




前 言
最近两个月前遇到网友有一套云上的单机的 11g DG,去年通过某云搭建好了 ADG 环境,但今年中由于网络原因导致主库的归档日志还没有传递到备库就被强制删除了,进而导致 ADG 备库出现 GAP。原以为这个问题比较简单,通过增量备份恢复就好了,因为不是 19c 版本没法通过 from service 的方式恢复,感兴趣的可查看如下文章。
Oracle ADG 备库停启维护步骤及增量恢复
利用 Oracle 19c 新特性 from service 修复备库 GAP

正 文
因归档丢失出现 GAP 如果需要的归档日志有备份,直接恢复出所需要的归档,然后拿到备库去注册就行,如果没有备份归档,那么则需要重建或者增量恢复,如果库比较大,则增量恢复。当使用正常的流程增量恢复后,应用日志开启 MRP0 进程却不同步日志,状态是 WAIT_FOR_GAP 等待几年前的已经不存在的归档号 16754。如下图所示:
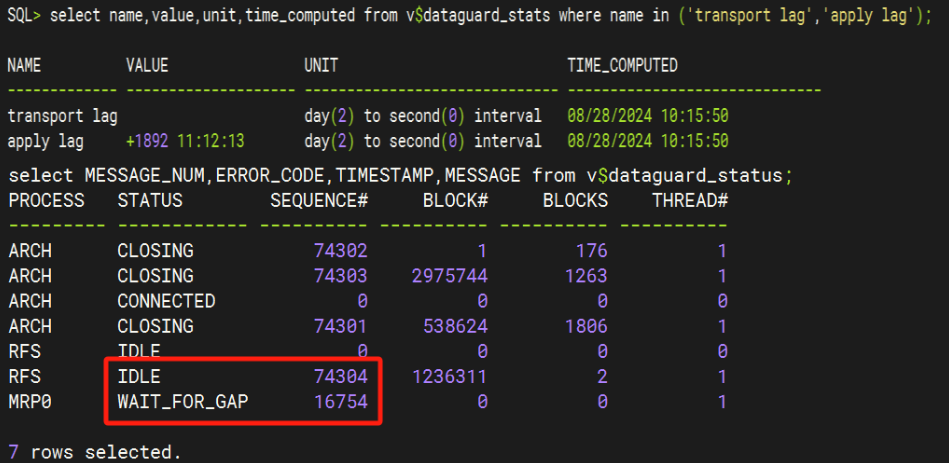
一度怀疑他是不是没有按照我的步骤做恢复,因为平时上班期间也不能远程,排查无果,没办法只能让其全库恢复了,使用如下命令进行 rman 全备,然后传递到备库做恢复。
rman target /
run {
allocate channel c1 type disk ;
allocate channel c2 type disk ;
allocate channel c3 type disk ;
allocate channel c4 type disk ;
backup as compressed backupset database format '/backup/backup20240830/%d_%I_%s_%p.bak';
backup as compressed backupset archivelog all format '/backup/backup20240830/%d_%I_%s_%p.arc';
backup current controlfile for standby format '/backup/backup20240830/%d_%I_%s_%p.ctl';
release channel c1;
release channel c2;
release channel c3;
release channel c4;
}
--将备份传输至备库
[oracle@jiekexu rmanbk]$ scp beijing_3078169696_* 192.168.3.105:/backup/backup20240830/
--备库操作
SQL> startup nomount
rman target /
RMAN> restore standby controlfile from '/backup/backup20240830/JiekeXu_1470960497_14179_1.ctl';
RMAN> sql 'alter database mount';
--注册从源数据库拷贝过来的备份集到 rman 中
RMAN> catalog start with'/backup/backup20240830/';
……
Do you really want to catalog the abovefiles (enter YES or NO)? yes
--恢复数据库
run {
allocate channel c1 type disk;
allocate channel c2 type disk;
allocate channel c3 type disk;
allocate channel c4 type disk;
restore database;
recover database;
release channel c1;
release channel c2;
release channel c3;
release channel c4;
}
进行全量备份恢复后,应用日志开启 MRP0 进程,alert 日志中也没有任何报错,但还是不同步日志,状态也是 WAIT_FOR_GAP 等待几年前的已经不存在的归档号 16754。如下图所示:
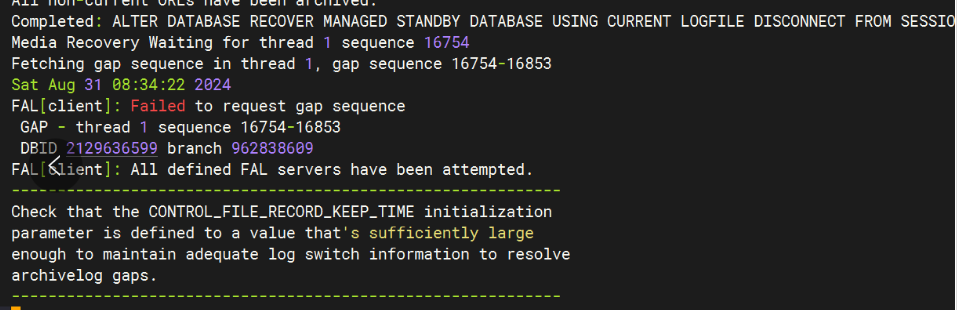
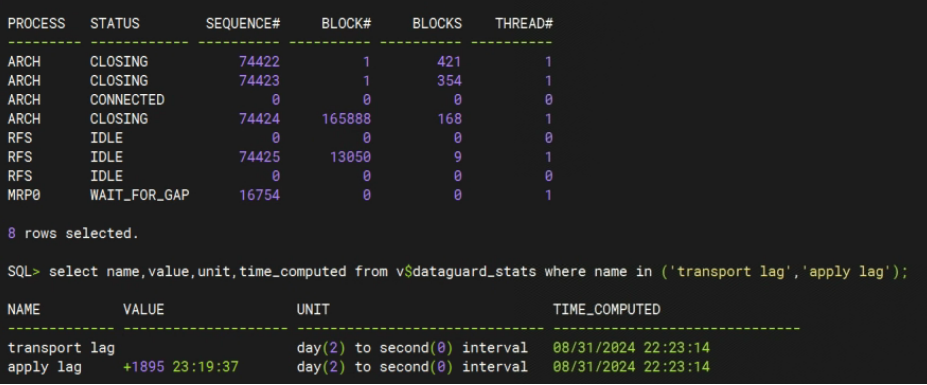
问题根因
最终通过排查发现,源库有一个 43 号数据文件处于“RECOVER”状态。
SQL> select file#,CREATION_TIME,ts#,status,ENABLED from v$datafile where file#=43;
FILE# CREATION_ TS# STATUS ENABLED
---------- --------- ---------- ------- ----------
43 23-JUN-19 6 RECOVER READ WRITE
SQL> select file_id,file_name,status from dba_data_files where tablespace_name='STS_01' and file_id=43;
FILE_ID FILE_NAME STATUS
---------- ---------------------------------------------------------------------------------------- ---------
43 /u01/oracle/oradata/prod/sts_01.20190623_5.dbf AVAILABLE
查看 alert 日志发现这个 43 号文件在 22 年的时候就被 drop 过,后面做过 “RECOVER” 但是一直没有 online,幸好这个数据文件上也没有存放数据,不然可能导致数据丢失的风险。
SELECT e.segment_name, e.segment_type
FROM dba_extents e
JOIN dba_data_files f ON e.file_id = f.file_id
WHERE f.file_id=43;
注意:如果查出有数据,那么需要联系业务人员再三确认这些对象可以删除,如果没有备份,那么恢复起来就比较困难了,具体还需要进一步判断数据对象是什么,通过非常规手段进行异常数据恢复。
解决问题
那么,通过查看 alert 日志发现这个数据文件以前主库就被删除过,且去年搭建 DG 的时候也 drop 过这个文件,经过再三确定可以删除这个文件,那就干吧。
SQL> startup mount
ORACLE instance started.
Total System Global Area 1.5500E+11 bytes
Fixed Size 2261448 bytes
Variable Size 2.0938E+10 bytes
Database Buffers 1.3368E+11 bytes
Redo Buffers 376410112 bytes
Database mounted.
SQL>
SQL>
SQL> select file#,CREATION_TIME,ts#,status,ENABLED from v$datafile where file#=43;
FILE# CREATION_TIME TS# STATUS ENABLED
---------- ------------------- ---------- ------- ----------
43 2019-06-23 22:59:20 6 RECOVER READ WRITE
SQL>
SQL> alter database datafile 43 offline;
alter database datafile 43 offline
*
ERROR at line 1:
ORA-01668: standby database requires DROP option for offline of data file
SQL> alter database datafile 43 offline drop;
Database altered.
SQL> !
[oracle@cis ~]$ ll /u02/oracle/oradata/prod/ts_01.20190623_5.dbf
-rw-r----- 1 oracle oinstall 33286004736 Aug 31 22:15 /u02/oracle/oradata/prod/ts_01.20190623_5.dbf
执行后此命令不会立即删除磁盘上的物理文件。这个命令的作用是将数据文件 ID 为 43 的数据文件将被标记为离线并从数据库控制文件中删除,但它不会自动删除物理磁盘上的文件。
通过这个操作后,重启 MRP 进程,查看状态以及变为 APPLYING_LOG,不一会儿 apply lag 也变成了 0,算是恢复正常了。
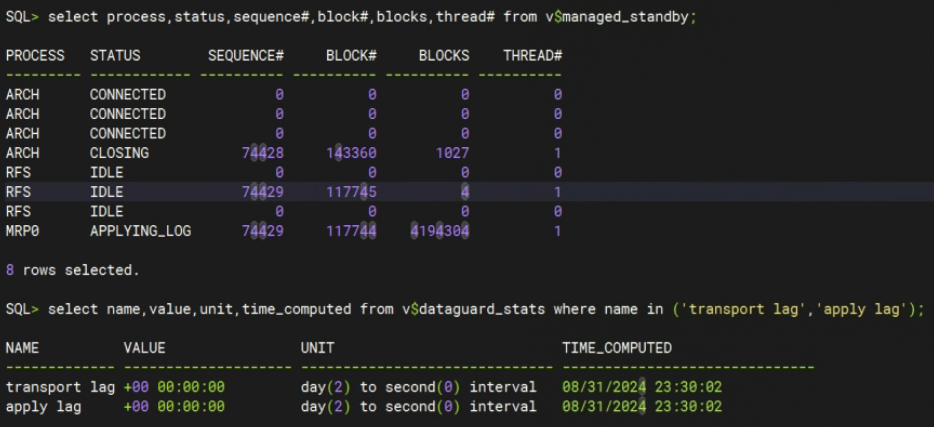
问题总结
如果主库有处于 recover 状态的数据文件无法通过 rman 备份,更加搭建不了一个正常同步的 ADG。
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤️ 欢迎关注我的公众号【JiekeXu DBA之路】,一起学习新知识!
——————————————————————————
公众号:JiekeXu DBA之路
墨天轮:https://www.modb.pro/u/4347
CSDN :https://blog.csdn.net/JiekeXu
ITPUB:https://blog.itpub.net/69968215
腾讯云:https://cloud.tencent.com/developer/user/5645107
——————————————————————————
