




Ustore 存储引擎,又名 In-place Update 存储引擎(原地更新),是 openGauss 内核新增的一种存储模式。UBtree是专门为 Ustore 存储引擎开发的索引。
UBtree 简介
Ubtree在现实是一个 B-Link Tree,并在其基础上增加了事物信息,叶子页面的元组存放堆表元组的 ctid,属于非聚簇索引,叶子节点的元组按 key + ctid(元组所在页面号和页面内元组指针下标)升序排列,结构如下图所示:
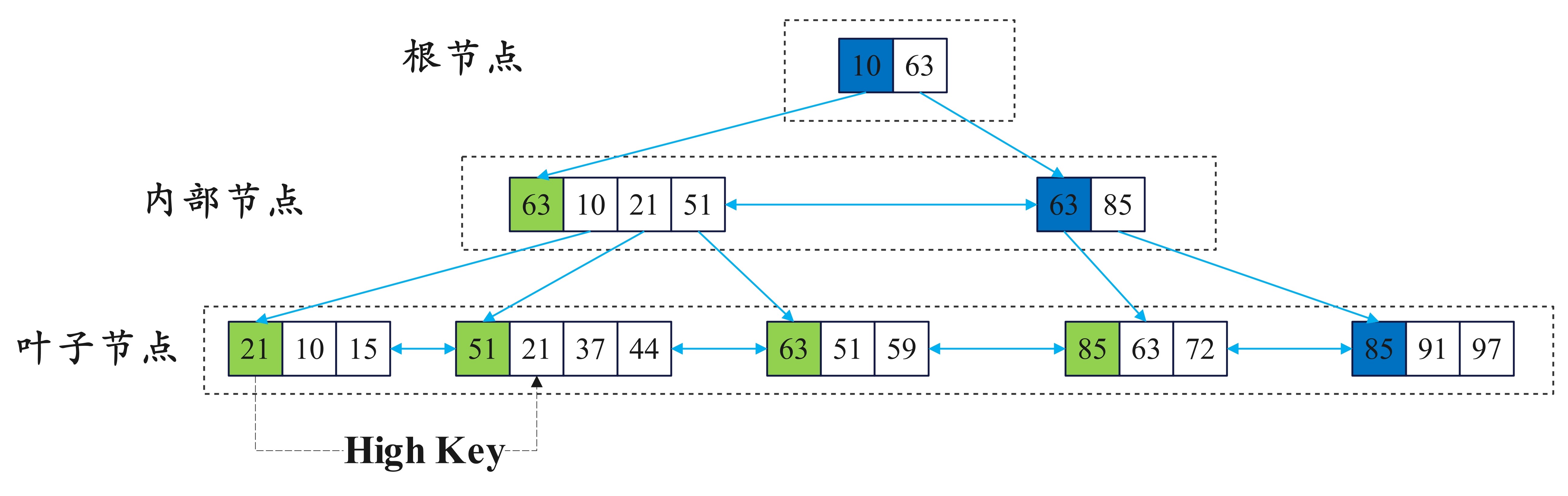
结构特点为:
- 是一个多叉树
- 每一层的节点是有序的
- 每一层的节点间存在双指针
- 数据仅保存在叶子节点中,数据是一个指向实际 tuple 的指针
其中每一个节点都是一个 page,page 的结构如下:
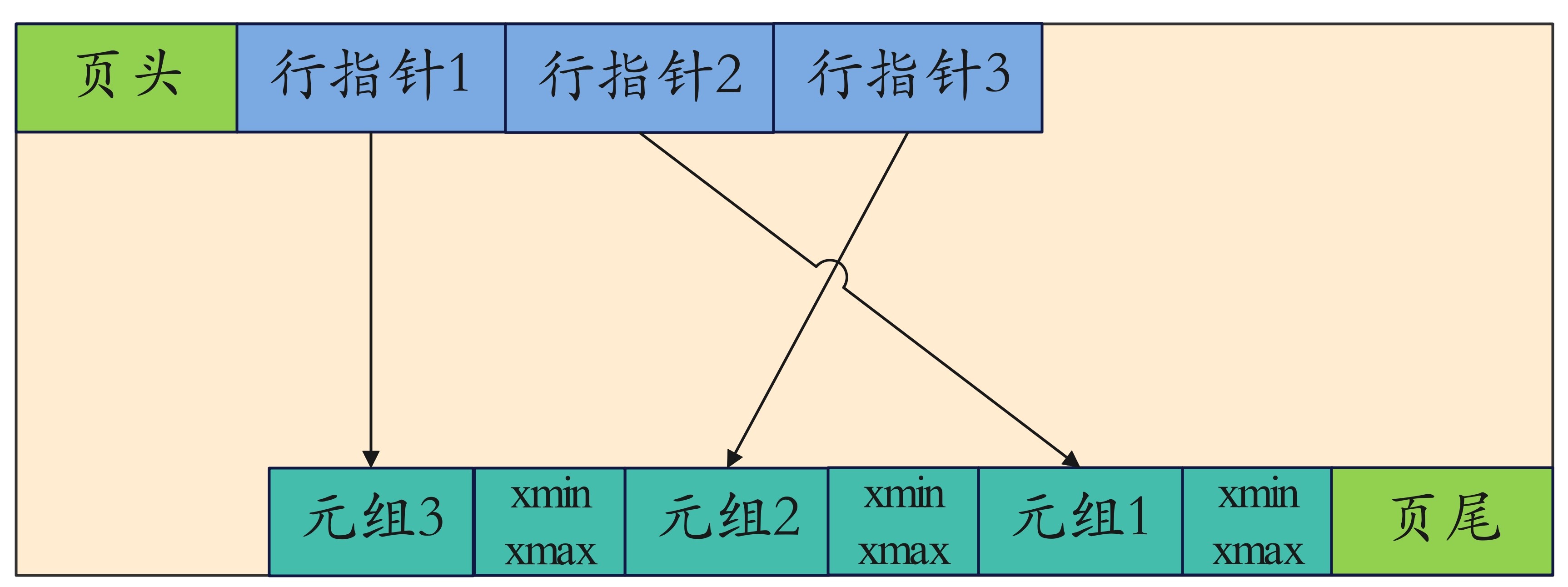
索引页头定义如下:PageHeaderData:
typedef struct {
PageXLogRecPtr pd_lsn; /* 记录该页面最后一次修改操作的xlog的结束位置的下一位 */
uint16 pd_checksum; /* 页面CRC校验值 */
uint16 pd_flags; /* 页面的标记位 */
LocationIndex pd_lower; /* 页面中空闲空间的起始位置,即下一个可行指针的插入位置 */
LocationIndex pd_upper; /* 页面中空闲空间的结束位置,即下一个可插入tuple的位置 */
LocationIndex pd_special; /* 页尾特殊区域的起始位置 */
uint16 pd_pagesize_version; /* 页面的大小和版本号 */
ShortTransactionId pd_prune_xid; /* 页面清理辅助事物号,通常为该页面内存在的最老的删除或更新操作的事物号,用于判断是否触发空闲空间回收 */
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; /* 行指针数组 */
} PageHeaderData;
行指针定义如下:ItemIdData:
typedef struct ItemIdData {
unsigned lp_off : 15, /* 元组的页内偏移量,即Indextuple在页面内的位置 */
lp_flags : 2, /* 状态值 */
lp_len : 15; /* tuple字节长度 */
} ItemIdData;
索引元组头结构如下,IndexTupleData:
typedef struct IndexTupleData {
ItemPointerData t_tid; /* heap tuple 的物理行号 */
/* ---------------
* t_info 标志位内容:
*
* 15th (high) bit: 是否有NULL字段
* 14th bit: 是否有变长字段
* 13th bit: 访存方式
* 12-0 bit: 元组大小
* ---------------
*/
unsigned short t_info; /* tuple 的标志位 */
} IndexTupleData; /* 实际的index tuple数据紧跟该结构体 */
ubtree会在Index tuple后面再增加一个xmin、xmax信息:IndexTransInfo:
typedef struct IndexTransInfo {
TransactionId xmin;
TransactionId xmax;
} IndexTransInfo;
索引页尾定义如下:UBTPageOpaqueDataInternal:
typedef struct UBTPageOpaqueDataInternal {
BlockNumber btpo_prev; /* 左兄弟的块号,用于反向扫描 */
BlockNumber btpo_next; /* 右兄弟的块号,用于正向扫描 */
union {
uint32 level; /* tree level --- zero for leaf pages */
ShortTransactionId xact_old; /* next transaction ID, if deleted */
} btpo;
uint16 btpo_flags; /* 页面类型 */
BTCycleId btpo_cycleid; /* 最近的一次分裂的vacuum cycle ID */
TransactionId last_delete_xid; /* 记录页面上最后一次删除事物的XID */
TransactionId xid_base; /* 页面上的 xid-base */
int16 activeTupleCount; /* 对页面上的活跃元组的计数 */
} UBTPageOpaqueDataInternal;
INSERT 流程
下述的ubtinsert函数中仅保留了基本的执行流程,更多细致的处理读者可以访问社区server仓库的src/gausskernel/storage/access/ubtree/ubtree.cpp和src/gausskernel/storage/access/ubtree/ubtinsert.cpp查看更多实现细节。
Datum ubtinsert(PG_FUNCTION_ARGS)
{
*** //
itup = index_form_tuple(RelationGetDescr(rel), values, isnull, RelationIsUBTree(rel));
itup->t_tid = *htCtid;
/* reserve space for xmin/xmax */
Size newsize = IndexTupleSize(itup) + sizeof(ShortTransactionId) * 2;
IndexTupleSetSize(itup, newsize);
result = UBTreeDoInsert(rel, itup, checkUnique, heapRel);
pfree(itup);
PG_RETURN_BOOL(result);
}
函数的入口为 ubtinsert,构造出一个 IndexTuple 后进入 UBTreeDoInsert 主流程;
bool UBTreeDoInsert(Relation rel, IndexTuple itup, IndexUniqueCheck checkUnique, Relation heapRel)
{
*** //
itupKey = UBTreeMakeScanKey(rel, itup); // 构造一个 BTScanInsert 类型的scan key
*** //
if (!fastpath) {
/* 通过二分查找找到包含当前key的page。
* 查找方式是先找到根节点,在当前层通过UBTreeBinarySearch找到insert所需的节点,
* 并作递归。当找到的节点是叶子节点时,返回该节点。
* 这里会涉及到一个比较函数UBTreeCompare,它会先根据scankey作比较,
* 若未能判断大小,会根据TID做比较。*/
stack = UBTreeSearch(rel, itupKey, &buf, BT_WRITE);
}
*** //
if (checkUnique != UNIQUE_CHECK_EXISTING) {
CheckForSerializableConflictIn(rel, NULL, buf);
/* do the insertion
* 找到当前插入的位置
* 1. 校验插入数据大小是否小于页面的三分之一,
* 这个检验是为了保证每个页面可以插入至少三个数据
* 2. 检验unique,如果要插入的数据比当前的highkey的数据更大,
* 则需要将数据插入到下一个页面
* 3. 通过判断插入数据大小,确认是否需要prune,调用UBtreePagePruneOpt做清理
* 4. 通过UBTreeInsertOnPage将IndexTuple插入找到的位置*/
offset = UBTreeFindInsertLoc(rel, &buf, offset, itupKey, itup, checkingunique, stack, heapRel);
/* 将 IndexTuple插入找到的位置
* 1. 要插入的数据大于当前页面可用空间,需要进行分裂
* 1) 查找分裂点,选择分裂方式,均分或者根据插入点分裂
* 2) UBTreeSplit根据分裂点,分裂page,并将当前indextuple插入分裂点,记录xlog
* 3) UBTreeInsertParent更新父节点
* 2. 要插入的数据小于当前页面值
* 1) 判断是否为当前层的唯一节点,若是则需要保证fast root指向的层大于等于当前层
* 2) UBTreePageAddTuple将数据插入页面
* 3) 创建meta页,cbuf的标记,释放锁
* */
UBTreeInsertOnPage(rel, itupKey, buf, InvalidBuffer, stack, itup, offset, false);
} else {
/* just release the buffer */
_bt_relbuf(rel, buf);
}
*** //
return is_unique;
}
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
