plane,简称BMP)又称平面0,收集了使用最广泛的字符,代码点从U+0000到 U+FFFF,每个平面有216=65536个码点;增补平面从平面1~16,分为增补多语言平面(平面1)、增补象形平面(平面2)、保留平面(平3~13)、增补专用平面等,每个增补平面也有216=65536个码点。所以17个平总计有17 × 65,536 = 1,114,112个码点。图1是Unicode平面分布图,图2是Unicode各个平面码点空间。
图 1. Unicode 17个平面分布
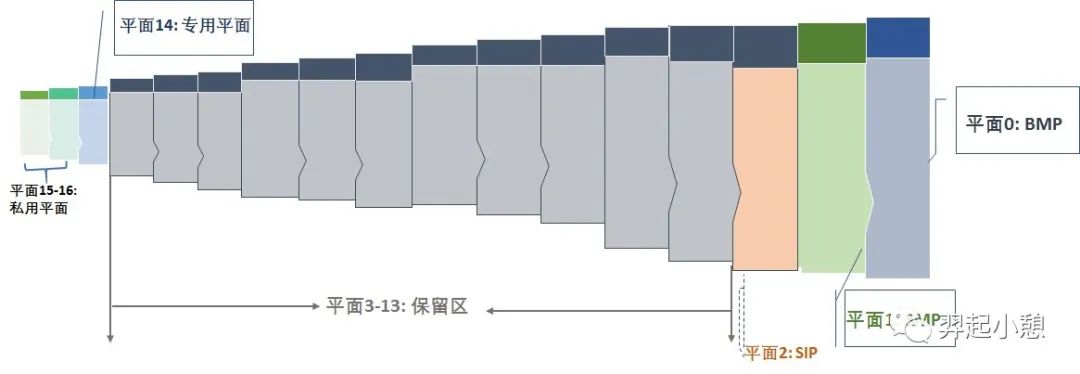
图 2. Unicode平面分布和码点空间
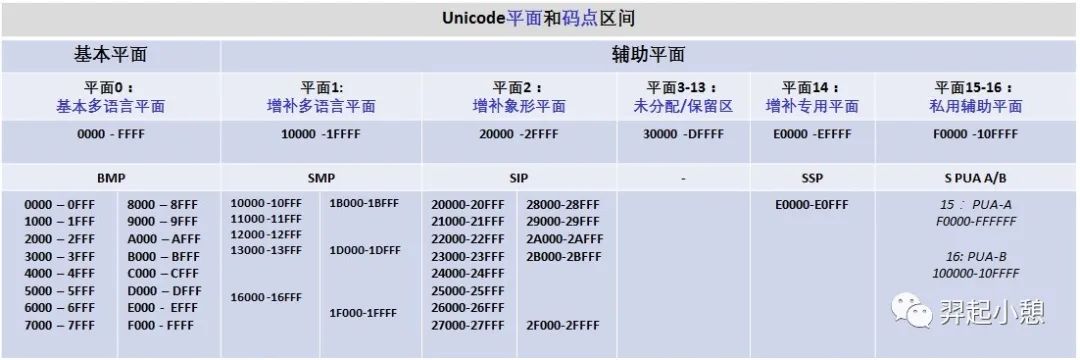
下面是一些相关术语的解释:
Coded Character Set(CCS):即编码字符集,给字符表里的抽象字符编上一个数字,也就是字符集合到一个整数集合的映射。这种映射称为编码字符集,Unicode字符集就是属于这一层的概念;
Character Encoding Form(CEF):即字符编码表,根据一定的算法,将编码字符集(CCS) 中字符对应的码点转换成一定长度的二进制序列,以便于计算机处理,这个对应关系被称为字符编码表,UTF-8、 UTF-16 属于这层概念;
Code Point: 码点,简单理解就是字符的数字表示。一个字符集一般可以用一张或多张由多个行和多个列所构成的二维表来表示。二维表中行与列交叉的点称之为码点,每个码点分配一个唯一的编号,称之为码点值或码点编号,除开某些特殊区域(比如代理区、专用区)的非字符码点和保留码点,每个码点唯一对应于一个字符。
Code Unit:代码单元,是指一个已编码的文本中具有最短的比特组合的单元。对于UTF-8来说,代码单元是8比特长;对于UTF-16来说,代码单元是16比特长。换一种说法就是UTF-8的是以一个字节为最小单位的,UTF-16是以两个字节为最小单位的。
Code Space:码点空间,字符集中所有码点的集合。
BOM(Byte Order Mark):字节序,出现在文件头部,表示字节的顺序,第一个字节在前,就是“大头方式”(Big-Endian),第二个字节在前就是“小头方式”(Little-Endian)。这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》,在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-Endian)敲开还是从小头(Little-Endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
Unicode几种常见编码方式
Unicode字符集中的字符可以有多种不同的编码方式,如UTF-8、UTF-16、UTF-32、压缩转换等。这里的UTF是Unicode transformation format的缩写,即统一码转换格式,将Unicode编码空间中每个码点和字节序列进行一一映射的算法。下面详细介绍一下这三种常见的Unicode编码方式。
UTF-8
UTF-8是一种变长的编码方式,一般用1~4个字节序列来表示Unicode字符,也是目前应用最广泛的一种Unicode编码方式,但是它不是最早的Unicode编码方式,最早的Unicode编码方式是UTF-16。UTF-8编码算法有以下特点:
首字节码用来区分采用的编码字节数:如果首字节以0开头,表示单字节编码;如果首字节以110开头,表示双字节编码;如果首字节以1110开头,表示三字节编码,以此类推;
除了首字节码外,用10开头表示多字节编码的后续字节,图3列出UTF-8用1~6个字节所表示的编码方式和码点范围(实际上1~4个字节基本可以覆盖大部分Unicode码点);
与ASCII编码方式完全兼容:U+0000到U+007F范围内(十进制为0~127)的Unicode码点值所对应的字符就是ASCII字符集中的字符,用一个字节表示,编码方式和ASCII编码一致;
无字节序,在UFT-8编码格式的文本中,如果添加了BOM,则标示该文本是由UTF-8编码方式编码的,而不用来说明字节序。
图 3. UTF-8编码方式
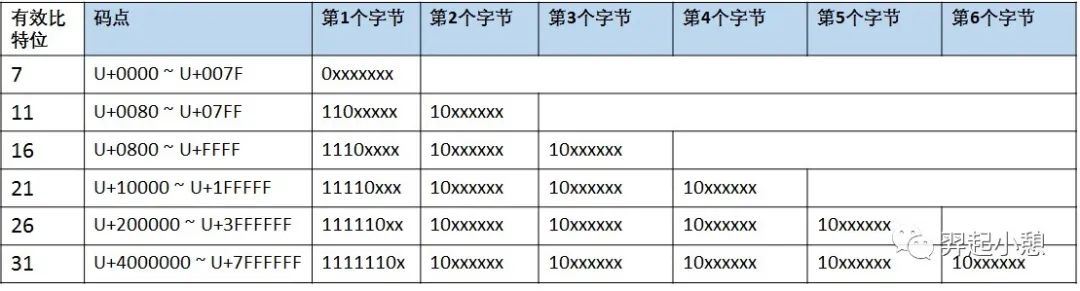
在实际的解码过程中:
情况1:读取到一个字节的首位为0,表示这是一个单字节编码的ASCII字符;
情况2:读取到一个字节的首位为1,表示这是一个多字节编码的字符,如继续读到1,则确定这是首字节,在继续读取直到遇到0为止,一共读取了几个1,就表示在字符为几个字节的编码;
情况3:当读取到一个字节的首位为1,紧接着读取到一个0,则该字节是多字节编码的后续字节。
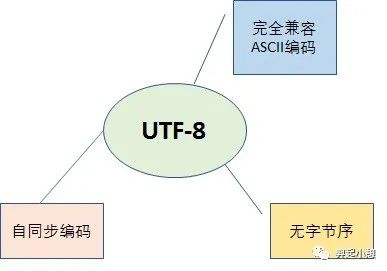
图4概述了UTF-8编码方式的特点,其中的“自同步”表示在传输过程中如果有字节序列丢失,并不会造成任何乱码现象,或者存在错误的字节序列也不会影响其他字节的正常读取。例如读取了一个10xxxxxx开头的字节,但是找不到首字节,就可以将这个后续字节丢弃,因为它没有意义,但是其他的编码方式,这种情况下就很可能读到一个完全不同或者错误的字符。
图 4. UTF-8编码方式
UTF-16
UTF-16是最早的Unicode字符集编码方式,在概述UTF-16之前,需要解释一下USC-2编码方式,他们有源远流长的关系,UTF-16源于UCS-2。UCS-2将字符编号(同Unicode中的码点)直接映射为字符编码,亦即字符编号就是字符编码,中间没有经过特别的编码算法转换。图5对UCS-2编码方式的概括。
图 5. UCS-2编码方式
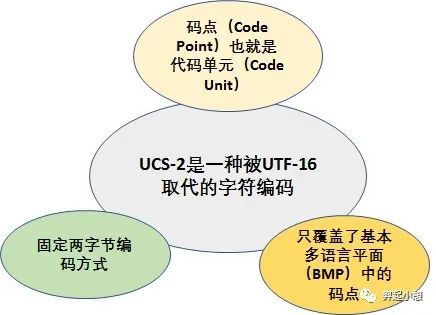
由图5可知,UCS-2编码方式只覆盖基本多语言平面的码点,因为16位二进制表示的最大值为0xFFFF,而对于增补平面中的码点(范围为0x10000~0x10FFFF,十进制为65536~1114111),两字节的16位二进制是无法表示的。为了解决这个问题,The Unicode Consortium 提出了通过代理机制来扩展原来的UCS-2编码方式,也就是UTF-16。其编码算法如下:
基本多语言平面(BMP)中有效码点用固定两字节的16位代码单元为其编码,其数值等于相应的码点,桶USC-2的编码方式;
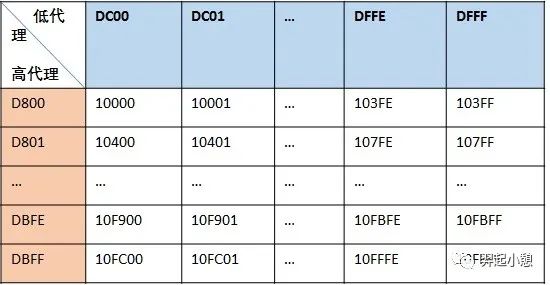
辅助多语言平面1-16中的有效码点采用代理对(surrogate pair)对其编码:用两个基本平面中未定义字符的码点合起来为增补平面中的码点编码,基本平面中这些用作“代理”的码点区域就被称之为“代理区(Surrogate Zone)”,其码点编号范围为0xD800~0xDFFF(十进制55296~57343),共2048个码点。代理区的码点又被分为高代理码点和低代理码点,高代理码点的取值范围为0xD800~0xDBFF,低代理码点的取值范围为0xDC00~0xDFFF,高代理码点和低代理码点合起来就是代理对,刚好可以表示增补平面内的所有码点,如图6所示。
图 6. UTF-16代理对
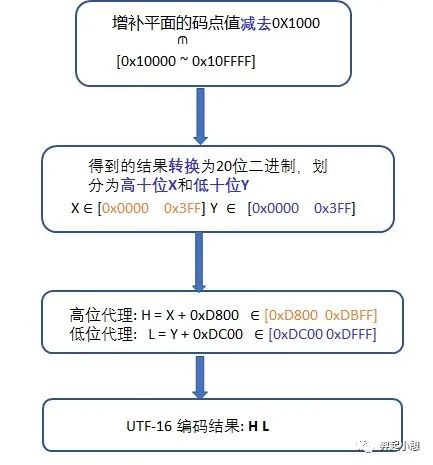
但是在实际的编码过程中通过查表是很麻烦的,图7列出了UTF-16编码算法是如何对增补平面中的码点进行编码的。
图 7. UTF-16编码算法剖析
UTF-16对增补平面中的码点编码还是很复杂的,但是由于UTF-16是最早的Unicode编码方式,已经存在于很多程序中。
UTF-32(UCS-4)
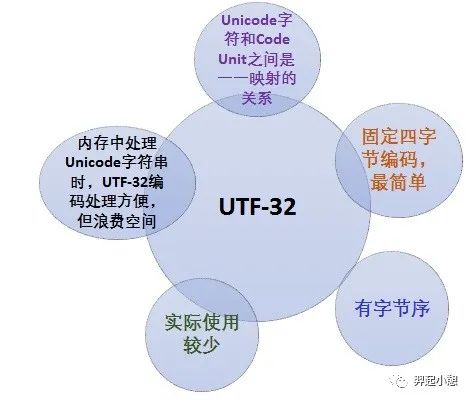
UTF-32是一个以固定四字节编码方式,ISO 10646中称其为UCS-4的编码机制的子集。优点是每一个Unicode码点都和UTF-16的Code Unit一一对应,程序中如果采用UTF-32处理起来比较简单,但是所有的字符都用四个字节,特别浪费空间,所以实际上使用比较少。其特性如图6所示。
图 8. UTF-32编码
UTF-16和UTF-32的最小Code Unit(编码单元)是双字节即16个比特位,即多字节编码方式,因此这两种编码方式都存在字节序标记(BOM)问题。
Big-Endian(BE)即大端序:就是高位字节(即大端字节)存放在内存的低地址,低位字节(即小端字节)存放在内存的高地址。UTF-16(BE)以FEFF作为开头字节,UTF-32(BE)以00 00 FE FF作为开头字节;
Little-Endian (LE)即小端序:低位字节(即小端字节)存放在内存的低地址,而高位字节(即大端字节)存放在内存的高地址。UTF-16(LE)以FFFE作为开头字节,UTF-32(LE)以FF FE 00 00作为开头字节。
UTF-8 不需要 BOM 来表明字节顺序:可以用 BOM(EF BB BF称为零宽无间断间隔)来表明编码方式,如果接收者收到以 EF BB BF 开头的字节流,就知道这是 UTF-8编码。
表1. Unicode编码方式中的BOM
UTF-8 | UTF-16 | UTF-16LE | UTF-16BE | UTF-32 | UTF-32LE | UTF-16BE | |
最小code point | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 | 0000 |
最大code point | 10FFFF | 10FFFF | 10FFFF | 10FFFF | 10FFFF | 10FFFF | 10FFFF |
Code Unit | 8 bits | 16 bits | 16 bits | 16 bits | 32 bits | 32 bits | 32 bits |
字节序 | N/A | BOM | 小端序 | 大端序 | BOM | 小端序 | 大端序 |
编码最小字节数 | 1 | 2 | 2 | 2 | 4 | 4 | 4 |
备注:表1中标着BOM的地方表示根据文本头部的字节序确定,如果没有字节序,默认为BE即大端序编码。表2是三种常见Unicode编码方式示例对比:
表2. Unicode编码示例
字符 | 码点 十六进制 | 码点 二进制 | 编码方式 | 编码序列 (二进制) | 编码序列 (十六进制) | |
基本 平面 | ¢ | U+00A2 | 1010 0010 | UTF-8 | 1100 0010 1010 0010 | C2 A2 |
UTF-16 | 0000 0000 1010 0010 | 00 A2(默认) | ||||
UTF-16BE | 00 A2 | |||||
UTF-16LE | A2 00 | |||||
UTF-32 | 0000 0000 0000 0000 0000 0000 1010 0010 | 00 00 00 A2(默认) | ||||
UTF-32BE | 00 00 00 A2 | |||||
UTF-32LE | 00 00 A2 00 | |||||
增补平面 | | U+24B62 | 0000 0010 0100 1011 0110 0010 | UTF-8 | 1111 0000 1010 0100 1010 1101 1010 0010 | F0 A4 AD A2 |
UTF-16 | 1101 1000 0101 0010 1101 1111 0110 0010 | D8 52 DF 62(默认) | ||||
UTF-16BE | D8 52 DF 62 | |||||
UTF-16LE | 52 D8 62 DF | |||||
UTF-32 | 0000 0000 0000 0010 0100 1011 0110 0010 | 00 02 4B 62(默认) | ||||
UTF-32BE | 00 02 4B 62 | |||||
UTF-32LE | 02 00 62 4B |
表3对三种编码方式从编码字节数,BOM以及优缺点几方面进行了对比。
表3. 三种编码方式的比较
编码 方式 | 编码 字节数 | BOM | 优点 | 缺点 |
UTF-8 | 不定长编码方式,单字节(ASCII字符)或多字节(非ASCII字符);最小Code Unit是8位 | 无字节序:如果一个文本的开头有字节流EF BB BF,表示是 UTF-8编码 | 较为理想的Unicode编码方式:与ASCII编码完全兼容;无字节序;自同步和纠错能力强,适合网络传输和通信;扩展性好 | 变长编码方式不利于程序内部处理, |
UTF-16 | 双字节(BMP字符)或者四字节(增补平面字符);最小Code Unit是16位 | 有字节序:UTF-16LE(小端序)以FF FE代表,UTF-16BE(大端序)以FE FF代表 | 最早的Unicode编码方式,已被应用于大量环境中;适合内存中Unicode处理;很多编程语言的API中作为string类型的编码方式 | 无法兼容于ASCII编码;增补平面码点编码使用代理对,编码复杂;扩展性差 |
UTF-32 | 固定四字节;最小Code Unit是16位 | 有字节序:UTF-16LE(小端序)以FF FE代表,UTF-16BE(大端序)以FE FF代表 | 固定字节编码读取简单,编译程序内部处理;Unicode码点和Code Unit一一对应关系 | 所有字符以固定四字节编码,浪费存储空间和带宽;与ASCII编码不兼容;扩展性差;实际使用少 |
ICU及ICU4J
ICU (International Components for Unicode) 是一套成熟的、功能强大、易用和跨平台支持Unicode标准的C/C++和Java库,为软件应用程序提供对最新Unicode标准和全球化支持。并且是开放源代码的,IBM 与开源组织合作研究,由IBM发布和维护。软件开发者很容易利用ICU解决任何软件全球化的问题,根据各地的风俗语言习惯,实现对数字、货币、时间、日期等格式化和解析;对字符串进行转换、搜索和排序等功能,此外,ICU也提供了对双向字符串(BIDI)算法,对如阿拉伯语和希伯来语有很好的支持。ICU分为ICU4C和ICU4J,分别对应Java和C/C++平台。
对于Java应用程序,ICU4J逐渐取代了JDK提供的相关功能,因为ICU4J提供了更多的功能,如基于CLDR数据库的Locale信息、最新Unicode标准的参考实现、实时的版本更新以及较高的性能。最新的ICU4J版本是60.2,对最新的Unicode标准Unicode 10.0,CLDR 32有很好的支持,并且在Java 9上进行了测试,用于数字格式化的新API更加注重于可用性,健壮性,表4列出了ICU4J提供的常用功能及其API。
表4. ICU4J功能列表
功能列表 | 功能介绍 | API |
Unicode文本 处理 | 支持Unicode标准规定中的所有Unicode字符属性 | UCharacter, UCharacter,UnicodeBlock |
排序&查找 | 根据特定语言,地区或国家的惯例和标准比较字符串。ICU的排序规则是基于Unicode排序算法以及来自Common Locale Data Repository的语言环境特定比较规则 | CollationElementIterator, Collator RuleBasedCollator |
基于CLDR库的Locale | Unicode通用语言环境数据存储库。由Unicode联合会(http://www.unicode.org/cldr/)维护的XML格式的语言环境数据库。该存储库提供软件产品本地化所需的信息,包括日期,时间,数量和货币格式; 排序,搜索和匹配信息; 并翻译了语言,地区,脚本,货币和时区的名称。像苹果、谷歌、IBM、微软、Oracle等等很多公司都在使用 | ULocale |
Resource Bundles | 资源文件管理 | UResourceBundle |
日历&时区 | 在传统的公历日历之外提供了多种类型的日历。提供了一套完整的时区计算API,比如中国的农历等; | Calendar, GregorianCalendar, SimpleTimeZone, TimeZone |
Bidi | 支持处理包含从左到右(英文)和从右到左(阿拉伯文或希伯来文)数据混合的文本 | Bidi |
Unicode 正则 表达式 | ICU的正则表达式完全支持Unicode,同时提供非常有竞争力的性能 | UnicodeMatcher |
文本边界 | 在文本范围内查找单词,句子,段落的位置,或在显示文本时标识适合换行的位置 | BreakIterator, StringCharacterIterator, StringTokenizer |
格式化:时间&日期 | 根据所选语言环境的风俗习惯格式化数字,日期,时间和货币金额,以及时间日期的缩写等 | DateFormat, DateFormat.Field, DateFormatSymbols, SimpleDateFormat |
格式化:数字&货币 | Currency, DecimalFomat, DecimalFormatSymbols, NumberFormat, NumberFormat.Field | |
文本转换:规范化Normalization | 将Unicode文本转成等价的规范化格式内容,从而更好的进行比较排序等 | Normalizer |
大小写转换 | 大小写转换 | CaseInsensitiveString |
代码页转换和Transliterations | 将文本数据转换为Unicode或其他字符集或编码。ICU的转换表基于IBM在过去几十年中收集的字符集数据,相对是最全面的。 | Transliterator CharsetICU CharsetEncoderICU CharsetDecoderICU |
下面将基于项目实践,列出几个ICU4J API应用实例。在支持多语言的应用程序中,根据用户Locale对日期时间的显示和解析是最基本的功能。清单1是Java和ICU4J中时间日期格式化显示对比。
清单 1. Java和ICU4J中的时间日期格式化
private static void DateTimeFormat() throws ParseException {
Date date = new Date(1234567890L);
Locale locale = Locale.CHINA;
//ICU4J DateFormat
DateFormat dateFormatShort = com.ibm.icu.text.DateFormat.getDateTimeInstance(
DateFormat.SHORT, DateFormat.SHORT, locale);
DateFormat dateFormatMedium = com.ibm.icu.text.DateFormat.getDateTimeInstance(
DateFormat.MEDIUM, DateFormat.MEDIUM, locale);
DateFormat dateFormatLong = com.ibm.icu.text.DateFormat.getDateTimeInstance(
DateFormat.LONG, DateFormat.LONG, locale);
DateFormat dateFormatFull = com.ibm.icu.text.DateFormat.getDateTimeInstance(
DateFormat.FULL, DateFormat.FULL, locale);
//Java DateFormat
java.text.DateFormat javaDateFormatShort = java.text.DateFormat.getDateTimeInstance(
DateFormat.SHORT, DateFormat.SHORT, locale);
DateFormat javaDateFormatMedium = java.text.DateFormat.getDateTimeInstance(
DateFormat.MEDIUM, DateFormat.MEDIUM, locale);
java.text.DateFormat javaDdateFormatLong = java.text.DateFormat.getDateTimeInstance(
DateFormat.LONG, DateFormat.LONG, locale);
java.text.DateFormat javaDateFormatFull = java.text.DateFormat.getDateTimeInstance(
DateFormat.FULL, DateFormat.FULL, locale);
String icu_Short = dateFormatShort.format(date);
String icu_Medium = dateFormatMedium.format(date);
String icu_long = dateFormatLong.format(date);
String icu_full = dateFormatFull.format(date);
String java_Short = javaDateFormatShort.format(date);
String java_Medium = javaDateFormatMedium.format(date);
String java_long = javaDdateFormatLong.format(date);
String java_full = javaDateFormatFull.format(date);
System.out.println("Java和ICU4J中的时间日期格式化:\nAPI\t Short格式\t\t Medium格式\t\t\tLong格式\t\t\t\tFull格式");
System.out.println("=====\t=========\t\t============\t\t\t================\t\t====================");
System.out.println("ICU4J\t" + icu_Short + "\t" + icu_Medium +"\t\t" + icu_long +"\t" + icu_full);
System.out.println("Java \t" + java_Short + "\t\t" + java_Medium +"\t\t" + java_long +"\t" + java_full);
}
图 9. Java和ICU4J中的时间日期格式化

根据对比结果可以看出,Java和ICU4J对时间日期格式化的输出结果显示有一些不同,日期和时间格式取决于语言和文化偏好,有些用户可能更喜欢Java的格式显示,其他用户可能更喜欢ICU的格式显示。这些差异不会在显示输出结果时造成问题。但是格式化差异在解析时间日期字符串时可能会出现一些问题,ICU LONG FORMAT日期和时间解析功能不能分析基于Java的LONG FORMAT日期。由于ICU解析器不是基于Java的日期和时间格式的规则,所以ICU解析器将拒绝分析基于Java格式的字符串,相反,Java解析函数将无法分析基于ICU的格式。在解析和显示格式化时间日期的时候,需要注意几点:
解析器必须与显示格式化工具相同。例如,如果ICU4J用于显示格式,则必须使用ICU解析器;
解析格式样式(如SHORT)必须与显示格式样式相同。例如,如果显示格式使用SHORT格式样式,解析器也需要使用SHORT格式;
解析器的语言环境必须与显示格式的语言环境相同。例如,如果显示格式使用“汉语中国”语言环境,那么解析器也必须使用“汉语中国”语言环境。
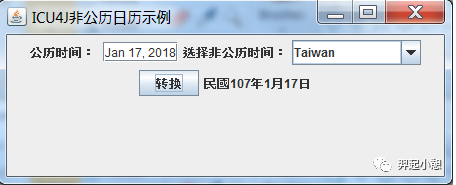
当我们需要创建日历组件的时候,可以使用Java库中的日历对象(java.util.Calendar),也可以使用ICU4J库中的日历,但是对于支持多语言的程序来说,最好使用ICU4J库中的日历空间,因为它支持的类型更多,对国际化支持更好,除了公历之外,还有佛教日历,中国的农历,台湾的民国日历,日本日历等等。ICU还支持公历日历和其他非公历日历之间的转换,如清单2所示的代码片段。
清单 2. ICU4J对非公历日历支持
public ULocale setLocale(ActionEvent ev) {
int type = lcList.getSelectedIndex();
ULocale lc = null;
if (type == 0) {
lc = new ULocale("ja_JP@calendar=japanese");
} else if (type == 1) {
lc = new ULocale("th_TH@calendar=buddhist");
} else if (type == 2) {
lc = new ULocale("ar_SA@calendar=islamic");
} else if (type == 3) {
lc = new ULocale("he_IL@calendar=hebrew");
} else if (type == 4) {
lc = new ULocale("hi_IN@calendar=indian");
} else if (type == 5) {
lc = new ULocale("zh_TW@calendar=roc");
} else {
lc = new ULocale("en_US@calendar=coptic");
}
return lc;
}
private Calendar setCalendar(ULocale lc, Date date) {
int type = lcList.getSelectedIndex();
Calendar ngCalendar;
if (type == 0) {
ngCalendar = JapaneseCalendar.getInstance(lc);
} else if (type == 1) {
ngCalendar = BuddhistCalendar.getInstance(lc);
} else if (type == 2) {
ngCalendar = IslamicCalendar.getInstance(lc);
} else if (type == 3) {
ngCalendar = HebrewCalendar.getInstance(lc);
} else if (type == 4) {
ngCalendar = IndianCalendar.getInstance(lc);
} else if (type == 5) {
ngCalendar = TaiwanCalendar.getInstance(lc);
} else if (type == 6) {
ngCalendar = CopticCalendar.getInstance(lc);
} else {
ngCalendar = GregorianCalendar.getInstance(lc);
}
ngCalendar.setTime(date);
return ngCalendar;
}
图 10. ICU4J对公历和非公历日历之间的转换
Unicode支持在Java Web程序中应用实践
Unicode是互联网的基石,为了保证我们的Web应用程序很好的支持Unicode标准。从代码角度需要考虑Unicode支持的地方有(不限于这些,下面是基于笔者项目实践):
Java默认字符集设定:通常情况下如Windows系统,我们会通过设置环境变量JAVA_TOOL_OPTIONS将默认编码更改为UTF-8,下面是Java程序默认字符集的优先级顺序:
程序执行时使用Properties指定的字符集,如System.getProperties().put("file.encoding",”UTF-8);
参数-Dfile.encoding指定的字符集,如Windows可以通过设置环境变量JAVA_TOOL_OPTIONS=-Dfile.encoding=UTF-8
操作系统默认的字符集;
JDK中JVM默认的字符集。
JSP:通过JSP页面命令<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>设置JSP页面的编码方式(pageEncoding)以及提交表单时所使用的编码方式(charset属性);
HTML: 设置Content-Type属性<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">;
Servlet:设置response.setContentType("text/html;charset=UTF-8"),即服务器端编码方式;
POST请求:通过request.setCharacterEncoding ("UTF-8")设置解码方式、response.setCharacterEncoding("UTF-8")设置服务器端响应数据的编码方式,如清单3所示;
清单 3. POST请求字符编码设置
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
// TODO Auto-generated method stub
request.setCharacterEncoding("UTF-8");
response.setCharacterEncoding("UTF-8");
}
Get请求:Get请求方式中请求参数会被附加到地址栏的URL之后,URL组成:域名:端口/contextPath/servletPath/pathInfo?queryString,不同的服务器对URL中pathInfo和queryString解码方式设定不一样,比如Tomcat服务器一般在server.xml中设定的,Tomcat8之前的版本默认使用的是 ISO-8859-1,但是Tomcat 8默认使用的是UTF-8,如清单4所示;另外对于双字节字符如中日韩等作为URL的参数时,最好先URI编码后在放到URL中URLEncoder.encode(String.valueOf(c),"UTF-8");
清单 4. Tomcat server.xml设置
Tomcat server.xml
<Connector port="8080" protocol="HTTP/1.1"
maxThreads="150"
connectionTimeout="20000"
redirectPort="8443"
URIEncoding="UTF-8"
useBodyEncodingForURI=”true”>
XML文档:设置transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
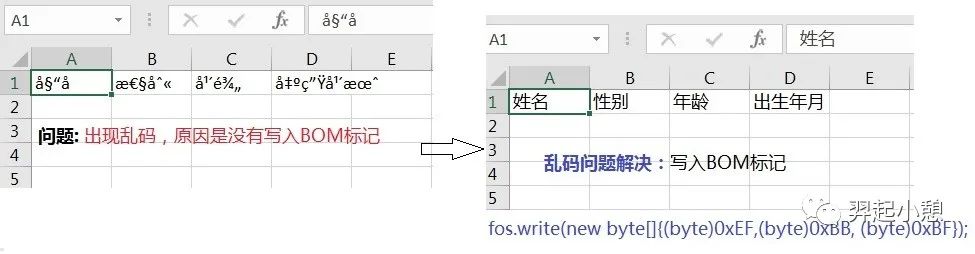
调用API时指定字符集:调用字符串操作相关或者其他I/O操作API时,最好指定字符集,如String.getBytes(“UTF-8”),而不是String.getBytes();根据情况必要的时候需要写入BOM头,例如Microsoft Office在读取csv文件的时候,它将首先读取BOM,然后使用BOM中的编码打开文件,这种情况下我们在创建或者导出到CSV文件的时候,我们需要在代码里面写入BOM头。图10所示的例子是创建一个csv文件的时候没有写入BOM,用Office打开看到的都是乱码,但是用其他编辑器比如notepad++显示是正常。当加上BOM文件头的时候fos.write(new byte[]{(byte)0xEF,(byte)0xBB, (byte)0xBF}) 用Office再次打开就是正确的字符,代码如清单5所示。备注一下,UTF-8虽然部分大端小端序,但是可以加BOM头,表示这个文本是UTF-8编码。
图 11. 缺少BOM标记乱码示例
清单 5. BOM 标记例子
private static void createCsvFile() {
try {
FileOutputStream fos = new FileOutputStream("c:\\test.csv");
String str ="姓名,性别,年龄,出生年月";
fos.write(new byte[]{(byte)0xEF,(byte)0xBB, (byte)0xBF});
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
BufferedWriter b_writer = new BufferedWriter(osw);
b_writer.write(str);
b_writer.close();
} catch (IOException e) {
System.out.println(e.toString());
}
}
Oracle数据库:Oracle数据库从7.2开始支持Unicode,为了让应用程序更好的支持多语言,当我们新建一个数据库的时候,最好使用UTF-8编码格式,从而可以对如CHAR、VARCHAR2、CLOB、LONG等SQL数据类型使用UTF-8进行编码;如果多语言数据可能只出现在某些字段中,那么也可以直接使用支持Unicode编码的SQL数据类型,如NCHAR、NVARCHAR2和NCLOB,如表4列出的常用SQL数据类型介绍。
表4. SQL数据类型介绍
SQL数据类型 | 编码方式 | 内存分配 | 最大 字节数 | Semantics |
CHAR | 数据库编码方式 | 固定长度 | 2000 | 字节(Bytes) |
NCHAR | Unicode | 固定长度 | 2000 | 字符(character) |
VARCHAR2 | 数据库编码方式 | 变长 | 4000 | 字节/字符(bytes/character) |
NVARCHAR2 | Unicode | 变长 | 4000 | 字符(character) |
总结
本文介绍了Unicode规范,详细概述了Unicode常用的三种编码方式编码算法、特点以及他们之间的区别和应用场景,介绍了ICU4J库,基于项目实践,终结了如何在Java Web程序中 更好的支持Unicode,从而实现应用程序的多语言化,希望能对读者深入理解Unicode规范、Unicode编码方式以及如何让我们的Web程序更好的支持Unicode提供帮助。
参考资料 (resources)
Unicode 编码规范,详细描述了 Unicode 如何编码。
Unicode官方网站,Unicode规范的详细说明。
ICU官方网站,ICU详细介绍。
ICU4J官方网站,ICU4J库的详细介绍。
CLDR官方网站,详细介绍CLDR库。
