




分析pt-query-digest结果集通常关注下面几个指标值:
第一指标,单条sql语句占采样时间内所有sql执行时间总和的百分比,time列即是。

第二指标,单条sql平均每次的执行时间,R/Call列即是。

第三指标,单条sql的检索行数和发送行数的汇总及平均值。
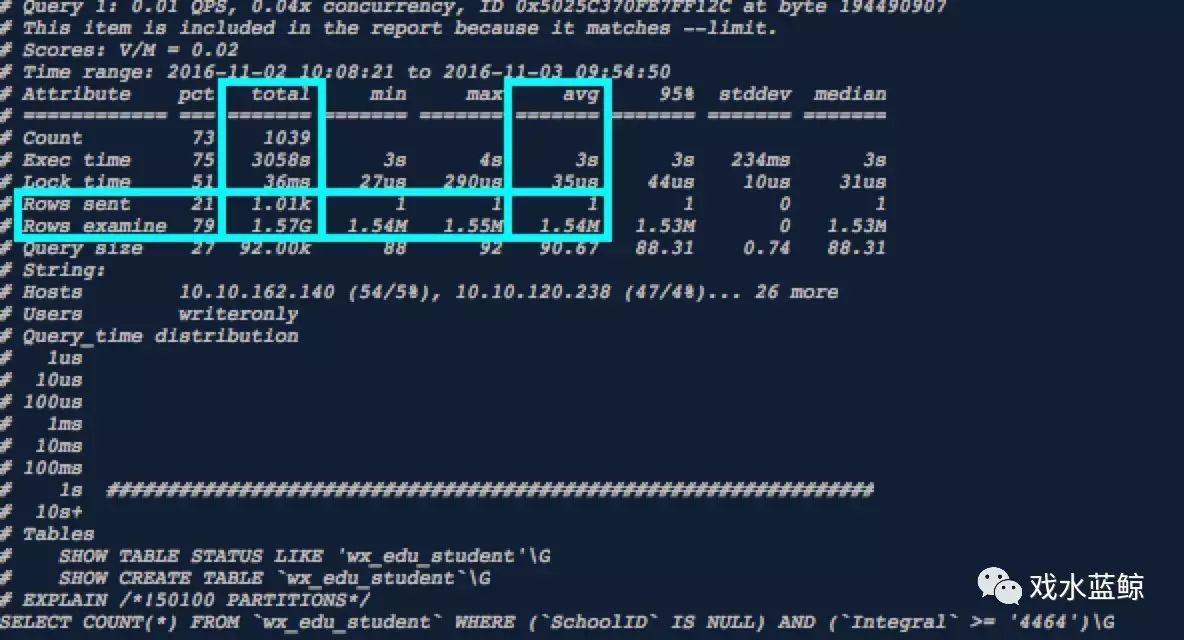
第四指标,单条sql检索行数和发送行数的比值。
当第一指标和第二指标都没有明显异常(明显高于其他sql语句)的时候,需要关注第三指标以及第四指标,但是当结果集中sql语句过多,肉眼观察该值会费时费力,下面的脚本就解决了这样尴尬的问题
#!/bin/bash
#####################################################################
#@@@ Author : bluewhalew(playful_bluewhale@hotmail.com)
#@@@ Name : Analysis_SlowQuery.sh
#@@@ Describe : analyze slowquery filr sent rows and examine rows
#@@@ Created in : 20170421
#@@@ Modified in : 20170421
#####################################################################
if [ $# != 1 ]; then
echo "para counts is false"
else
cat $1|grep "# Rows sent"|awk 'NR>1 { if($8 ~/M$/) print $8*1000000; else if ($8 ~/k$/) print $8*1000; else print $8}' > RowsSent.log
cat $1|grep "# Rows examine"|awk 'NR>1 { if($8 ~/M$/) print $8*1000000; else if ($8 ~/k$/) print $8*1000; else print $8}' > RowsExamine.log
t1=`cat $1 |sed -n 12p|awk '{if($7 ~/M$/) print $7*1000000; else if ($7 ~/k$/) print $7*1000; else print $7}'`
t2=`cat $1 |sed -n 13p|awk '{if($7 ~/M$/) print $7*1000000; else if ($7 ~/k$/) print $7*1000; else print $7}'`
t3=`cat $1 |sed -n 6p`
echo $t3 " " `echo "sclae=2; $t2/$t1" | bc` > result.log
awk 'BEGIN{cnt_a=0;cnt_b=0;}FNR==NR{a[cnt_a++]=$0;next} {b[cnt_b++]=$0} END{cnt=0;cnt_max=cnt_a<cnt_b ? cnt_b:cnt_a;for(;cnt<cnt_max;++cnt){print a[cnt]","b[cnt]}}' RowsSent.log RowsExamine.log >RowsSentExame.log
cat RowsSentExame.log |awk 'BEGIN{FS=","}{printf "%.2f\n",$2/$1}' > RowsSentExamRate.log
cat $1|grep "concurrency, ID" > ID.log
awk 'BEGIN{cnt_a=0;cnt_b=0;}FNR==NR{a[cnt_a++]=$0;next} {b[cnt_b++]=$0} END{cnt=0;cnt_max=cnt_a<cnt_b ? cnt_b:cnt_a;for(;cnt<cnt_max;++cnt){print a[cnt]","b[cnt]}}' ID.log RowsSentExamRate.log |sed 's/,/ /g'|sed 's/ \+/ /g'|sort -t ' ' -k 13nr >> result.log
more result.log
fi
脚本输出结果如下,最后一列,即为第四指标,个人觉得该值高于500就要引起注意了

