




全文检索方案Elasticsearch
1. 全文检索和搜索引擎原理
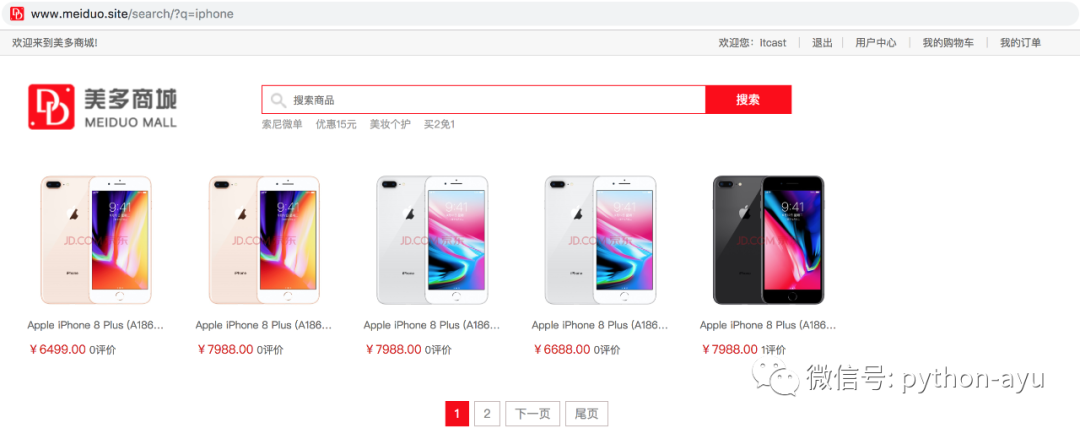
商品搜索需求
当用户在搜索框输入商品关键字后,我们要为用户提供相关的商品搜索结果。
商品搜索实现
可以选择使用模糊查询
like
关键字实现。但是 like 关键字的效率极低。
查询需要在多个字段中进行,使用 like 关键字也不方便。
全文检索方案
我们引入全文检索的方案来实现商品搜索。
全文检索即在指定的任意字段中进行检索查询。
全文检索方案需要配合搜索引擎来实现。
搜索引擎原理
搜索引擎进行全文检索时,会对数据库中的数据进行一遍预处理,单独建立起一份索引结构数据。
索引结构数据类似新华字典的索引检索页,里面包含了关键词与词条的对应关系,并记录词条的位置。
搜索引擎进行全文检索时,将关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
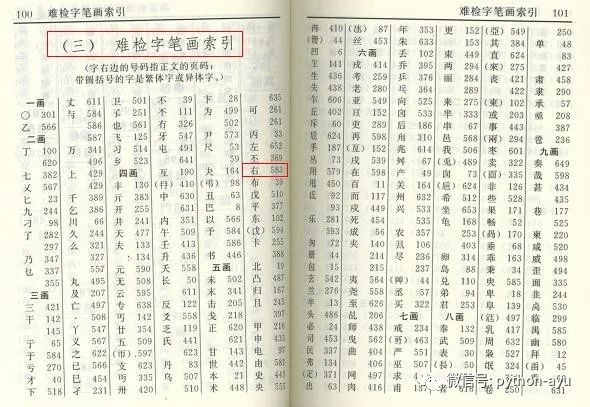
结论:
搜索引擎建立索引结构数据,类似新华字典的索引检索页,全文检索时,关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
2. Elasticsearch介绍
实现全文检索的搜索引擎,首选的是
Elasticsearch
。
Elasticsearch 是用 Java 实现的,开源的搜索引擎。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github等都采用它。
Elasticsearch 的底层是开源库 Lucene。但是,没法直接使用 Lucene,必须自己写代码去调用它的接口。
分词说明
搜索引擎在对数据构建索引时,需要进行分词处理。
分词是指将一句话拆解成多个单字 或 词,这些字或词便是这句话的关键词。
比如:
我是中国人分词后:
我
、是
、中
、国
、人
、中国
等等都可以是这句话的关键字。Elasticsearch 不支持对中文进行分词建立索引,需要配合扩展
elasticsearch-analysis-ik
来实现中文分词处理。
3. 使用Docker安装Elasticsearch
1.获取Elasticsearch-ik镜像
# 从仓库拉取镜像
$ sudo docker image pull delron/elasticsearch-ik:2.4.6-1.0
# 解压教学资料中本地镜像
$ sudo docker load -i elasticsearch-ik-2.4.6_docker.tar
2.配置Elasticsearch-ik
将教学资料中的
elasticsearc-2.4.6
目录拷贝到home
目录下。修改
/home/python/elasticsearc-2.4.6/config/elasticsearch.yml
第54行。更改ip地址为本机真实ip地址。

3.使用Docker运行Elasticsearch-ik
$ sudo docker run -dti --name=elasticsearch --network=host -v /home/python/elasticsearch-2.4.6/config:/usr/share/elasticsearch/config delron/elasticsearch-ik:2.4.6-1.0


