




为什么 ELK 的功能如此强大呢?这就需要我们对 ELK 中储存、索引等关键技术点的架构实现进行深入了解才能弄明白。相信在学习完今天的内容之后,大家对于大数据分布式的核心实现方式,还有大数据分布式统计服务,都会有更为深刻的认识。
Elasticsearch 架构
那么 ELK 是如何运作的?它为什么能够承接如此大的日志量?我们先分析分析 ELK 的架构长什么样,事实上,它和 OLAP 及 OLTP 的实现区别很大,我们一起来看看。Elasticsearch 架构如下图:

我们对照架构图,梳理一下整体的数据流向,可以看到,我们项目产生的日志,会通过 Filebeat 或 Rsyslog 收集将日志推送到 Kafka 内。然后由 LogStash 消费 Kafka 内的日志、对日志进行整理,并推送到 Elasticsearch 集群内。
接着,日志会被分词,然后计算出在文档的权重后放入索引中供查询检索,Elasticsearch 会将这些信息推送到不同的分片。每个分片都会有多个副本,数据写入时,只有大部分副本写入成功了,主分片才会对索引进行落地(需要你回忆下分布式写一致知识)。
Elasticsearch 集群中服务分多个角色,我带你简单了解一下:
Master 节点主要负责集群内的调度决策,涵盖集群状态、节点信息、索引映射、分片信息以及路由信息等方面。Master 节点的真正主节点是通过选举产生的,通常一个集群内至少要有三个可供竞选 Master 节点的成员,目的是防止主节点损坏。回想一下之前的 Raft 知识,不过在 Elasticsearch 刚出现的时候还没有 Raft 标准。
Data 存储节点的作用是存储数据以及进行计算,包括分片的主从副本、作为热点节点和冷数据节点。
Client 协调节点负责协调多个副本的数据查询服务,聚合各个副本的返回结果,然后将结果返回给客户端。
Kibana 计算节点的作用在于进行实时统计分析、聚合分析统计数据以及图形聚合展示。
在实际安装生产环境时,Elasticsearch 最少需要三台服务器。其中,有一台服务器会成为 Master 节点,负责调配集群内的索引以及资源的分配。另外两台服务器则会用于 Data 数据存储以及数据检索计算。当 Master 节点出现故障时,子节点会选出一个节点来替代出现故障的 Master 节点。这里可以回忆一下分布式共识算法中的选举。
如果我们的硬件资源充裕,可以另外增加一台服务器,将 Kibana 计算独立部署。这样做能够获得更好的数据统计分析性能。
如果我们的日志写入过慢,可以再增加一台服务器用于 Logstash 分词,协助加快 ELK 整体入库的速度。要知道,在最近这几年,大部分云厂商提供的日志服务都是基于 ELK 实现的。Elasticsearch 已经上市,由此可见其市场价值。
Elasticsearch 的写存储机制
下图是 Elasticsearch 的索引存储具体的结构,看起来很庞大,但是别担心,我们只需要关注分片及索引部分即可:
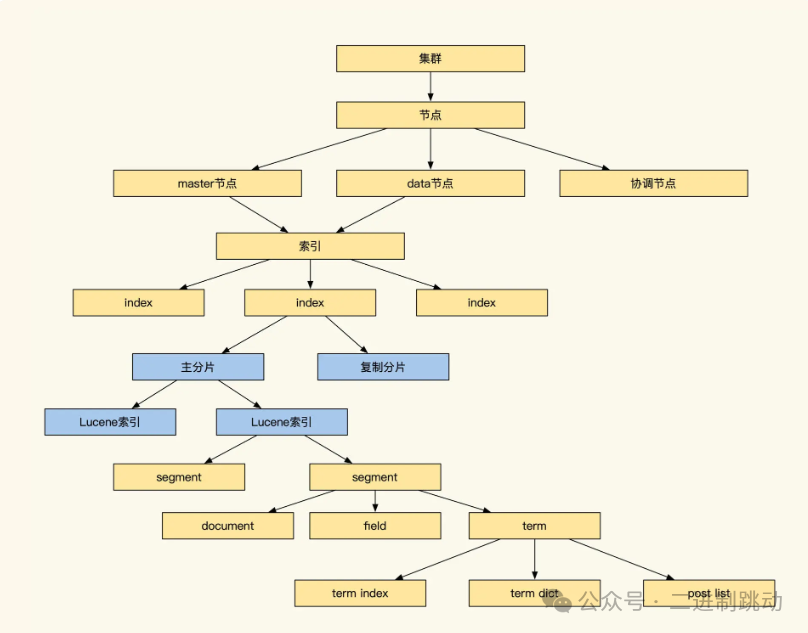
我们再来持续深入挖掘一下,Elasticsearch 是如何实现分布式全文检索服务的写存储的。
其底层的全文检索使用的是 Lucene 引擎。事实上,这个引擎是单机嵌入式的,并不支持分布式,分布式功能是基于分片来实现的。
为了提高写效率,常见的分布式系统通常会先将数据写在缓存中,当数据积累到一定程度后,再将缓存中的数据顺序刷入磁盘。Lucene 也采用了类似的机制,将写入的数据保存在 Index Buffer 中,周期性地将这些数据落盘到 segment 文件。
在存储方面,Lucene 为了让数据能够更快被查到,基本一秒会生成一个 segment 文件。这会导致文件很多、索引很分散。而检索时需要对多个 segment 进行遍历,如果 segment 数量过多会影响查询效率。为此,Lucene 会定期在后台对多个 segment 进行合并。
可以看到,Elasticsearch 是一个 IO 频繁的服务。将新数据放在 SSD 上能够提高其工作效率。但是 SSD 很昂贵,为此 Elasticsearch 实现了冷热数据分离。我们可以将热数据保存在高性能的 SSD 中,冷数据放在大容量磁盘中。同时,官方推荐我们按天建立索引。当我们的存储数据量达到一定程度时,Elasticsearch 会把一些不经常读取的索引挪到冷数据区,以此提高数据存储的性价比。而且我建议你在创建索引时按天创建索引,这样在查询时,我们可以通过时间范围来降低扫描数据量。
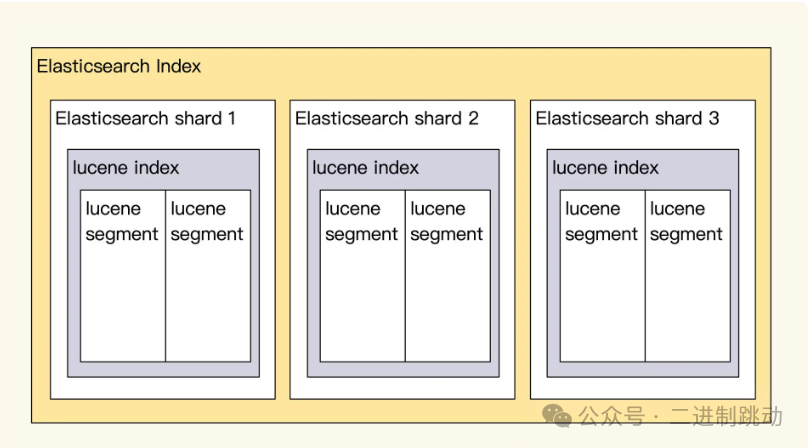
另外,Elasticsearch 服务为了确保读写性能可扩容,对数据进行了分片操作。分片的路由规则默认是通过日志的 DocId 进行 hash 运算,以此来保证数据分布均衡。常见的分布式系统都是通过分片来实现读写性能的线性提升。你可以这样去理解:当单个节点达到性能上限时,就需要增加 Data 服务器节点以及副本数,从而降低写压力。然而,副本增加到一定程度后,由于写强一致性的问题,反而会使得写性能下降。那么具体增加多少副本更好呢?这需要你通过生产日志进行实际测试,才能够确定具体的数值。
Elasticsearch 的两次查询
前面提到多节点以及多分片能够提升系统的写性能,但是这会使得数据分散在多个 Data 节点当中。Elasticsearch 并不知道我们要找的文档究竟保存在哪个分片的哪个 segment 文件中。
所以,为了均衡各个数据节点的性能压力,Elasticsearch 每次查询都是请求所有索引所在的 Data 节点。在查询请求时,协调节点会在相同数据分片的多个副本中随机选出一个节点发送查询请求,以此实现负载均衡。而收到请求的副本会根据关键词权重对结果先进行一次排序。当协调节点拿到所有副本返回的文档 ID 列表后,会再次对结果进行汇总排序,最后才会用 DocId 去各个副本 Fetch 具体的文档数据并将结果返回。
可以说,Elasticsearch 通过这种方式实现了对所有分片的大数据集的全文检索,但这种方式同时也加大了 Elasticsearch 对数据查询请求的耗时。
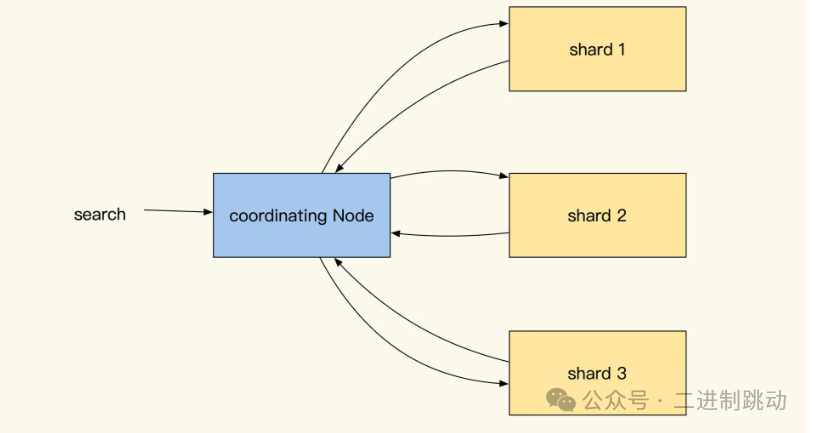
除了耗时之外,这个方式还有很多缺点。比如查询 QPS 低;网络吞吐性能不高;协调节点需要对每次查询结果做分页。分页后,如果我们想查询靠后的页面,要等每个节点先搜索和排序好该页之前的所有数据,才能响应,而且翻页跨度越大,查询就越慢。为此,ES 限制默认返回的结果最多 1w 条。这个限制也提醒了我们不能将 Elasticsearch 的服务当作数据库去用。
还有一点实践的注意事项,这种实现方式也导致了小概率个别日志由于权重太低查不到的问题。为此,ES 提供了 search_type=dfs_query_then_fetch 参数来应对特殊情况。但是这种方式损耗系统资源严重,非必要不建议开启。
除此之外,Elasticsearch 的查询有 query and fetch、dfs query and fetch、dfs query then fetch 三种。不过它们和这节课主线关联不大,有兴趣的话你可以课后自己了解一下。
Elasticsearch 的倒排索引
我们再谈谈 Elasticsearch 的全文检索的倒排索引。
Elasticsearch 支持多种查询方式,并非仅仅局限于全文检索。例如数值类查询使用的是 BKD Tree。Elasticsearch 的全文检索查询是通过 Lucene 来实现的。其索引的实现原理与 OLAP 的 LSM 以及 OLTP 的 B+Tree 完全不同,它所使用的是倒排索引(Inverted Index)。
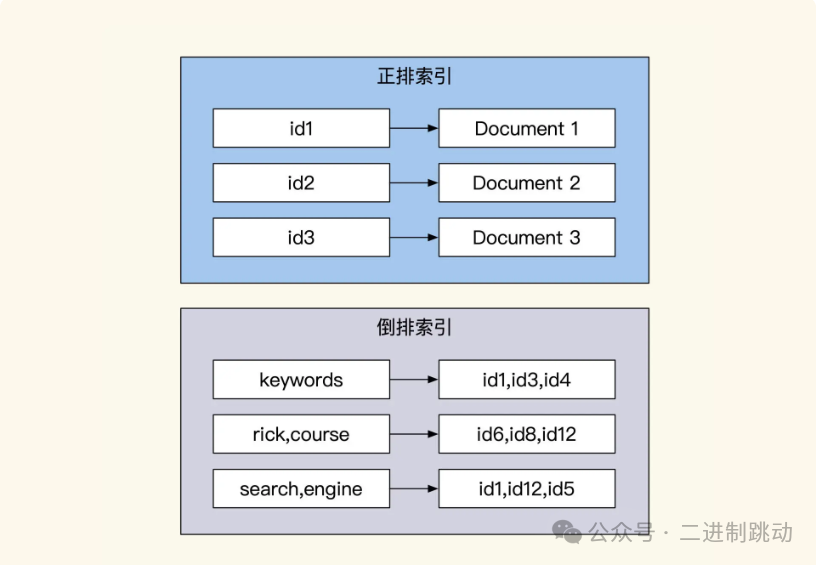
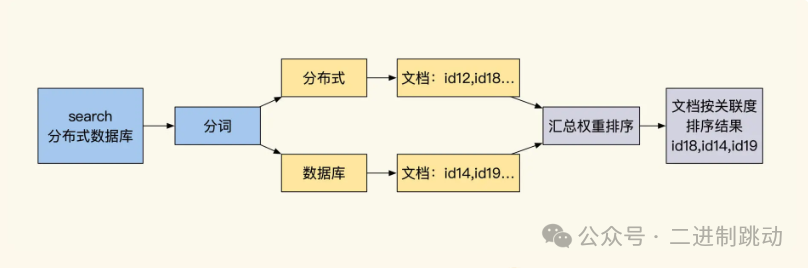
一般来说,倒排索引常常在搜索引擎内被用于做全文检索,它与关系数据库中的 B+Tree 和 B-Tree 不同。B+Tree 和 B-Tree 索引是从树根往下,按照左前缀的方式递减缩小查询范围。而倒排索引的过程大致可以分为四个步骤:
第一步,对用户输入的内容进行分词,找出关键词。
第二步,通过多个关键词对应的倒排索引,取出所有相关的 DocId。
第三步,将多个关键词对应的索引 ID 做交集后,再根据关键词在每个文档中的出现次数及频率,以此计算出每条结果的权重,进而给列表排序,实现基于查询匹配度的评分。
第四步,根据匹配评分降序排序,列出相关度高的记录。
下面,我们简单看一下 Lucene 具体实现。

为了节省空间和提高查询效率,Lucene 对关键字倒排索引做了大量优化,segment 主要保存了三种索引:
Term Index(单词词典索引):主要用于关键词(Term)的快速搜索。Term index 是基于 Trie 树改进的 FST(Finite State Transducer,有限状态传感器,占用内存少)实现的二级索引。平时这个树会存放在内存中,目的是减少磁盘 IO,加快 Term 的查找速度。在检索时,会通过 FST 快速找到 Term Dictionary 对应的词典文件 block。
Term Dictionary(单词词典):在单词词典索引中保存的是单词(Term)与 Posting List 的关系。这个单词词典数据会按 block 在磁盘中进行排序压缩保存,相比 B-Tree 更加节省空间。其中保存了单词的前缀后缀,可以用于近似词及相似词查询。通过这个词典可以找到相关的倒排索引列表位置。
Posting List(倒排列表):倒排列表记录了关键词 Term 出现的文档 ID,以及其所在文档中的位置、偏移、词频信息。这是我们查找的最终文档列表,拿到这些信息后就可以进行排序合并。一条日志在入库时,它的具体内容并不会真实保存在倒排索引中。在日志入库之前,会先进行分词,过滤掉无用符号等分隔词,找出文档中每个关键词(Term)在文档中的位置及频率权重。然后,将这些关键词保存在 Term Index 以及 Term Dictionary 内。最后,将每个关键词对应的文档 ID 和权重、位置等信息排序合并到 Posting List 中进行保存。通过上述三个结构就实现了一个优化磁盘 IO 的倒排索引。
而在查询时,Elasticsearch 会将用户输入的关键字通过分词解析出来,在内存中的 Term Index 单词索引查找到对应 Term Dictionary 字典的索引所在磁盘的 block。接着,由 Term Dictionary 找到对关键词对应的所有相关文档 DocId 及权重,并根据保存的信息和权重算法对查询结果进行排序,最后返回结果。
